Using AI tools like ChatGPT to control IoT lights
On a recent livestream, I had the pleasure of hosting Postman’s Jan Schenk and Saswat Das to talk about how we used several layers of AI tooling to control some Internet-of-Things (IoT) lights. I had previously done a livestream with Saswat about how we built Postman Flows, as well as another IoT/Flows livestream with Jan, Joyce, and Arlemi.
Flows is Postman’s visual programming language, and it allows non-developers to combine Postman Collection requests to automate some really great interactions.
In our previous IoT livestream, Jan showed off a panel of IoT lights, designed from scratch, and wrote an API to control the addressable lights into patterns of almost 400 “pixels” within a rectangular image.
I’ve done some work in the past on sentiment analysis tooling using IBM Watson, but I wanted to explore other technologies, and I landed on Microsoft’s Azure Cognitive Service. Since we wanted to use Flows in this livestream, I turned again to Saswat from the Flows team, who chose OpenAI’s ChatGPT as the API of choice.
What followed was the result of some brainstorming of how we could ask a question of the ChatGPT tool, run its answer through Azure’s sentiment analysis, and use the results to control Jan’s IoT light panel.
Jan got to work programming several “reaction” images for positive, negative, and neutral results, while Saswat and I worked on building collections for our respective API choices. We used a team workspace to combine all of our work, but because of the private nature of API keys, we cannot share it. We will instead share screenshots of the workspace and explain how we accessed each API.
Getting started with OpenAI’s ChatGPT API
Related: Use Postman’s ChatGPT API collection
Saswat signed up for an OpenAI account, which offers a generous usage quota for free access to their trained ChatGPT service. ChatGPT uses years’ worth of training data to answer questions, give inspiration for blog posts or video ideas, or help with code samples (though you’ll want to avoid using these code samples in professional environments because of licensing and copyright concerns).
OpenAI’s quota allows for $18 of free usage to generate “tokens” in a ChatGPT response, where a token is analogous to a single outputted word. For example, writing a 1,000-word essay would use up approximately 1,000 tokens. One thousand tokens costs about 4/100ths of a single USD penny ($0.0004), or about 25,000 tokens per penny. OpenAI’s $18 of free usage equates to approximately 45 million tokens. There are, of course, settings and options that will affect the exact token count of any request, but it’s still a very generous quota.
OpenAI provides extensive help and documentation for using their API, and Saswat quickly got a single POST request into a collection for this portion of the project (Postman also has an OpenAI API workspace, if you’d like to get started quickly). Saswat built the collection request in such a way that an input variable called prompt would hold a question that would be sent to OpenAI. OpenAI’s API would take a few moments to generate an answer, and we could also provide a maximum number of tokens to “spend” on the response. In this case, we set the output to be 120 words, after determining that ChatGPT would break the response into several sentences.
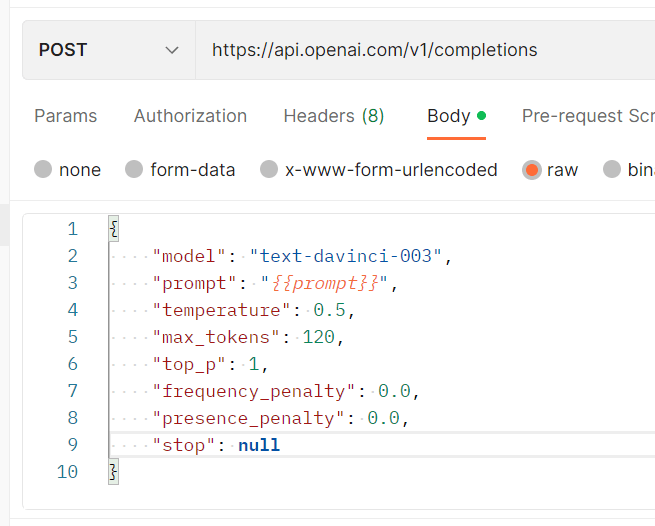
We began by asking questions of the API, such as “tell me about the Python programming language,” to see what the response would look like and figure out where to find the resulting text in the output.
Azure’s Cognitive Service for sentiment analysis
Sentiment analysis is another interesting AI-powered tool that takes the grammar and syntax of a language and uses it to determine the meaning of a block of text. During this analysis, a range of “sentiments” is examined, and each portion is given a score. Every sentiment tool is a little bit different, but Azure’s default settings give a score for “positive,” “negative,” and “neutral” sentiments on a scale of 0.0 to 1.0 (think of it like a percentage from .05 to 100%).
Getting started with Azure requires you to create an account and give your billing information to Microsoft, but it provides a generous free quota before you are billed. At present, you can analyze 5,000 pieces of text on a monthly basis for free, and then pricing ranges by volume. The next 500,000 text reports cost $1.00 per 1,000 reports, and from 500,000 to 2.5 million text reports, the cost will be $0.75 per 1,000 reports.
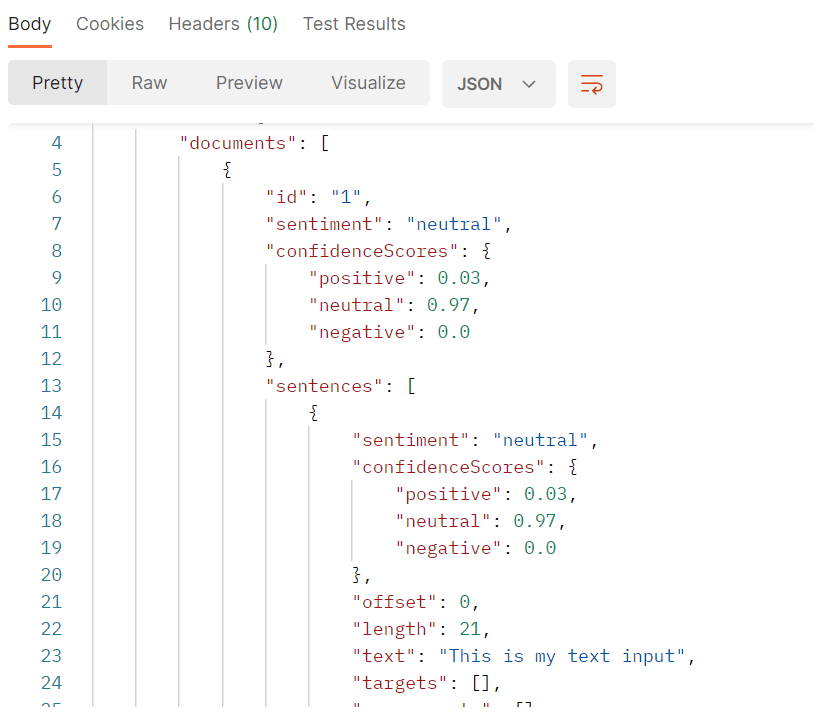
The API itself is pretty straightforward. You pick a region (in my case, I chose Central US), and you are assigned a specific regional endpoint URL and provided an API key. The body you send to Azure allows for an array of documents, but we were only sending a single document, which you can see in the screenshot below. We would later replace “This is my text input” with a variable called textInput.
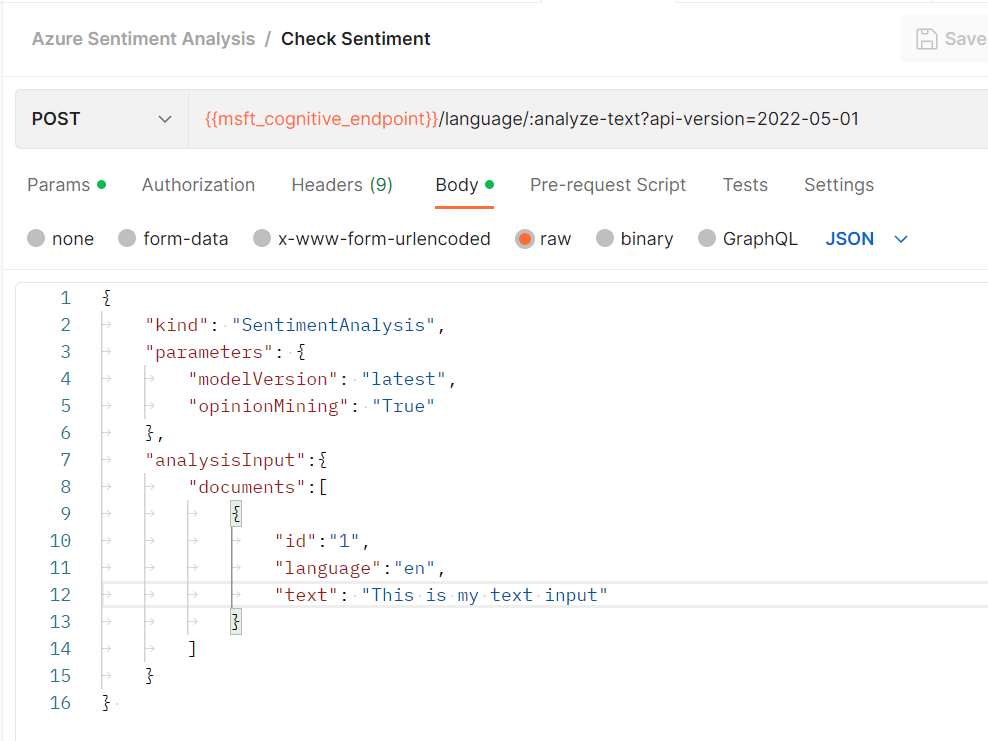
While the example above only has a single sentence in the text instruction, that field is where you would typically include an entire document, and it is where we put the entire ChatGPT response. These responses were typically five to seven sentences long, and they used our 120 (maximum) tokens of output.
The result from Azure would be an analysis for each document, an overall set of scores for “positive,” “neutral,” and “negative” sentiments, and a sentence-by-sentence breakdown where each sentence is given its own set of scores (Azure would take a whole document, and return it sentence by sentence). Ultimately, we wanted to loop over each sentence score to send a request to Jan’s IoT lights, and then send a final request to the lights with the overall sentiment score from Azure. For instance, if a block of text had five sentences, we would send one request for each sentence’s sentiment to Jan’s lights, followed by a sixth request based on the overall sentiment.
Controlling IoT lights around the world
Jan is based in Europe, Saswat is on the west coast of North America, and I’m approximately in the middle of the United States in Colorado. We weren’t too worried about latency when sending requests to Jan’s lights, but a straight shot from Colorado to Jan in Europe is about 5,000 miles. Even under perfect conditions, it would take data traveling at the speed of light about 30 milliseconds to reach Jan’s home. Because of the way the internet works, my ping from Colorado would take about 200 milliseconds on average to reach Jan, plus the time for his system to receive the request, calculate a light pattern, and send an instruction to his light panel.
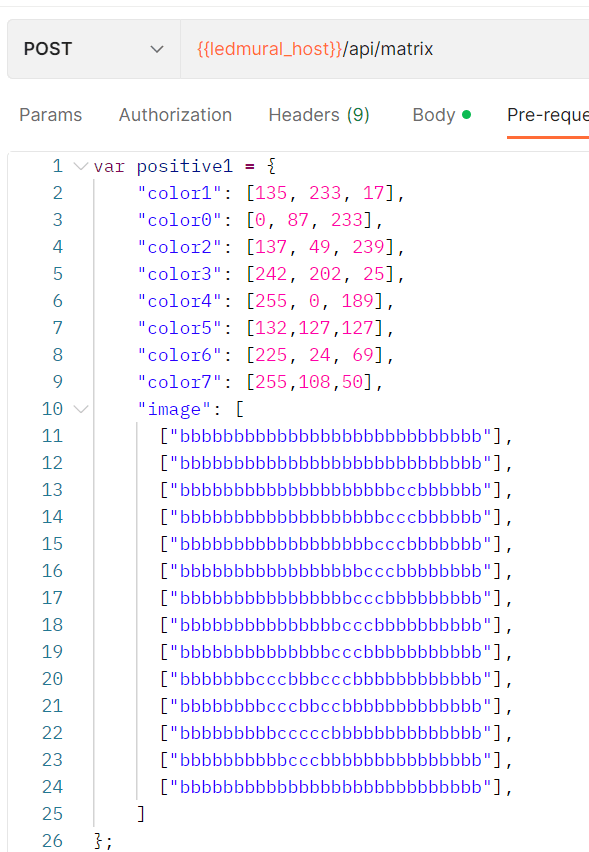
Jan built a very clever 14×28 panel of addressable LED lights in a rectangular arrangement, where each LED “pixel” could be set to a specific RGB color.

Jan designed and built an API that would allow his lights to be controlled using a set of RGB colors and an “image” matrix based on those colors. For example, in the screenshot below, Jan uses the letters “b” and “c” in his matrix to map to “color 1” and “color 2” (programmers sometimes start counting at 0).
Postman Flows was introduced in 2022. We’ve shown it in videos and live workshops, and the team continues to expand its capabilities with its own use of AI.
Flows is a visual tool developed by Postman to create chains of “blocks” for a piece of an overall sequence of events, each of which is an instruction of some sort. While many companies use visual tools like this and call them “no code,” we are careful to point out that some amount of coding will be beneficial, such as “if/else” statements and “loops.”
Each block in a Flow has a purpose: input, output, or both. A block can perform a task, manage a data value, or run a logical operation.
What we wanted to do with our project was to create a simple way to input a question, send it to ChatGPT, get an answer, run that answer through Azure’s sentiment analysis, and then send instructions to the IoT lights for each sentence’s sentiment, plus a final instruction for the overall analysis. We’ve made this Flow publicly available, but you would need to configure your own ChatGPT, Azure Cognitive Service, and IoT setup.
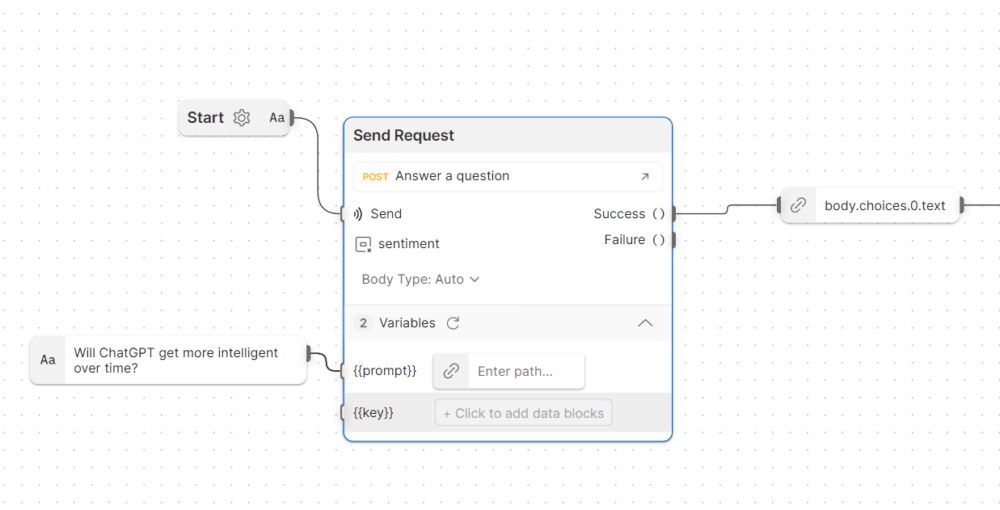
The first step was calling ChatGPT with a Send Request block—and adding an input block for our prompt variable. If that was successful, then we wanted to extract the text from the body of the response that we see as body.choices.0.text. Flows makes it straightforward to navigate through data structures of content to find what you’re looking for, but the new AI-powered FQL will make this even faster and easier for non-developers.
Next, we had to send the output from ChatGPT to our textInput variable for our sentiment analysis, which is in another Send Request block. When this request succeeded, we wanted to perform two operations, which we’ll discuss next.
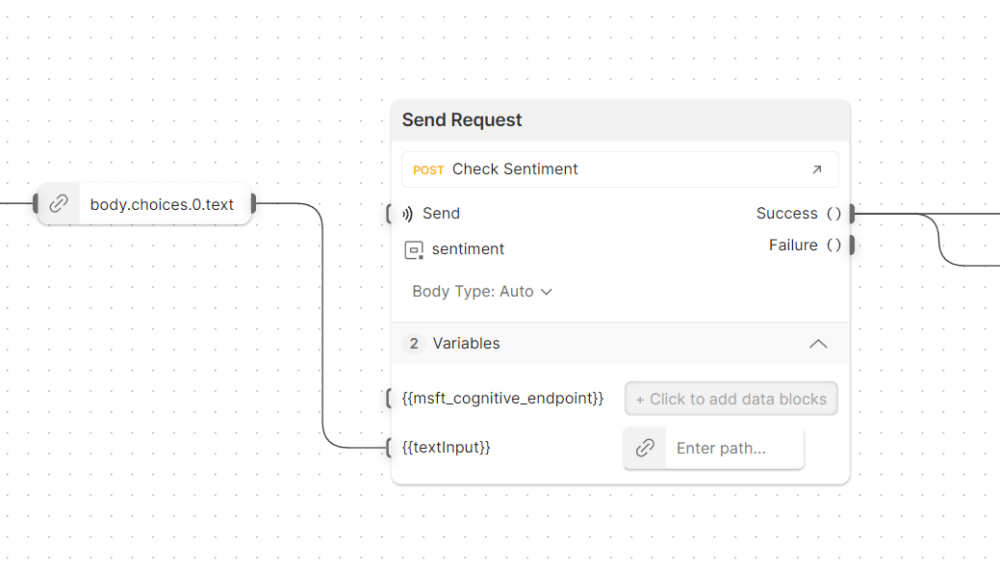
As mentioned above, we would receive a single response from Azure with the sentiment analysis, but we wanted to do two things with that response. The first operation we wanted to perform was to store the overall sentiment for our very last step. The second operation was to loop over each of the sentences in the sentiment analysis and send the results to Jan’s IoT lights.
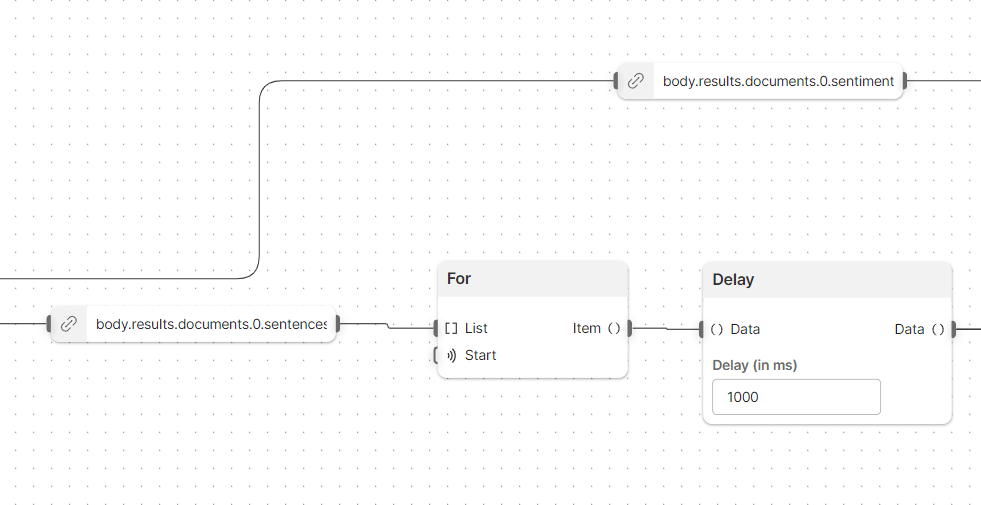
The third step of our process was to introduce a small, one-second delay between each request to change the IoT lights. That way, we could visually see things working. Each sentence had its own Send Request block. We also added some logging of the sentence and its sentiment for debugging purposes, using the Log blocks at the bottom of the screenshot below. The Collect block is how Flows will end the loop to allow us to continue doing more work once everything is “finished.”
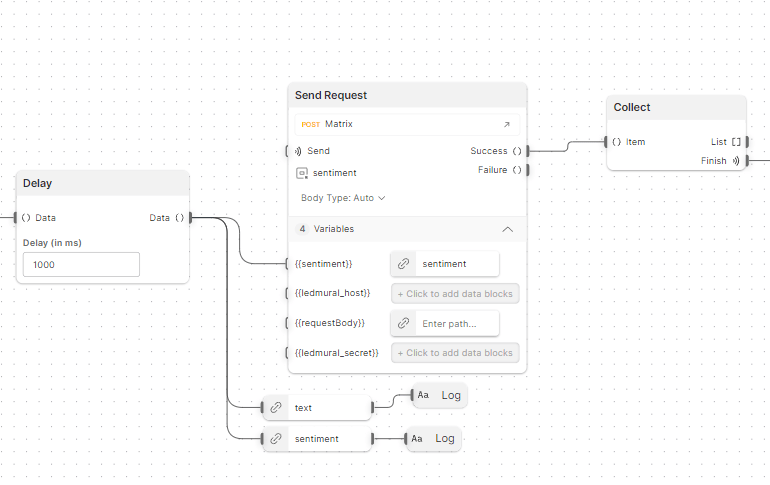
Finally, once the Collect block signaled that the loop was finished processing each sentence of our ChatGPT response, we took our overall sentiment (found in our sentiment analysis as body.results.documents.0.sentiment) and sent one last request to our IoT lights.
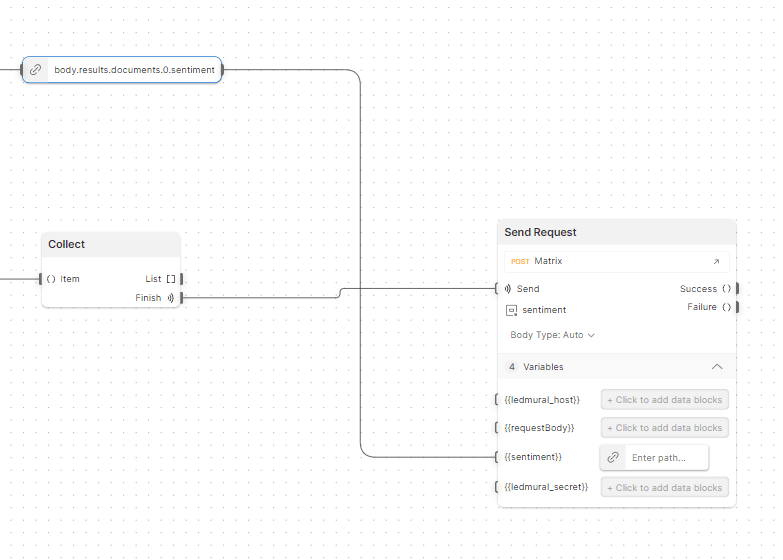
Our process did need some debugging (which we did live, in front of everyone) to show how teams can work with a Postman Collection and Flows together in real time. This debugging process helped us realize we were not always sending the sentiment to Jan’s lights properly. Once we found the bug in our process, we were able to let the artificial intelligence of OpenAI’s ChatGPT battle it out with Azure’s Cognitive Service analysis to determine if ChatGPT would get smarter over time:
Our team does a livestream each Thursday at 8 a.m. Pacific/11 a.m. Eastern time on YouTube, Twitch and LinkedIn, and we love to have folks from around the world join us in the chat to participate and ask questions.



What do you think about this topic? Tell us in a comment below.