
Serverless architecture and the feasibility of serverless APIs
The idea of serverless architecture has garnered attention in the tech world due to its ability to simplify deployment, reduce costs, and scale applications efficiently. But what exactly is serverless, and how does it fit into the modern software development landscape? Let’s delve into serverless, walk through its mechanics, and address its feasibility for API development.
What is serverless computing?
Serverless computing, often just called “serverless,” is a cloud computing model that allows developers to build and run applications without managing the underlying infrastructure. It was brought about a long time ago with peer-to-peer networking, but the infrastructure we commonly see today was introduced in 2014 at AWS:reInvent. Many cloud platforms have since followed in offering something similar to users.
Despite its name, servers are still involved, but their management is abstracted away, leaving developers to focus solely on code. Serverless providers—like AWS Lambda, Google Cloud Functions, and Azure Functions—handle the details of infrastructure management, scaling, patching, and other tasks that would be otherwise left to your company’s DevOps team.
How serverless functions work
A serverless function, sometimes known as a “Function-as-a-Service” (FaaS), is a discrete piece of code that executes in response to an event. This event can be an HTTP request, a database change, or even a scheduled task. Once triggered, the cloud provider instantiates a container to execute the function. This container keeps this code and its memory safe from other serverless functions that other users are running on the same physical hardware. The container is destroyed once the code is finished executing, which ensures that resources are consumed only when necessary.
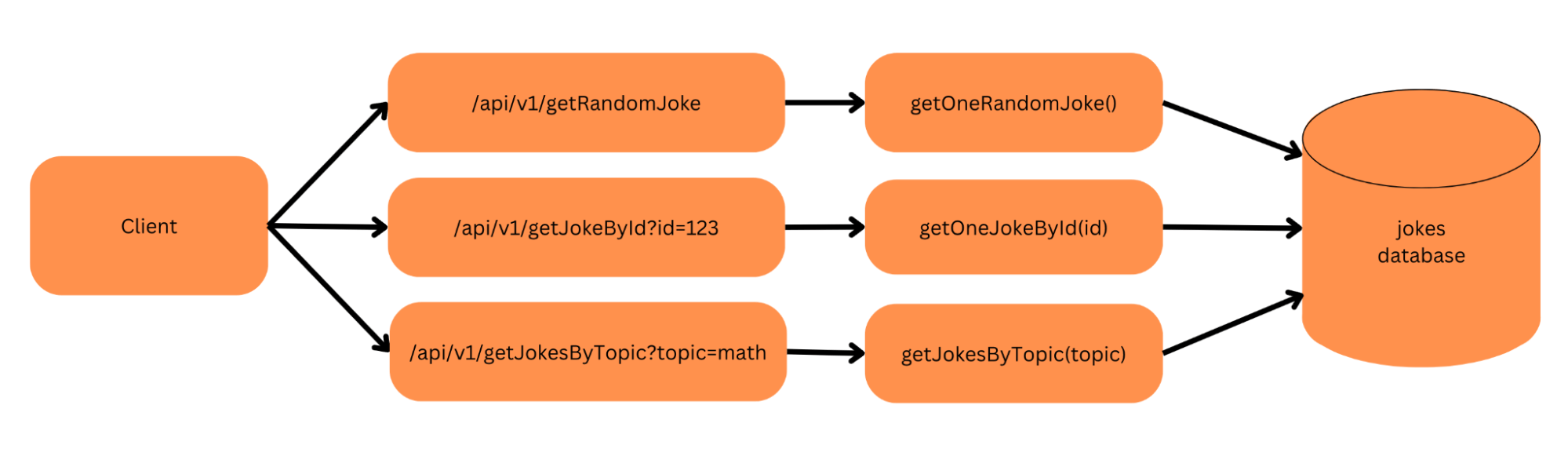
The above diagram shows an example of a serverless API with 3 endpoints: one that requests a random joke, one that requests a particular joke by its ID value, and one that finds jokes based on a topic, in this case “math.” (Not all math jokes are funny, just “sum” of them.) Each of these API endpoints corresponds to its own serverless function, such as getOneRandomJoke, and may pass parameters. Each of these functions may also interact with a common database.
The infrastructure of serverless
The underlying infrastructure of a serverless environment typically consists of:
- Event listeners: These listeners monitor and trigger functions based on specific events.
- Function orchestrators: Orchestration manages the lifecycle of a function, including instantiation of the container, execution, and termination.
- Resource allocators: Infrastructure is needed to allocate necessary resources, such as CPU, memory, and network bandwidth.
The beauty of this architecture is its dynamic nature. Resources are allocated on-demand, ensuring efficiency and cost-effectiveness. This approach isn’t as fast, however, as having a full-time server running your application, since the containerization and post-execution cleanup needs to happen more frequently.
The primary benefits of serverless
Serverless offers many benefits over other architectural styles, such as:
- Cost efficiency: With serverless, you only pay for the compute time you consume. There’s no charge when your code isn’t running. This requires your application to be minimized into a single piece of code, but your developers don’t need to worry about building on a framework and dealing with library versioning as much.
- Automatic scaling: Serverless functions scale automatically by spawning multiple instances as needed. Many cloud providers can also run these containers in a more geographically disperse way, launching your application closer to your user. This can minimize latency and improve the overall user experience.
- Operational management: Infrastructure management, maintenance, and updates are handled by the cloud provider, freeing up your teammates’ time to manage other critical pieces of infrastructure.
- Quick deployments and updates: With no infrastructure to manage, deployments are quicker and easier. Each endpoint is its own separate function or method, minimizing and simplifying code maintenance.
Drawbacks of serverless
No technology is perfect, and there are benefits and disadvantages to many aspects of the applications we develop. Serverless is no exception. Here are some of the primary concerns you may have when working in a serverless architecture:
- Cold starts: The first invocation of a function after some idle time may experience a latency spike. Cloud providers may archive your software between long pauses in the use of your code, and only have it at-the-ready when a certain amount of traffic is realized.
- Resource limits: There are restrictions on execution time, memory, and size of the application and supporting code. Serverless functions can run in the background, but generally have limits of 30-60 seconds before the cloud infrastructure terminates the process. You could also experience limits on the amount of RAM your application can use, and may be limited in the amount of code you can upload per function.
- Debugging challenges: Traditional debugging tools may not always be applicable. When you run your application in a local environment, debugging is often easier. When deployed, the most common debugging tool is logged data. This often means the developer is adding several lines of code to log a “trace” of where execution has taken place in order to understand how a bug has affected performance.
- Duplication of effort: When each endpoint is its own block of code, it can sometimes lead to duplicated code in infrastructures where you cannot easily add shared library code.
- Vendor lock-in: Migrating to another provider may require significant code changes—especially if you are utilizing vendor-specific storage, databases, or APIs.
Building serverless APIs: feasible or fantasy?
Building an API with serverless functions is not only feasible but has become increasingly popular. APIs often have variable loads, with peak usage times and lulls. The on-demand scaling of serverless is a perfect match for this.
Some benefits of building an API using serverless architecture include:
- Granular scaling: Each endpoint can scale independently, based on demand.
- Reduced costs: No idle servers means no wasted resources.
- Faster iterations: Developers can quickly deploy endpoint changes without affecting the entire API.
However, challenges can occur that need to be considered:
- State management: Serverless functions are stateless, which means that certain operations are trickier to implement.
- Complex architecture: Larger APIs may require numerous functions, making the organization of the API more complex. The user experience of the API should be heavily considered with your API governance team.
- Tooling and monitoring: Traditional tools might not cater to serverless environments, necessitating new solutions. Your cloud provider may have tooling for this, but using it will increase your vendor lock-in, as described above.
The primary drawbacks of building a serverless API include increased latency and limited customization. While serverless is generally fast—and often gets faster as cloud providers automatically scale up your application—serverless functions can experience “cold starts,” which introduce latency if there has been a sufficient enough “lull” to archive your application. You can keep your application “awake” by calling the functions yourself on a timed basis, but the extra expense you incur could exceed that of running a dedicated server. Deep customization at the infrastructure level might be limited as well, depending on the offerings of your cloud provider. This means that your team might not be able to build out everything the API needs in order to satisfy all users and business use cases while minimizing costs.
How Postman can help your serverless design
Developers can construct a collection of requests in Postman to call each of their endpoints—and test that their responses are correct. Additionally, our API performance testing feature sheds light on how it can sometimes take a while for a serverless API to “wake up” and then get faster over time as your cloud provider provisions more containers.
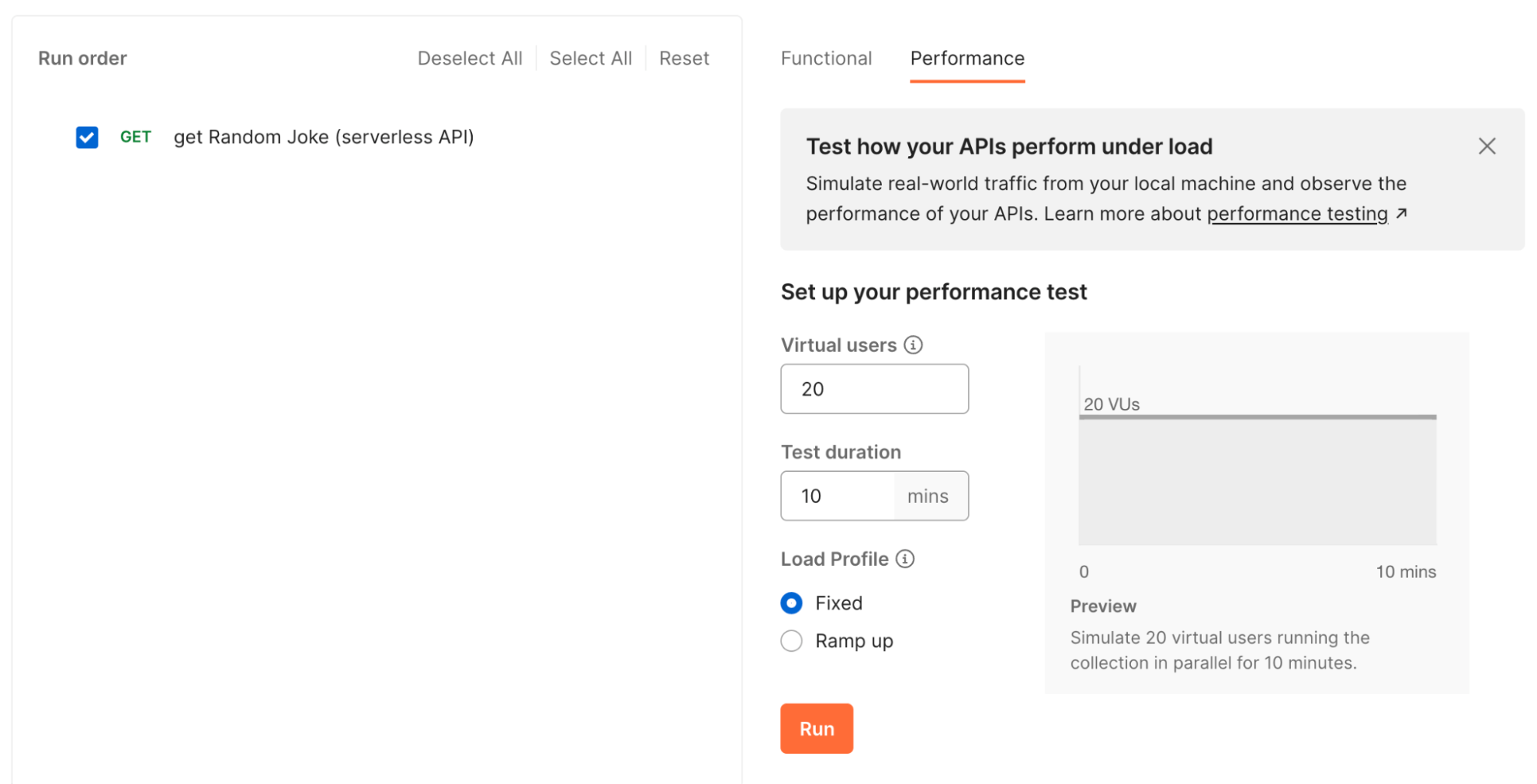
Postman’s API performance tests will use your computer’s resources to have several “virtual users” access your API endpoints. They will also plot the average times needed to access the API and perform its work. The diagram below shows how a serverless function can sometimes take a few minutes to realize it’s under load, but it will eventually normalize to give end users faster access. In this case, it took our serverless architecture about 20-30 seconds to normalize from an average response time of two full seconds when first launched to an average of about 400ms:
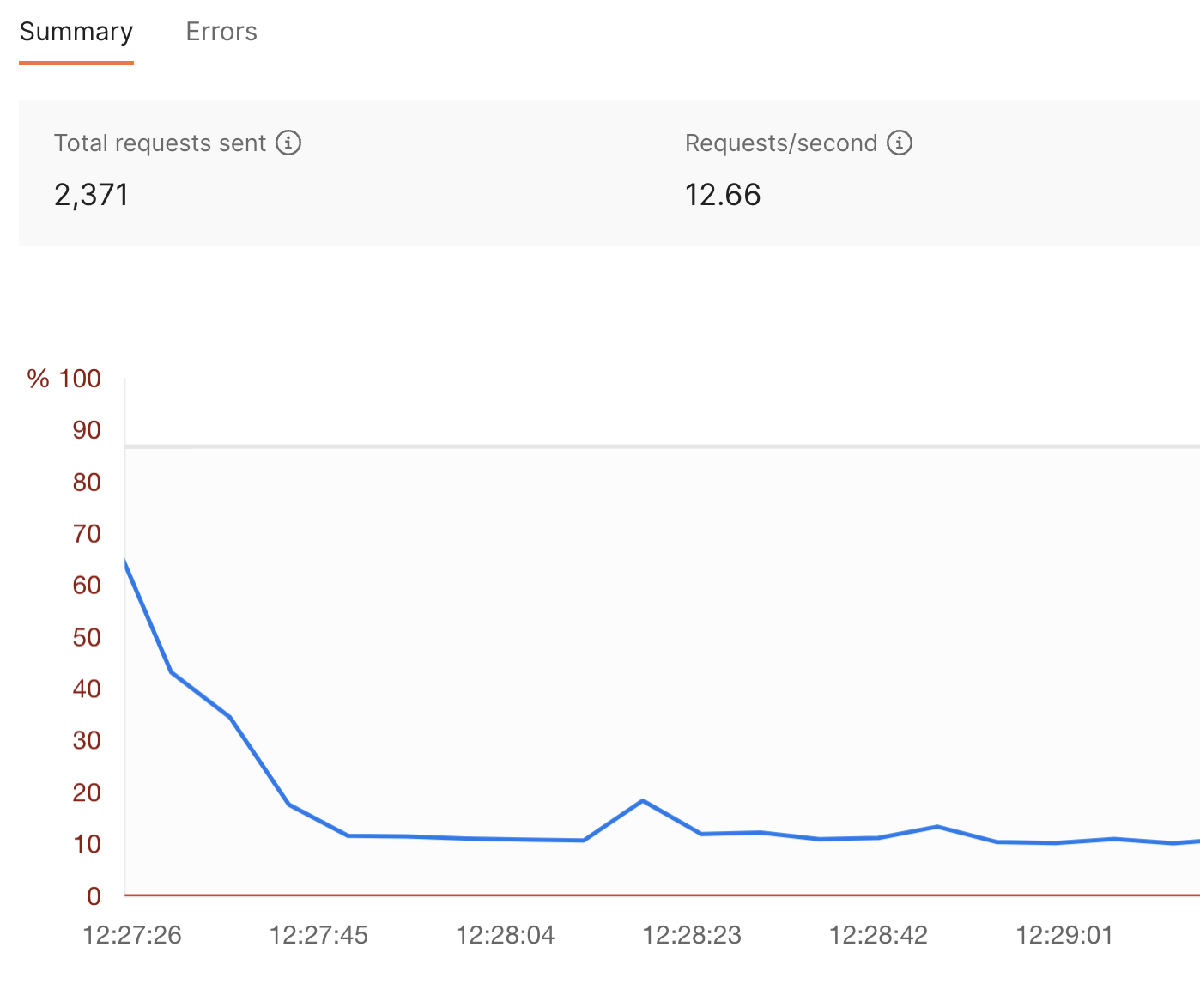
Your developers can also use snippets to add test code that will verify whether a response comes back within a certain amount of time. These tests will fail if your serverless architecture takes too long to respond, helping your team identify which endpoints are slow so they can debug any underlying issues.
Conclusion
Serverless computing has reshaped the cloud landscape in many ways. The dynamic nature of API workloads makes serverless an attractive option for API development. Oracle Cloud, for example, has a public collection for its Vision API to identify objects in an uploaded image. Coca-Cola rolled out serverless architecture for 10,000 soda fountain machines in 150 days during the COVID-19 pandemic allowing customers to use QR codes to dispense drinks.
As with any technology, understanding the nuances of serverless is important. Developers need to be aware of potential pitfalls, but with the right strategies, serverless can offer a powerful and efficient approach to building robust APIs. It’s important to understand resource limits, customization, vendor lock-in, and security when balancing the faster development and deployment of a serverless API.
Technical review by Joyce Lin.


Hi Ian,
Excellent article. Thanks! One note: endpoints on the How Serverless Functions Work diagram should contain only nouns (RESTful style compliance) :-).