
What We Learned from 200,000 OpenAPI Files
After attempting to collect as many publicly available OpenAPI Specification (OAS) files from the internet as possible, Assetnote—an Australian information security company—recently wrote a piece called “Contextual Content Discovery: You’ve Forgotten about the API Endpoints” and presented its work on a tool called Kiterunner at the 2021 BSides Canberra conference. You can also check out this PDF and the keynote video for more information. The project amassed nearly 200,000 OpenAPI files and spotlighted the critical role API specifications play in defining how APIs work and “exactly what HTTP methods, parameters, values, and headers are necessary to interact with APIs.”
Ultimately, the Assetnote archive provides us with a detailed view of the global API landscape, as exposed by publicly accessible OpenAPI documents. As Postman’s OpenAPI Specification lead, I recently spearheaded the Postman Open Technologies team’s analysis of the impressive collection of files. Today, we’re excited to present our initial findings based on earlier analyses of smaller datasets.
Assetnote’s process and findings
How did Assetnote’s team compile its dataset? First, they collected approximately 11,000 OpenAPI documents from GitHub using Google’s BigQuery framework. They then added around 3,000 more from the APIs.guru OpenAPI Directory project, which I happen to maintain.
Then, 10,000 more OAS documents were added from the SwaggerHub API, though this was substantially less than the full amount available. Why? Because you can run up against API rate limits when the needs of the consumer and the producer of the API differ.
Finally, 44,500 more API definitions were added by brute force scanning the web for likely URL endpoints at which OAS documents might be exposed. Assetnote focused on OpenAPI 2.0 definitions, possibly because of the larger base, but maybe ignoring the velocity v3.0 now has with newer APIs and more forward-thinking providers.
Assetnote reported initially having problems using an off-the-shelf OpenAPI parser (likely a Python or Go implementation) to validate the OAS documents, but they didn’t specify which tools were tried.
One conclusion Assetnote made after compiling the OAS documents for use in their Kiterunner tool was that “no one follows the spec” or, as they also put it another way, “developers are not to be trusted!” As someone who has handwritten an OAS validation library, I know all too well just how “inventive” authors of API descriptions can be. One thing we especially wanted to know: What percentage of the gathered OAS documents were actually valid according to the specification? We were really interested in the raw corpus of collected OAS documents.
A key piece of information absent from the publicly available data dump was the source URL each OAS document had been retrieved from. Assetnote Co-founder and CTO Shubham Shah came through promptly with that missing piece of the puzzle, which allowed us to fully analyze the collection.
One big dataset to answer some big questions
The total size of the web scrape Assetnote conducted was just over 250,000 pages. From these, we extracted approximately 178,000 identifiable OpenAPI documents. With additional sources of documents thrown into the ring, we had almost 194,000 files to process.
So, what can nearly 200,000 API definitions tell us? And how many are concerned with the retailing of small domesticated animals (the ubiquitous SmartBear “PetStore” example)?
The first question we had to address was: What do we want to know? Luckily, in May 2016, Erik Wittern analyzed the contents of the APIs.guru collection (which was a mere 260 API definitions at the time). Could we repeat, and maybe expand upon this analysis? It turns out that, yes, we could.
Additionally, in 2017, I conducted three pieces of analysis of my own over a collection of API definitions from GitHub, SwaggerHub, and APIs.guru—looking at specification extensions, the content of the <a href="https://spec.openapis.org/oas/v3.1.0.html#data-types">format</a> keyword, and sibling properties of the <a href="https://spec.openapis.org/oas/v3.1.0.html#reference-object">$ref</a> keyword. Let’s add an update of that analysis to the mix too.
Postman’s analysis methodology
In order to produce a final 108Mb SQLite3 database summarizing our findings, Postman Open Technologies used a t2.medium AWS EC2 instance and a Node.js script.
Four different text parsers were required to ingest all the various documents (and we still had many failures regarding what was presumably supposed to be valid JSON or YAML): the standard JSON parser, two competing YAML parsers (one known to be very standards-compliant, and one much more relaxed), and a hand-crafted “lenient JSON parser” that (with a bit of surgery) tried to cope with issues like comments, dangling commas, and incorrect quoting.
Some of the retrieved files were actually HTML pages, such as Swagger-UI or 404 pages. These were never going to be able to parse into an OpenAPI document, so they were ignored.
We then output the following columns for each API definition:
Most columns are probably self-explanatory, being counts of things like path keys, GET operations, schemas, etc. We also computed a hash of a normalized version of the input for de-duplication purposes, stored the resultant size of the definition in bytes and lines of YAML, did a reverse DNS lookup of the source IP address, and tracked whether the input API definition was valid (and if not, could it be automatically repaired by correcting for a number of common authoring errors). For the webhooks column, we also counted the x-webhooks specification extension supported by some tools for OAS 3.0, like ReDoc, as webhooks is a very new feature only supported officially in OAS 3.1.
We also used the host/server URL of the API to look up the ranking of the provider in the Alexa list of top one million domains. We can use this to prioritize looking at APIs which are new to us but are associated with high-volume, high-net-worth sites.
Our key discoveries
Here are Postman’s key discoveries after analyzing nearly 200,000 OpenAPI files:
- Most OpenAPI documents don’t include license information, but when they do, the most common licenses, listed in order, are: Apache 2.0, AGPL 3, Creative Commons Attribution 3.0 and the BSD license.
- 79% of the API definitions were valid according to
oas-validator. - API enthusiasts aren’t spammers. Otherwise I’d get far more junk email from being the second-most commonly included contact email address, after [email protected].
- Just over 6% of the APIs include a logo URL in the
x-logoextension property, as popularized by ReDoc and APIs.guru. - Approximately 2% of APIs have a publicly available
/statusendpoint. - Nearly 4% have a
/healthcheckor/readyendpoint, likely related to this IETF Internet Draft. - Although it may seem like it’s more, only 2% of OpenAPI definitions in the wild are PetStore related.
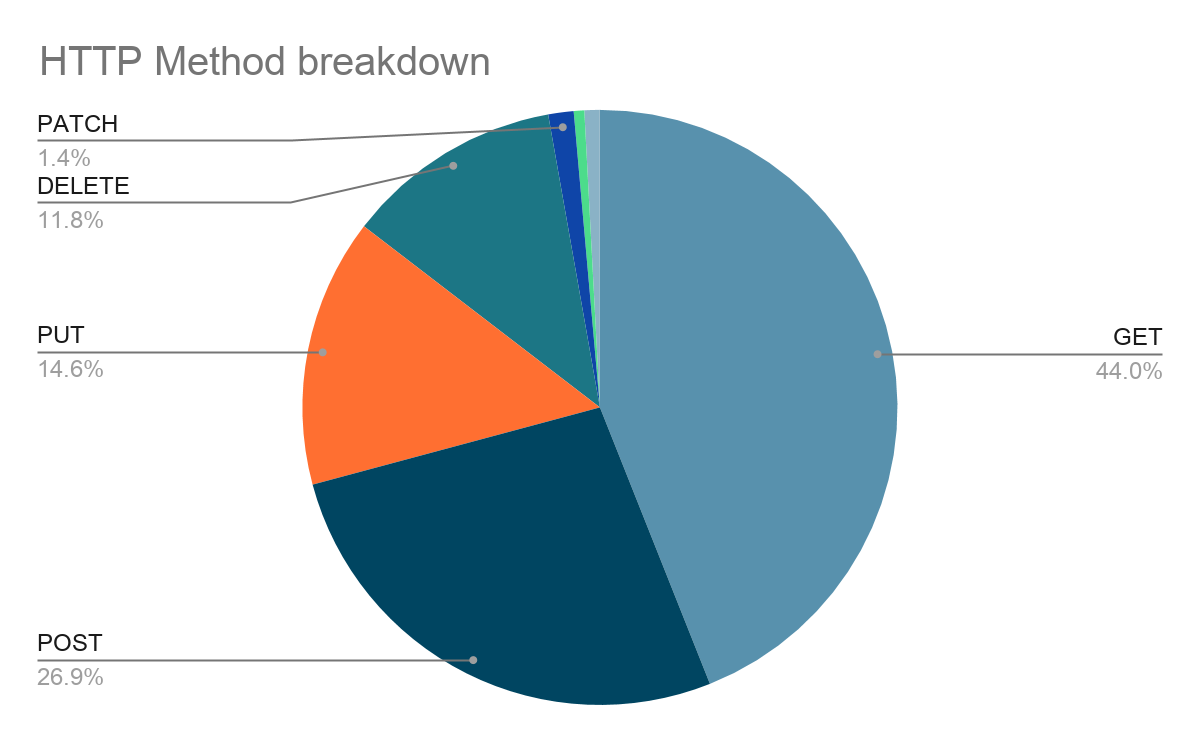
- Each API has, on average, 37 paths.
- Each API has, on average, 51 endpoints (or 1.4 methods per path item).
- Each API has, on average, 38 distinct query parameters across all operations.
- Each API has, on average, 33 schemas defined, or 0.65 schemas per operation.
- 1,485 APIs, or 0.8%, use the
discriminatorkeyword. - 3,253 APIs, or 1.7%, use the
xmlkeyword. - The combination of
basicand/orapiKeysecurity is most common, followed by no security,apiKeysolo,basic,oauth2,oauth2and/orapiKey, and otherhttpmechanisms. - Just three APIs used the new
callbacksfeature of OpenAPI 3.0—though this low figure is probably due to the sample’s limited inclusion of v3.0 definitions. - We could not find any APIs using the new ‘links’ feature of OpenAPI 3.0—though this may have been limited by the sample’s focus.
- Despite looking for the
x-webhooksextension used by ReDoc, we found no APIs using the newwebhooksfeature of OpenAPI 3.1, but adoption of this very new version of the specification would be expected due to its infancy.
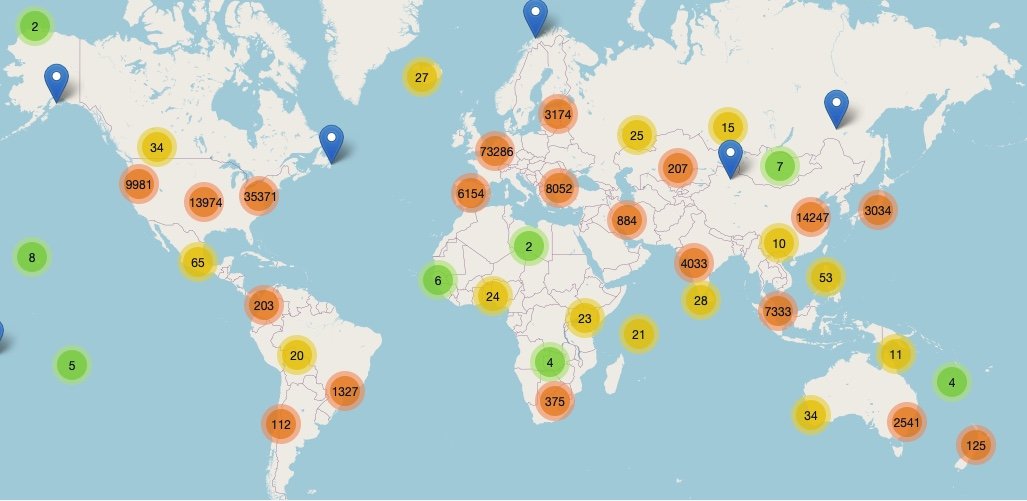
Augmenting the data
Adding latitude and longitude from the MaxMind GeoIP database allowed us to render a dynamic map using the cluster map plugin of Datasette, so we were able to see exactly where these APIs are in the world. The dominance of Western Europe may be due to the use of load-balancers and the fact that I ran the DNS lookups from the United Kingdom.
With this map, we can zoom in to identify datacenter “hot spots,” or even individual API locations:
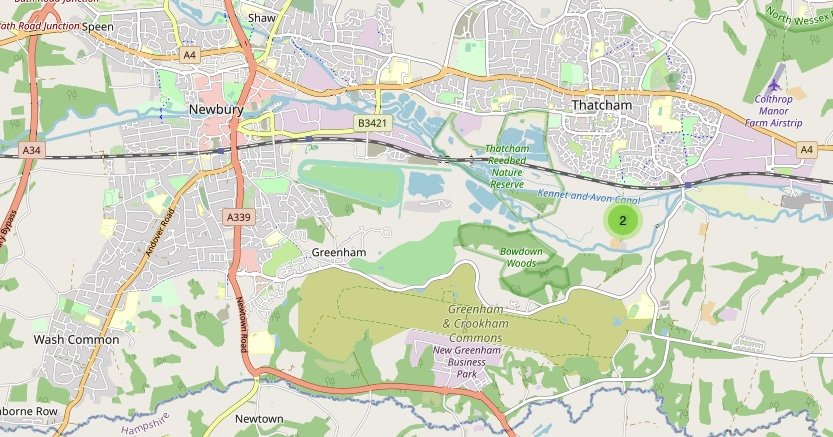
For example, I found the nearest API to me in the UK turns out to be an exposed Ubiqiti Network Management System (UNMS) appliance:
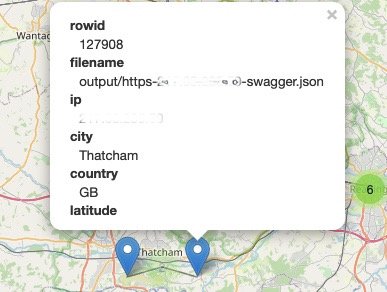
We’re not done yet
Assetnote’s treasure trove of specification files can provide us with a wealth of information about how API producers communicate around their APIs and highlight those API providers who have yet to embrace OpenAPI in the open. We learned a lot by being able to ask questions from the OpenAPI archive, and we are confident that there are many more questions to be asked.
Moving forward, Postman Open Technologies will be aggregating all of our questions while also thinking more about how we encourage the API producers behind many of these APIs to publish their OpenAPI and Postman Collections to a public workspace in the Postman Public API Network. This way, producers can keep their OpenAPI up to date, and Postman’s 17 million developers and the Postman team can continue asking questions about industries, regions, and the other dimensions of the API economy that matter the most.
If you have any questions you’d like us to address as we continue analyzing the world’s public OpenAPI files, feel free to comment below and we’ll do our best to find the answers.


Hi Mike
fascinating results. Can we have a list of all public providers? It would be interesting to know if our company was in the data and how we can improve.
Hi Jeremy,
yes, we’re still working on the best way to be able to report or provide access to this data, but feel free to DM me on Twitter (@PermittedSoc) and we can have a look.
Which is preferred format Json or Yaml ?
What are most popular standard Http headers apart from Authorization and Content-type ?
What are most popular standard Http status code apart from 400, 403, 404 and 500?
Excellent work Mike. It encourages me that I have a place to post some of my more esoteric api’s in the knowledge that they will be useful to someone. Mostly related to healthcare and finding someone who can care, all the way to translations of Buddhist texts from Chinese to English.
Definitely should be publicly available.
Excellent article. Thanks for sharing. Please let us know if you decide to share your dataset. There is at least one interesting resource that you can use to enrich your dataset. See what the cybersprint team did in 2020 https://www.cybersprint.com/blog/swagger-api-discovery-of-api-data-and-security-flaws. Maybe it will interest you.