
Kubernetes Tutorial: Your Complete Guide to Deploying an App on AWS with Postman

Kubernetes is an open source system that is useful for container orchestration. In this tutorial, we are going to use Postman Collections to learn Kubernetes and use its API to deploy an app on a Kubernetes cluster hosted on AWS.
This is a hands-on tutorial. Don’t fret if you aren’t familiar with Kubernetes and containerization, because we’ll go over each of the following:
-
- Prerequisites
- Brief overview on containers
- Kubernetes
- Creating a Kubernetes cluster
- Accessing the Kubernetes API from Postman
- Authorizing Postman Collection
- Deploy an app
- Pod
- Deployment
- Expose your app
- Service
- Clean up
- What next?
Note: We will be creating the Kubernetes cluster on AWS EKS, but you can also follow the tutorial with a cluster hosted on any other cloud providers or locally using Minikube.
Prerequisites
Familiarity with REST APIs is a prerequisite. In addition you also need to do the following:
- Create an AWS account
- Install and configure AWS ALI to configure credentials
- Install eskctl,a command utility to interact and create the cluster on EKS
- Install kubectl, a command-line utility to work with Kubernetes clusters
- Clone Github repository containing .yaml files required in upcoming sections
- Create your Amazon Cluster IAM role to access the cluster
- Setting up Amazon EKS cluster VPC
Here is a helpful Amazon EKS guide that has all of the prerequisites mentioned above and instructions to install them.
Explore this blog post in an interactive format by using our companion template. Just import the Deploy with Amazon EKS and Kubernetes API collection by clicking on Run in Postman to follow this tutorial.
![]()

A brief overview of containers
Are you familiar with the “But it works on my machine” problem? A lot of times your application doesn’t perform as it does in your local environment. It may be because the production environment has different versions of the libraries, a different operating system, different system dependencies, etc. Containers provide you with a sustainable environment because your application now runs in a box (container) that includes all dependencies required by your app to run and is isolated from other applications running in other containers. They are preferred over virtual machines (VMs) since they use operating system-level virtualization and are lighter than VMs. Docker can be used as the container runtime.
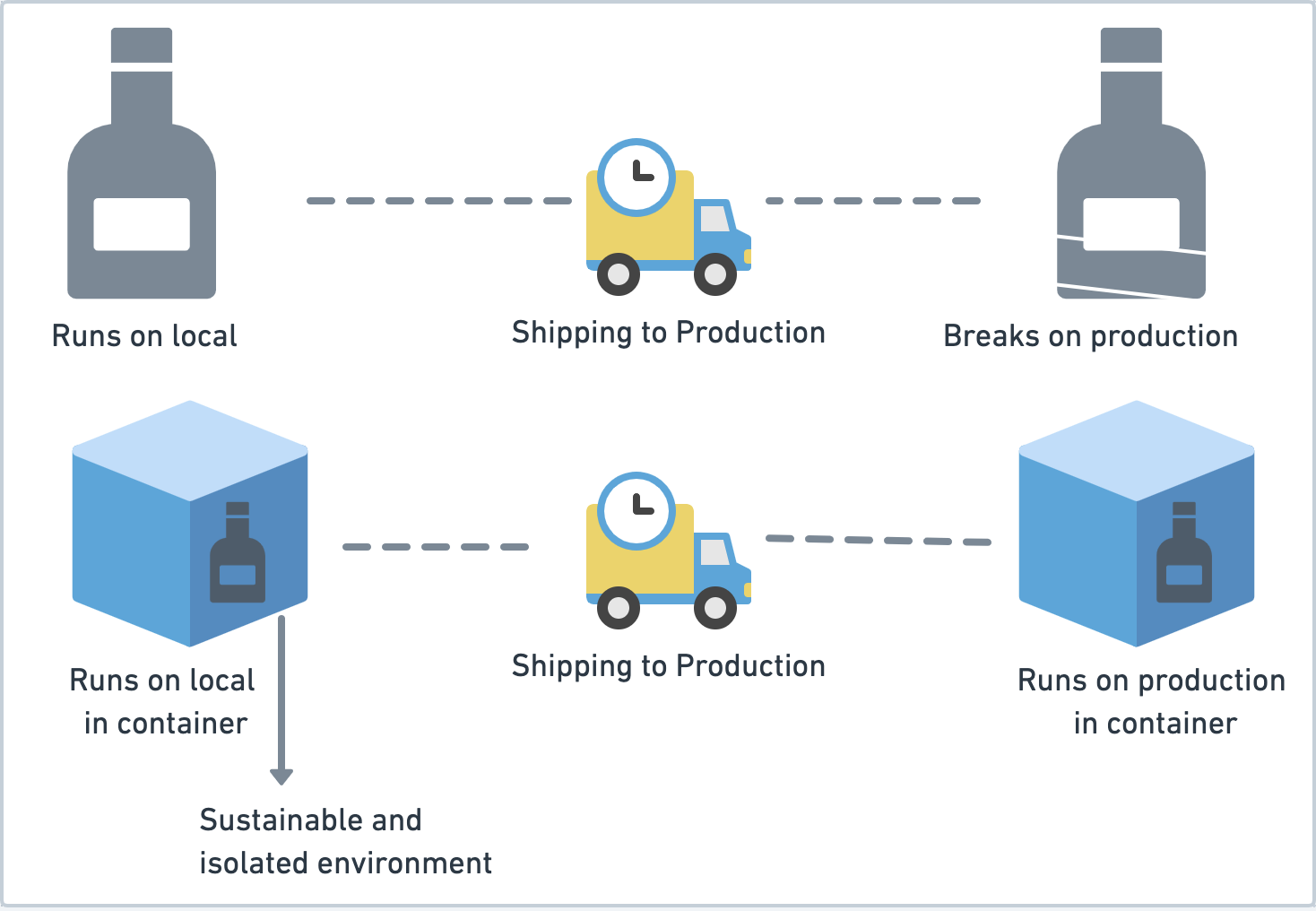
Enter Kubernetes
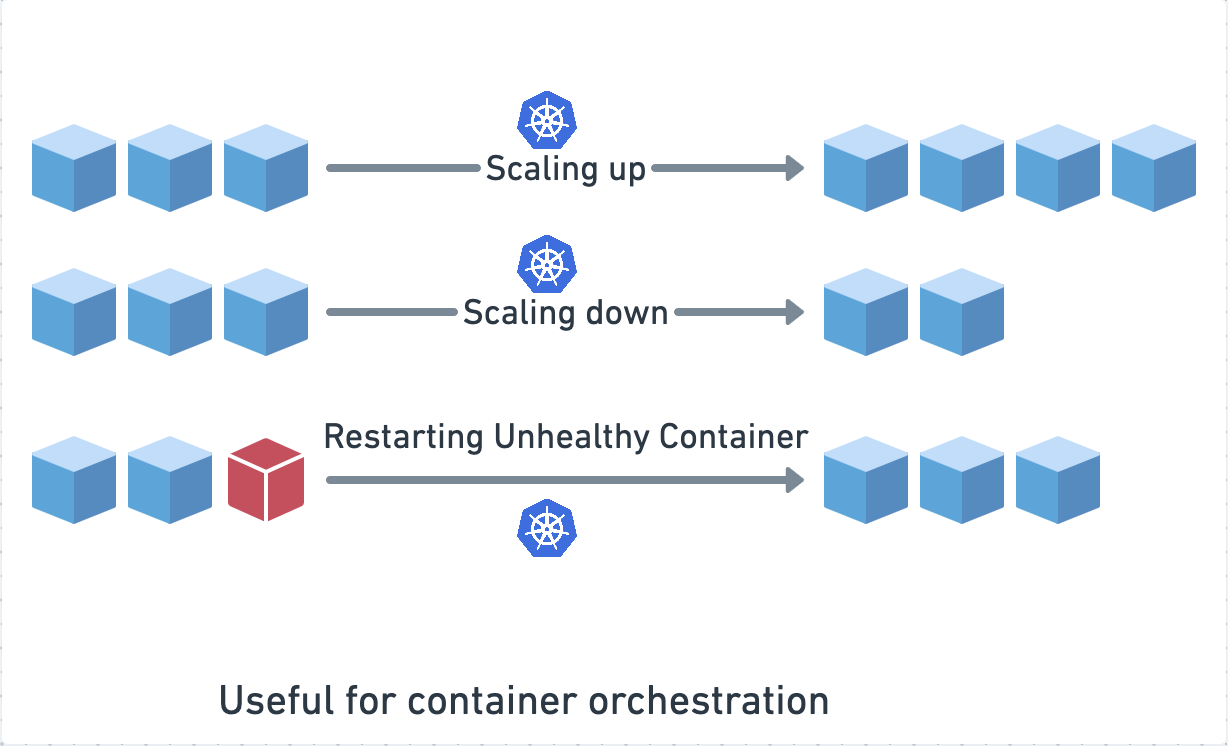
Each app/service now runs in a container, so there can be a separation of concerns. Services don’t need to be intertwined with each other, and a microservices architecture works best with containerization. We have established why the world is moving towards containers, but who is going to manage these containers and how do you roll out a release? How do you run health checks against your services and get them back up if they are failing? Kubernetes automates all of this for you. You can easily scale up and scale down your services with Kubernetes.
You can use Kubernetes anywhere for on-premise deployments or even hybrid clouds. For instance, you can have your cluster on GCE, AWS, Azure, or any cloud provider. For this Kubernetes tutorial, let’s create a cluster on AWS.
Read more about the benefits of containerization and container orchestration with Kubernetes here. This is a really enthralling space, especially for folks interested in DevOps.
Creating a Kubernetes cluster
Assuming you have followed the steps in the prerequisites section, you should have eksctl installed. Follow the steps below to create a Kubernetes cluster.
1. Run the following command to check if eksctl can successfully access the AWS account and list any existing clusters:
eksctl get cluster --region us-east-1
In case this command fails, you may want to make sure your credentials are set up correctly, as mentioned here.
2. Next, create a cluster and assign some resources to it. The cluster.yaml is present in the Github project we cloned, as mentioned in the prerequisites. You can customize the configuration for the cluster based on the resources you want to assign to your cluster. You could choose a different region, maybe add more nodes, or also a different instance type. For this tutorial, we do not need as much CPU or memory.
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: playground
region: us-east-1
nodeGroups:
- name: ng-1
instanceType: t2.small
desiredCapacity: 2
A word of caution: The pricing for larger instances and more number of nodes would be more.
Use the following command to create the cluster:
eksctl create cluster -f cluster.yaml
It may take a while for the cluster to be ready. Once this command succeeds, assuming you have kubectl installed, the configuration for kubectl to access the cluster would be stored at:
~/.kube/config
3. Try fetching the nodes on the cluster using kubectl. You should be able to see the two nodes if you used the cluster configuration as mentioned above.
kubectl get nodes
Accessing the Kubernetes API from Postman
Next, we require a service account to communicate with the Kubernetes API. The service account is authorized to perform certain actions, including creating deployments and listing services by attaching it to a cluster role.
1. Run the following command to create a service account:
kubectl create serviceaccount postman
2. Create a role definition for the service account. This role definition specifies all actions that are permitted on the resources mentioned. The role.yaml is present in the GitHub project we cloned, as mentioned in the prerequisites. We will look at what these resources mean and learn how to create them in the next steps.
kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: postman-role rules: - apiGroups: ["apps", ""] # "" indicates the core API group resources: ["pods", "services", "deployments"] verbs: ["get", "watch", "list", "create", "update", "delete"]
Run the following command to create the role:
kubectl apply -f role.yaml
3. Assign the role to the service account by creating a role-binding:
kubectl create rolebinding postman:postman-role --clusterrole postman-role --serviceaccount default:postman
For every service account created, there is a secret token. Finally, we must extract the following from the token created for the service account:
-
-
- API server URL
- Bearer Token
- CA Certificate
-
4. Run the following command to reveal the secret e.g., postman-token-9lxcc:
kubectl describe serviceaccount postman
5. Next, we must describe the secret:
kubectl get secret <secret-token> -o json
6. Execute the command below to reveal the ca.crt certificate and the token, that is inside a data object. We need to decode these to base64 and use them. This can be simplified using jq command-line utility:
# Extract the token from the Secret and decode TOKEN=$(kubectl get secret <secret-token> -o json | jq -Mr '.data.token' | base64 -d)
# Extract, decode and write the ca.crt to a file kubectl get secret <secret-token> -o json | jq -Mr '.data["ca.crt"]' | base64 -d > ca.crt
7. You must get the API server URL from Amazon EKS. If you log in to your Amazon account and see the cluster details for the playground cluster we created, you should find an API server endpoint, which is the URL for the API server that we are going to be hitting via Postman.
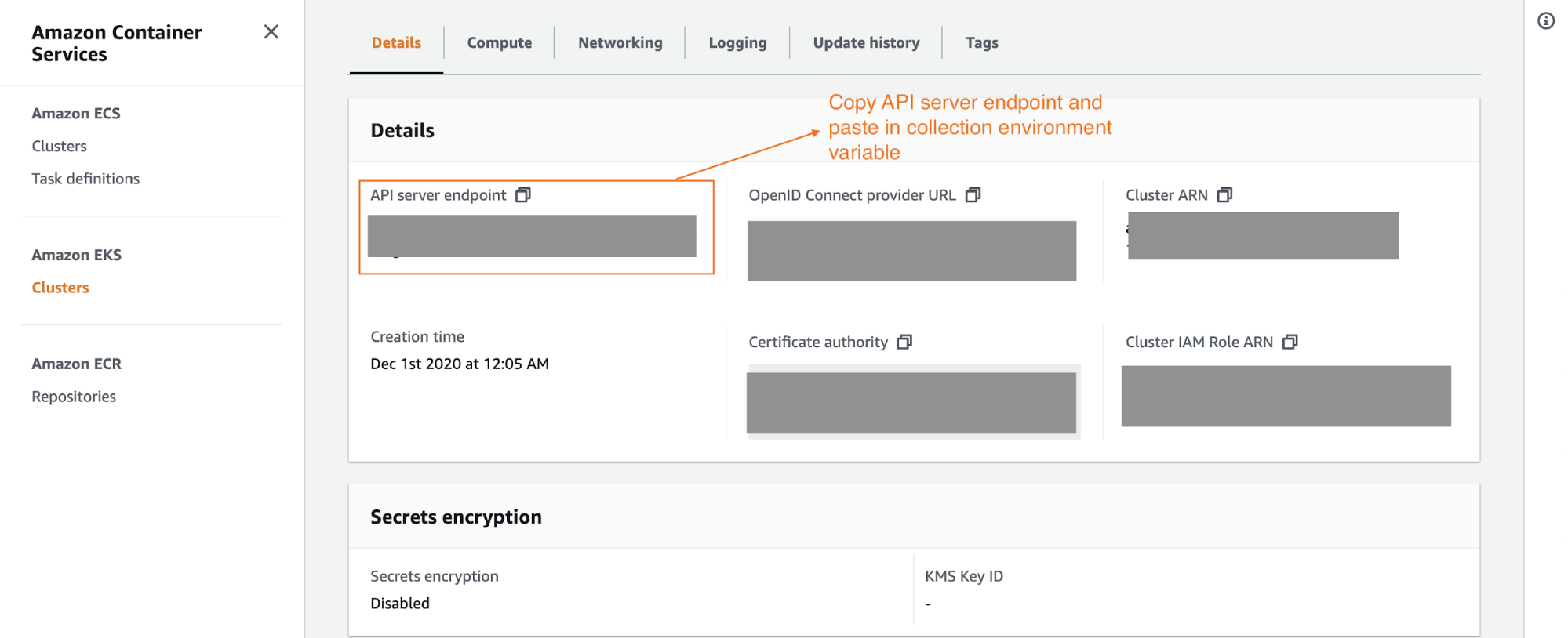
Authorizing the Postman Collection
1. Assuming the collection is already imported as part of the prerequisites, select the Manage Environments button on the top right, and edit the following:
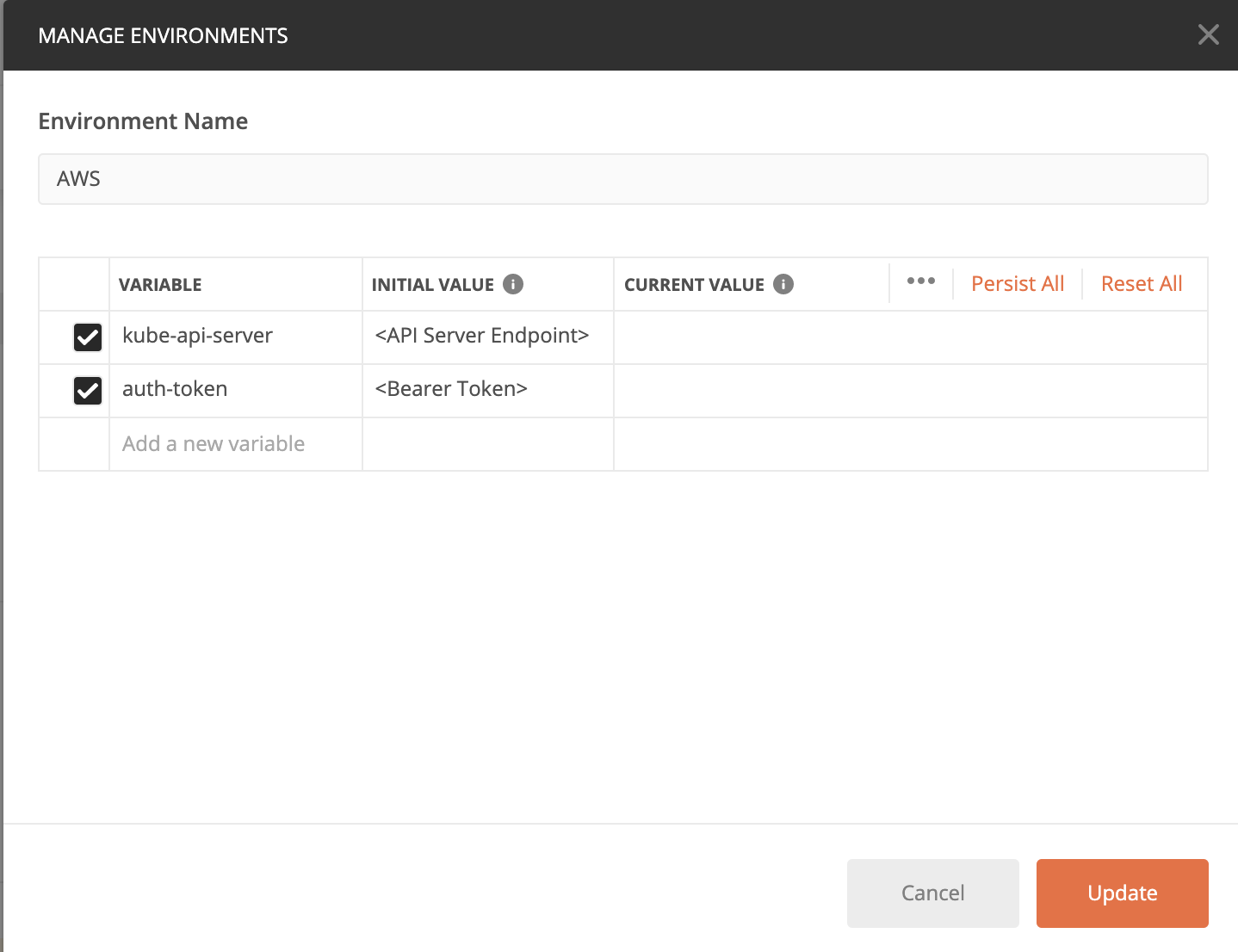
2. Paste the API Server Endpoint into the CURRENT VALUE for kube-api-server and the token into auth-token CURRENT VALUE. Click on Update.
Pro Tip: The current value is never shared while sharing the Postman Collection. Also, since these variables have sensitive information, it is best to add them to the environment variables. We could use the same collection and run it on different environments (i.e., GCP, Minikube).
3. Next, add Authorization to the collection. Adding Authorization at the collection level will ensure all the requests within the collection will be authorized with the same token/credentials.
4. Click on Edit Collection and under Authorization, select OAuth2.0. We can use the auth-token variable as the Access Token. This token will be passed in the Request Headers for each request.
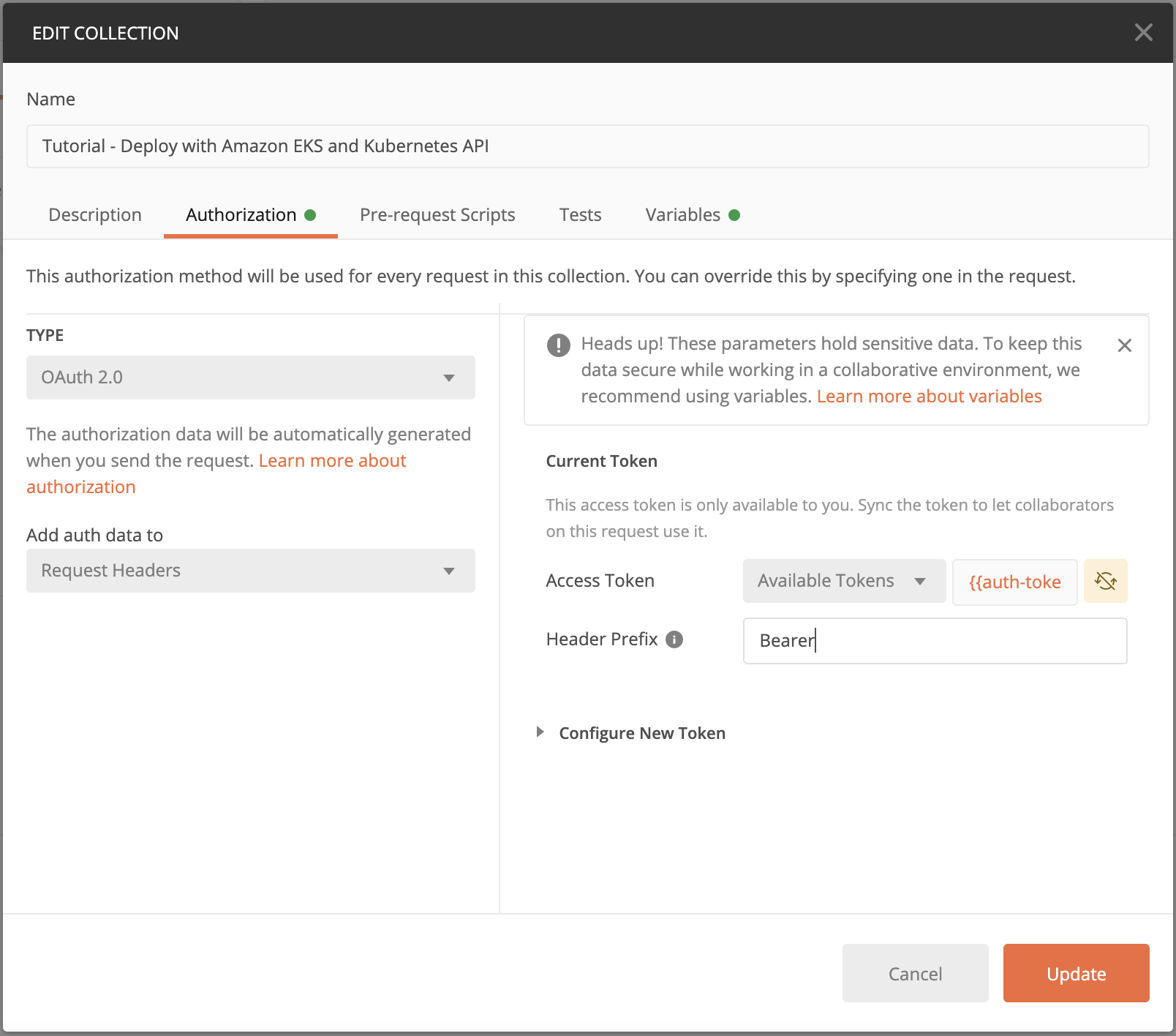
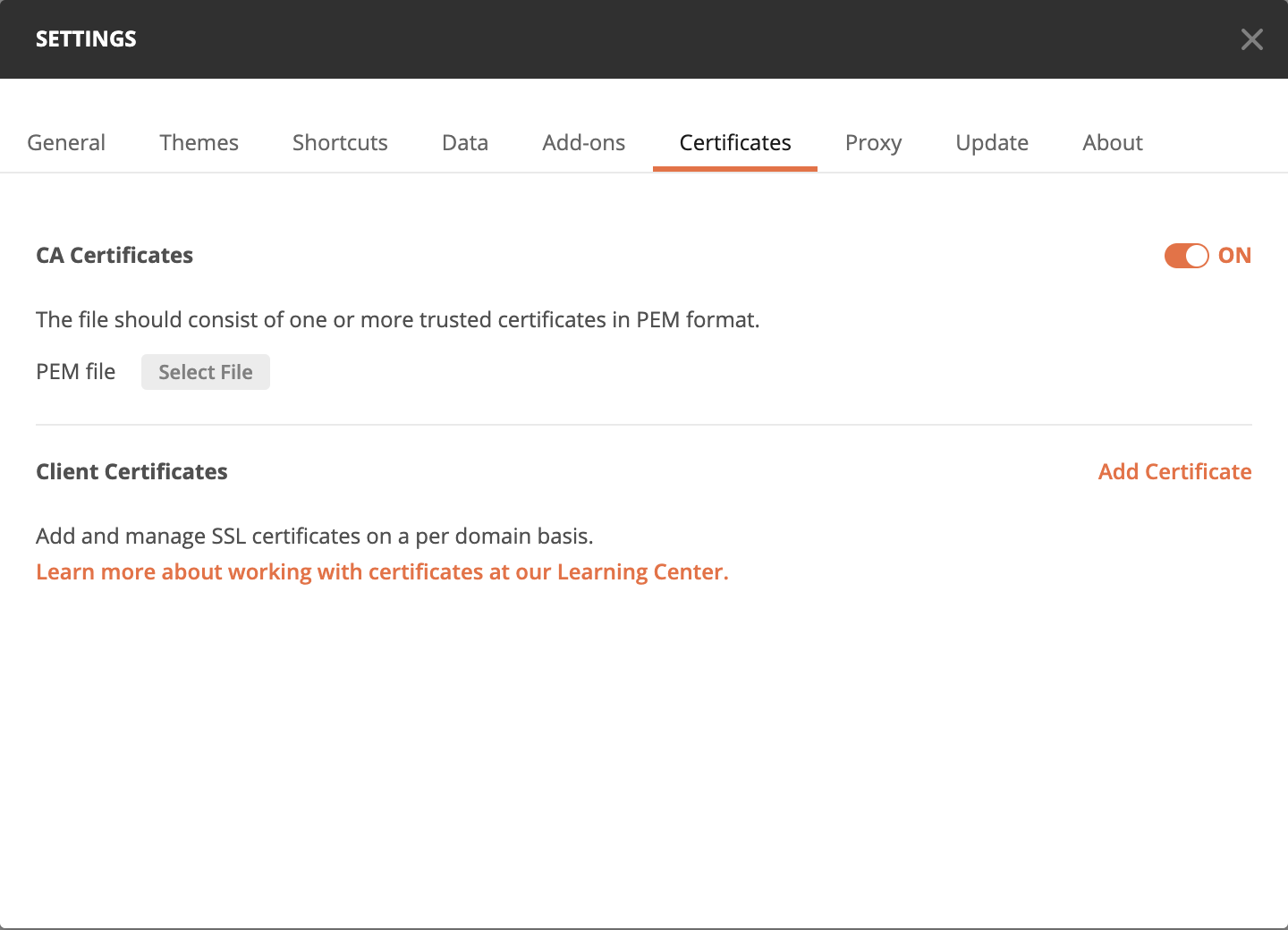
5. Almost there! The last step to get our collection ready is adding the CA Certificate. Simply click on Settings for Postman, and under Certificates, turn on the CA Certificates toggle to upload the ca.crt file we created. Alternatively, you can disable certificate verification, but that is not recommended.
Deploy an app
We are all set to deploy. First, we need something very important. Not surprisingly, it is an app. Let’s take a look at the app.
Enter Dobby. Dobby is an open source project, and it’s extremely simple to call different APIs on it and manipulate responses.
We spoke about containerization earlier: a container simply means an app is running in a sandbox. The container is created from an image. If there are any code changes in the app, we recreate the image to reflect the app’s latest changes and rerun the container.
We can find the publicly available image for Dobby here. We must use the image in the request.
The Deploy an App folder in the collection contains requests to create and list Kubernetes objects that will help deploy our app on AWS. Let’s take a quick look at these objects.
Creating a Kubernetes pod
In Kubernetes, pods are a group of containers and also the smallest deployable unit. The pod will define the configuration that is required to create the app container.
We must create a pod for Dobby. You should find the configuration as json in the request body. We have created a collection variable called project-name, this variable is going to be used throughout the collection while creating resources, so it made perfect sense to extract it. You can rename the variable if you want.
1. Click on Body to find the request body as shown in here:
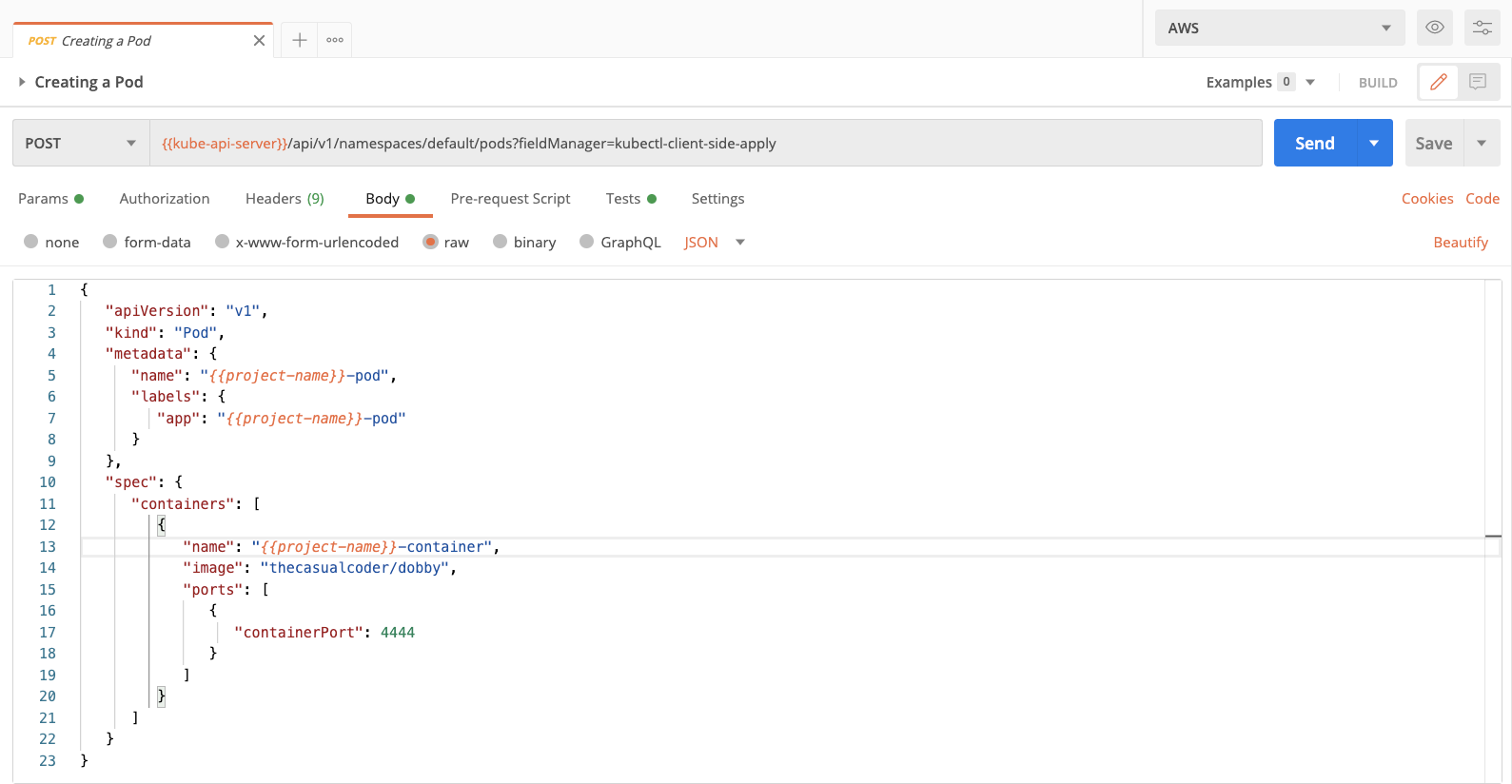
You will find fields for metadata name, the name of the pod, and labels. We’ll discuss how labels are useful in the subsequent requests. If you scroll below to the spec you will also find the image that we are using for the containers, and the port the app is supposed to run on.
2. Press Send. There will be a lot of details in the response body.
3. Click on Visualize, and if the response is successful, congratulations are in order! Keep going.
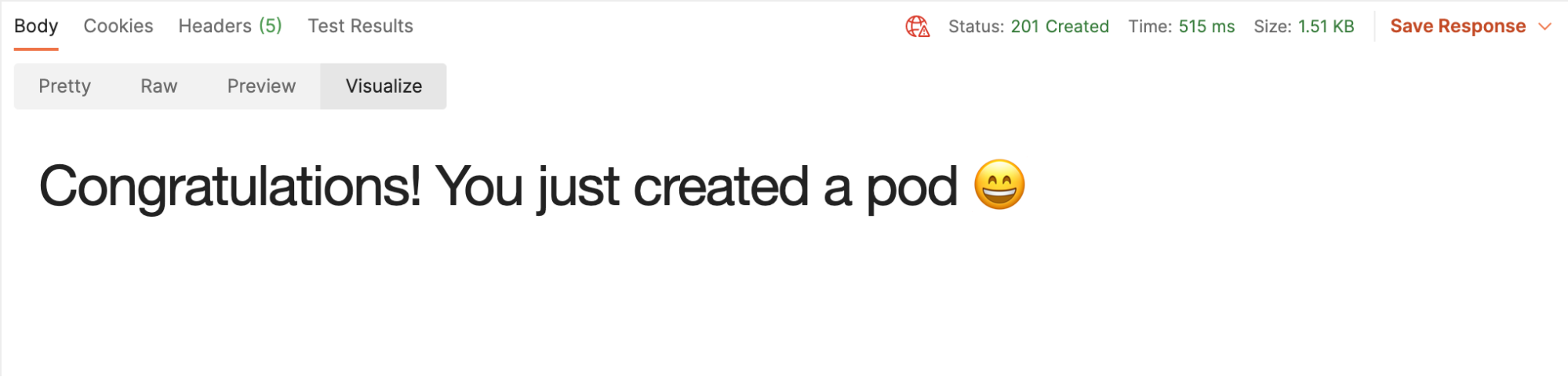
4. Send the GET request that lists all pods created. Again, click on the Visualize button:
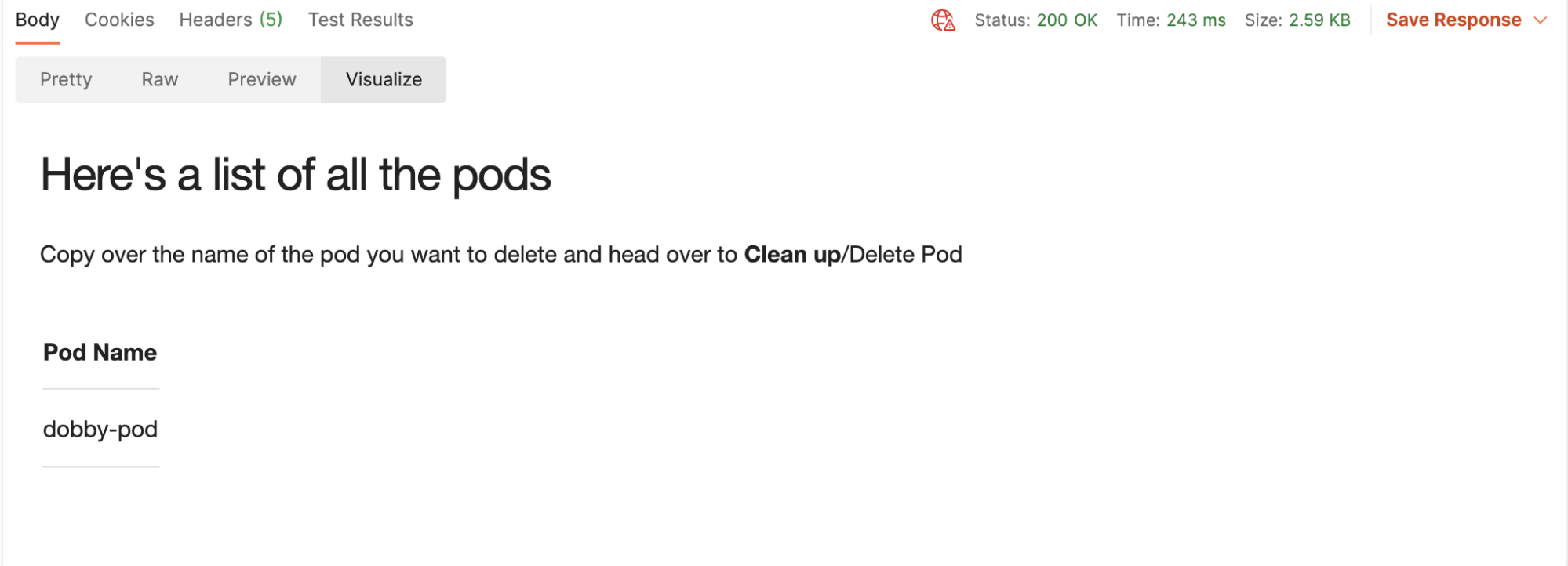
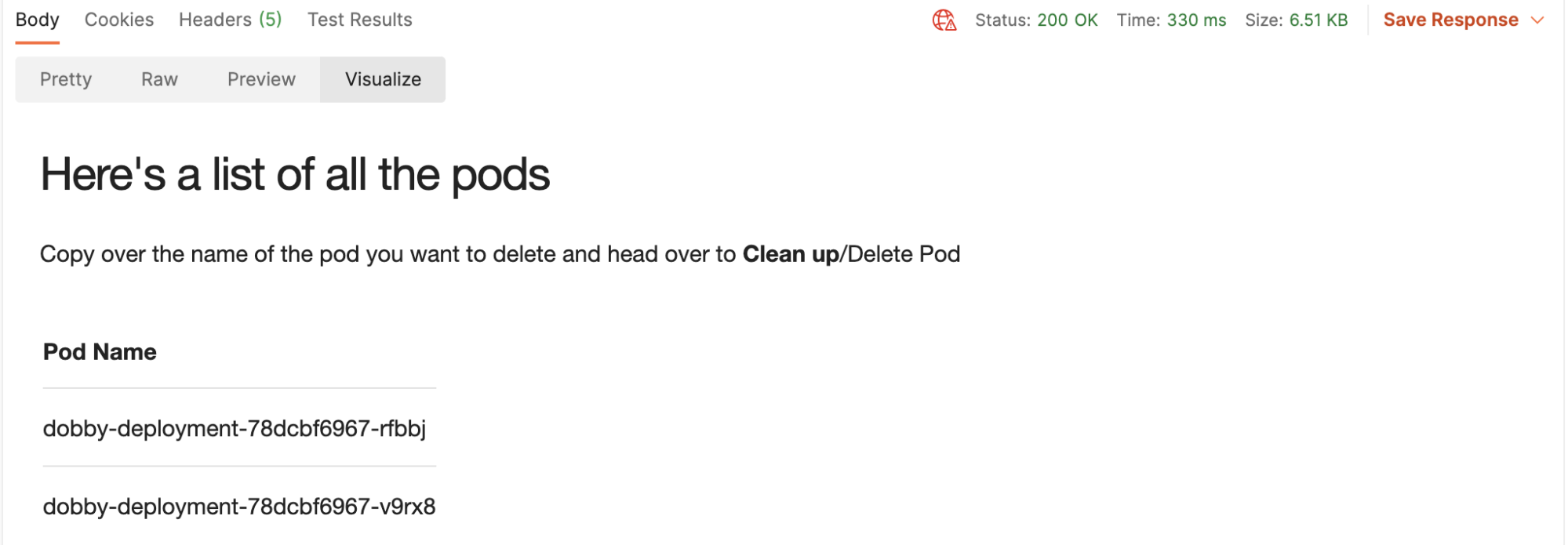
5. Head over to the Clean Up folder, and run the Delete Pod request:
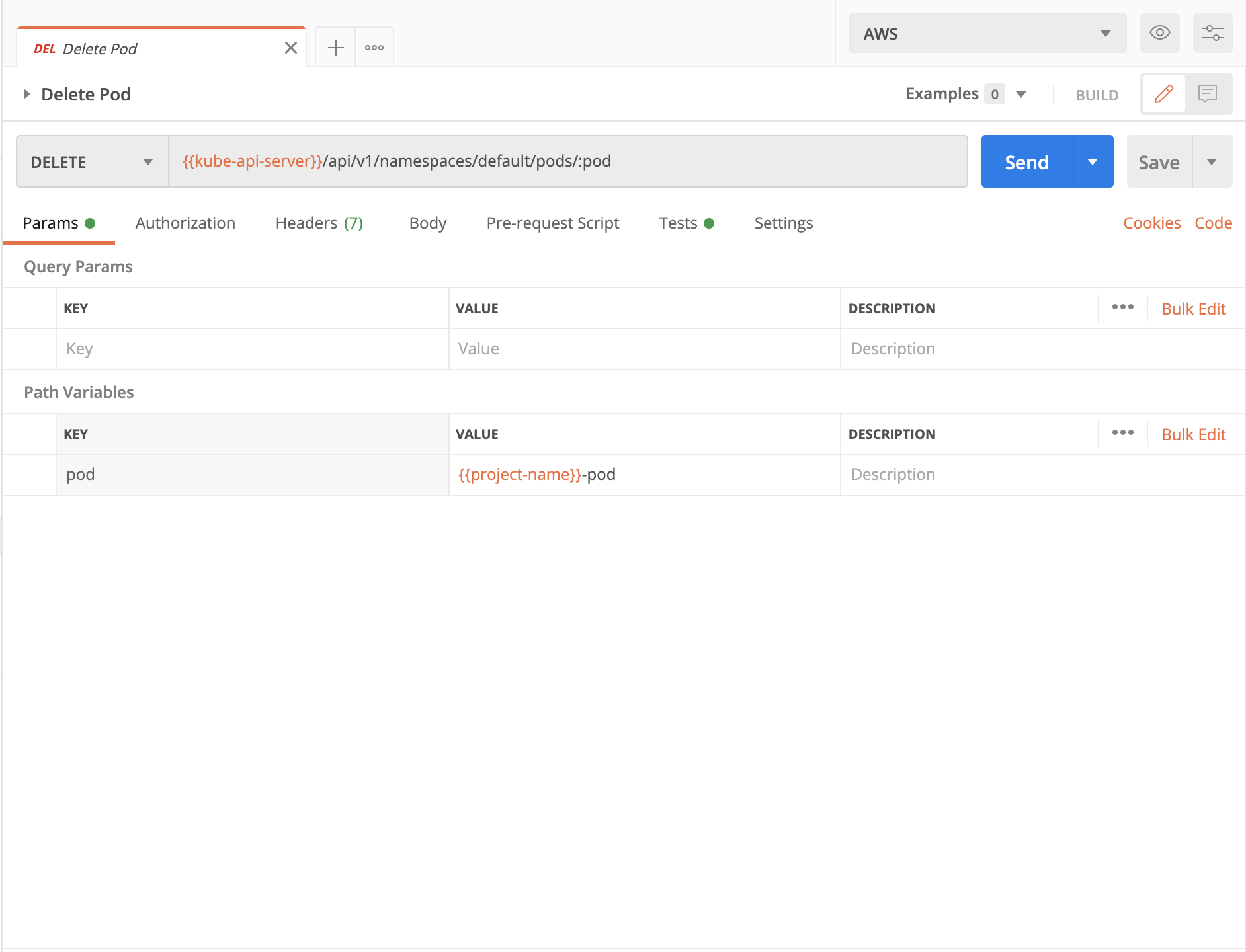
6. Again, click on Visualize to see the response as a prettier message:

Deployment
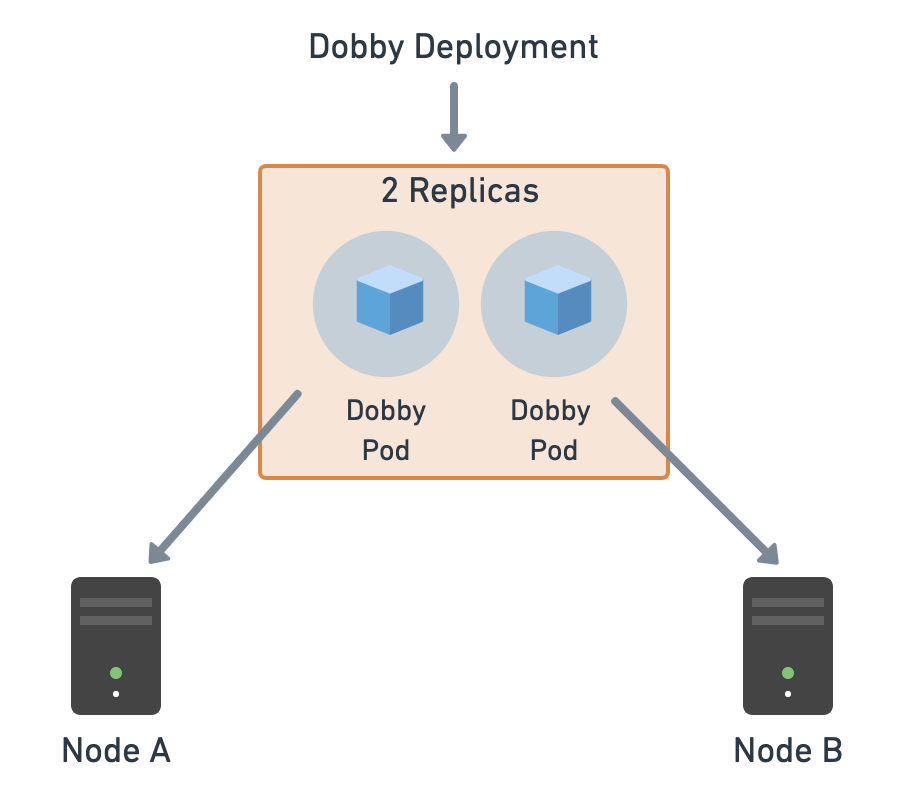
In the previous section, we created a pod and deleted it. That means our app is no longer running. In a real-world scenario, though, we would want to have multiple instances of our app running so that the requests could be load-balanced across them. These instances (pods) could be running on different nodes/machines. We want to ensure that at least a minimum amount of instances are running. Deployments can help us manage it all.
1. Click on Body to review the request body. The body contains the configuration for the deployment:
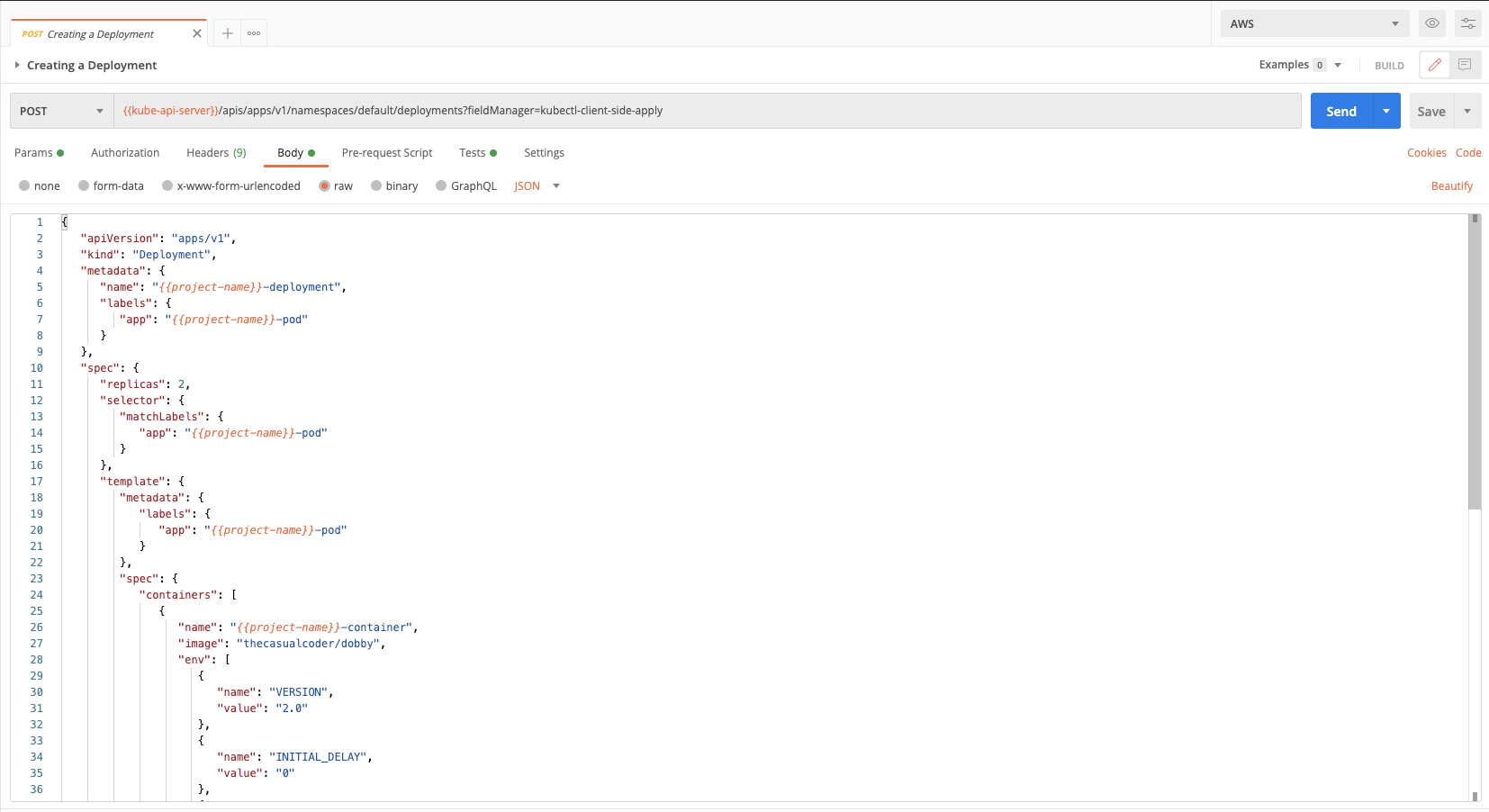
Components of the body:
- Replicas: Refer to the number of pods that should be running for a deployment. We are assigning the pods that get created via this deployment a label of -pod.
- Labels: Pods are matched to the respective deployments by these labels.
The body also contains a definition for a readiness probe and a liveness probe:
- Readiness Probe: Containers are assigned traffic in Kubernetes based on the readiness probe. This can be used when the container is not ready to serve traffic due to other services it depends on, or if it is loading any data/configuration.
- Liveness Probe: Containers restart based on the liveness probe. So to check if the Dobby app is up, the /health endpoint will be hit. If it returns a 500 then the containers are restarted.
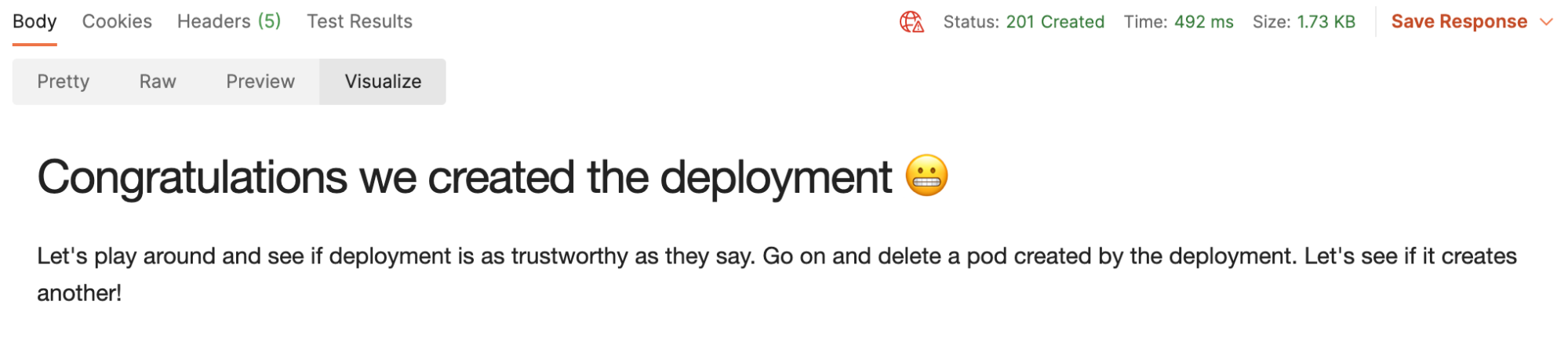
2. Press Send to create a deployment and look into the Visualization tab for the next steps:
3. Send the GET request that lists all pods created. See results in the Visualization tab:
Expose your app
In the previous section, we were able to successfully create a deployment. So how do we access it now? The pods created have IP addresses, but what if we want to access one app from another?
Let’s take a look at Kubernetes’ service.
Service
We have two apps—frontend and backend. There are separate pods for the frontend and for the backend. We need to expose the pods of the backend so that the frontend app can access it and use the APIs. We usually configure the IP address or URL for the backend into the frontend. However, if the IP address changes for the backend, those changes would have to be reflected in the frontend app as well. With services, we can avoid these changes.
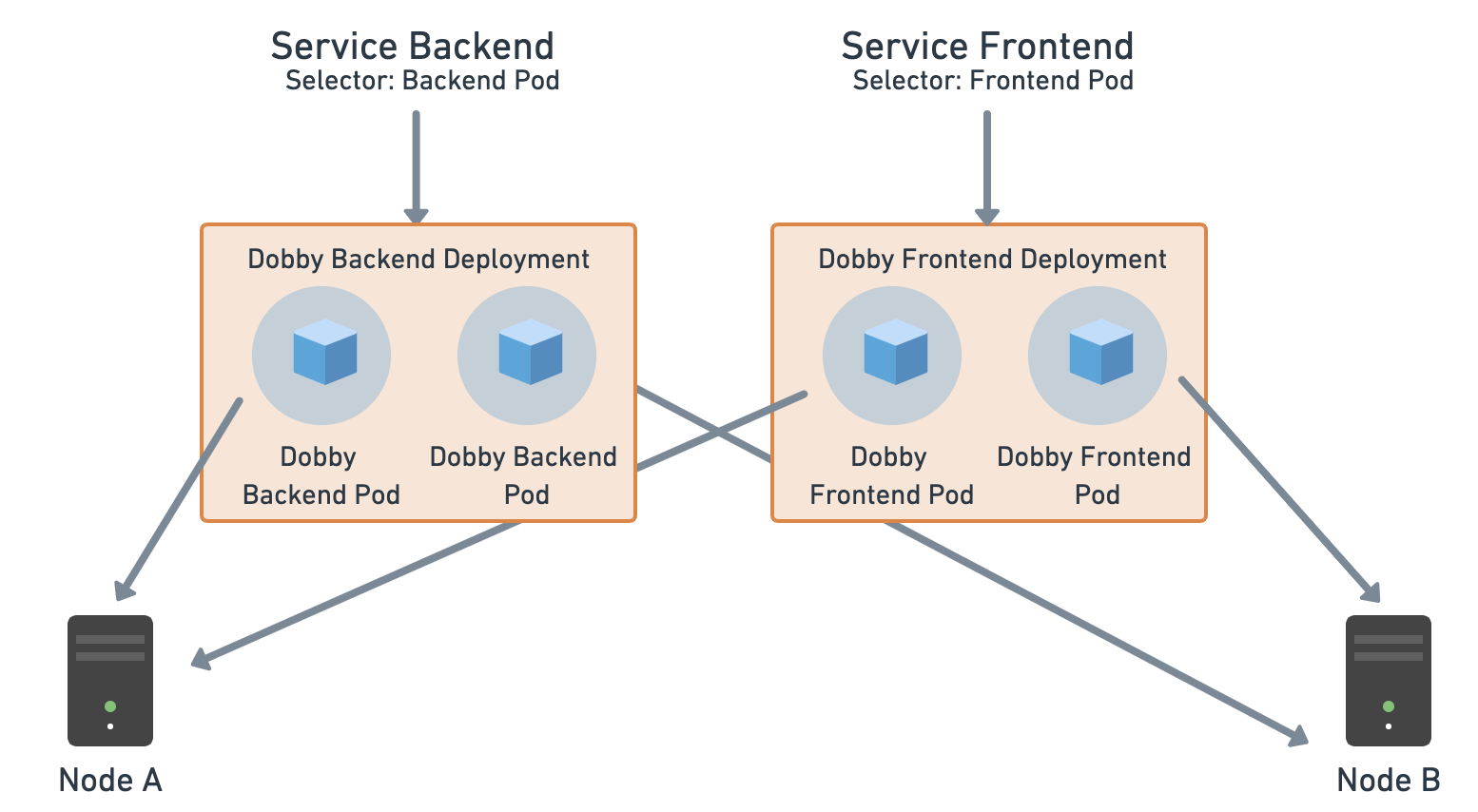
1. Review the request body by clicking Body:
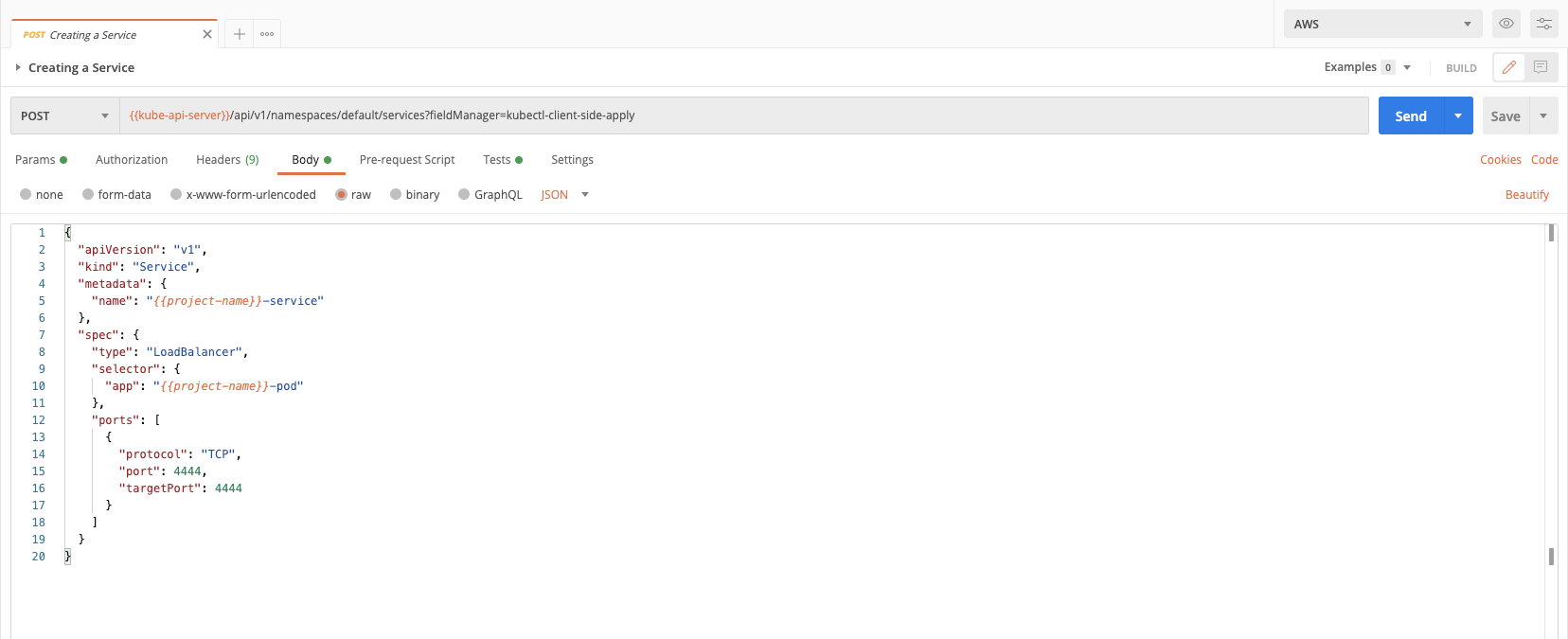
Components of the body:
- Selectors: The selectors help the service map to the pods that have the matching label.
- Exposing: Services can be exposed within the cluster for other services (frontend) to access the pods, or outside the cluster for the public to access the service. By default, the service would be of ClusterIP type (this would expose the service inside the cluster). We want to expose this externally, so we chose the LoadBalancer type.
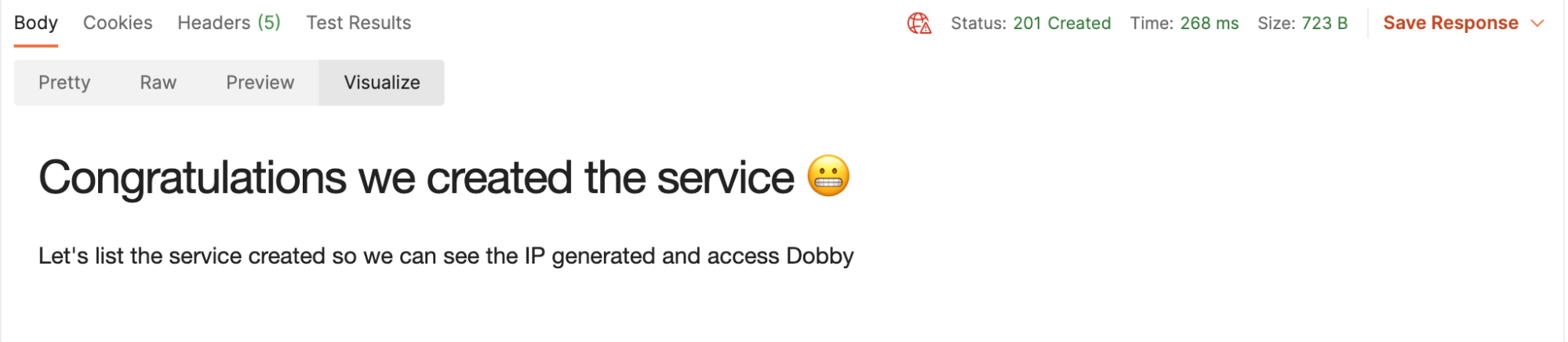
2. Send and view the Visualization tab:
3. Run the list of service requests to find the IP address of the service. Here’s what you should see under Visualize for the List Services request:
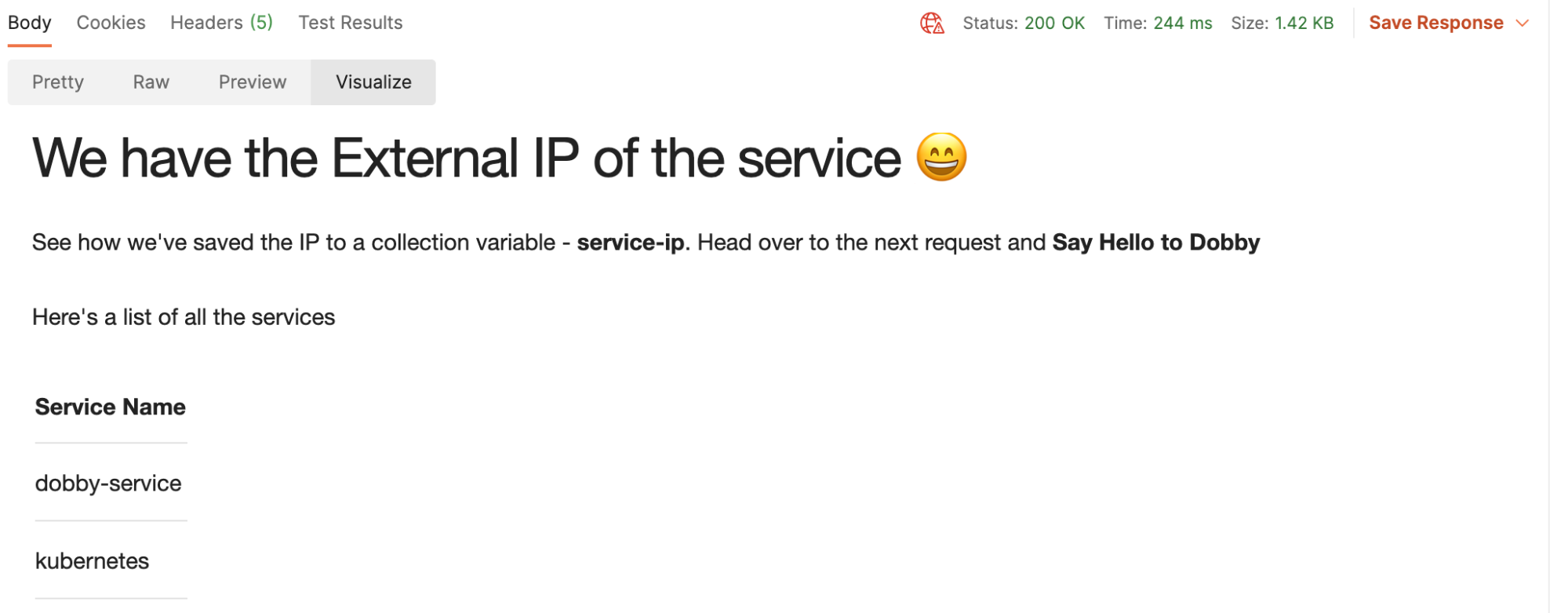
The following snippet in the Tests tab will save the external IP for the service to the collection:
const service = pm.response.json().items.filter((item) => item.metadata.name ===
pm.variables.get("project-name")+"-service")[0]pm.collection
Variables.set("service-ip",
service.status.loadBalancer.ingress[0].hostname)
pm.collectionVariables.set("service-port", service.spec.ports[0].port)
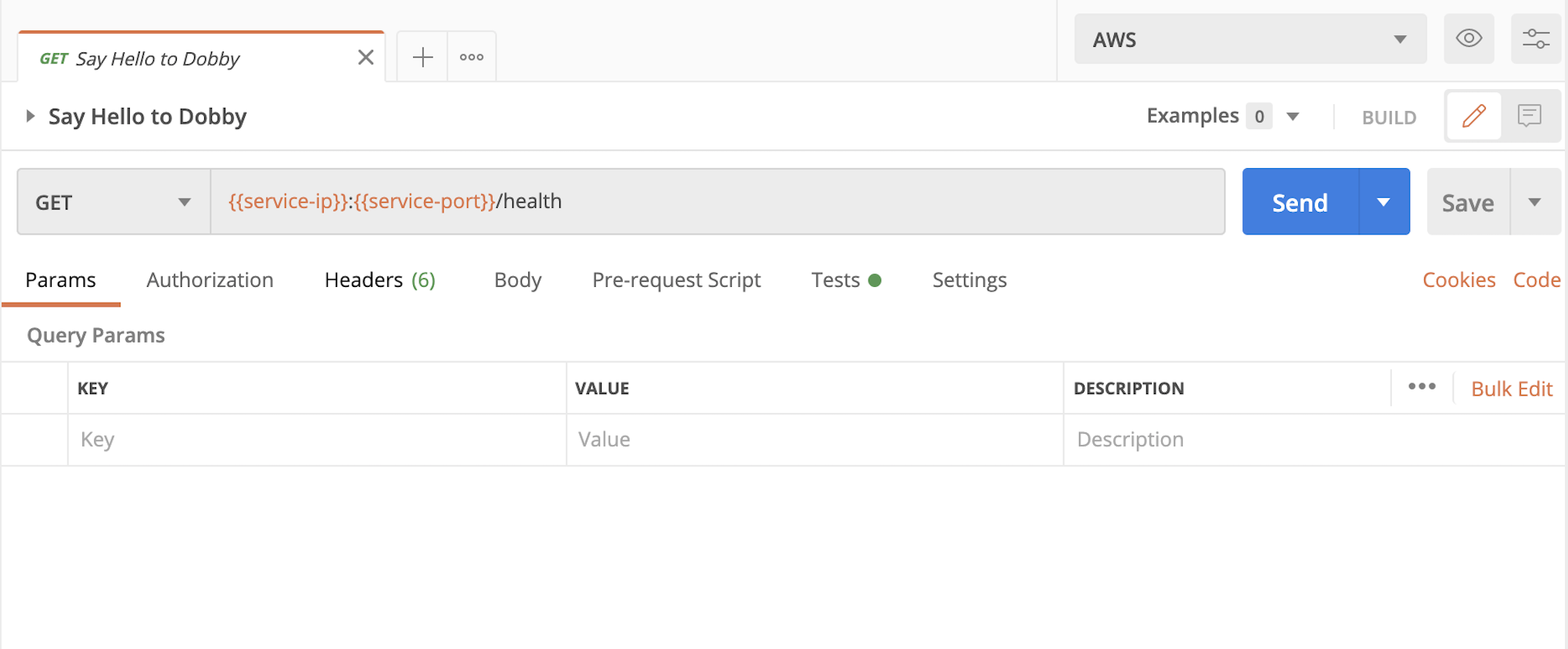
Now we need to access an endpoint on the Dobby app to check if the app is running. Note: It might take a while before the service starts serving requests. Once the service is ready, click on the Say Hello to Dobby request. If you hover over the service-ip and service-port variables, you should see their value that was set by the tests in the previous request:
Upon pressing Send, under Visualize you should see the message we have been working so hard for:

Clean up
You will find a Clean Up folder in the collection. It contains all the requests to delete the Kubernetes resources—services, deployments, and pods we created throughout this tutorial.
At the end of the tutorial make sure you delete your cluster, unless you wish to keep it:
eksctl delete cluster -f cluster.yaml
What next?
Hopefully this tutorial helped you get started with Kubernetes. And there’s so much more to explore. Here are some additional things you can try with this Kubernetes collection:
- Creating other Kubernetes objects: In this tutorial, we discussed a few Kubernetes objects, including service accounts, pods, deployments, and services. Next, you could explore other kubernetes objects like namespaces and ConfigMaps.
- Automate workflows in Postman: You could use the collection runner in Postman to execute common workflows. A workflow in Postman is ordering the requests in a collection to accomplish a task eg. running health checks for all services. Take a look at our blog post about looping through a data file in the postman collection runner and building workflows in Postman.
- Automate deployments in CI/CD: In case you want to automate deployments, consider using Newman—command line runner for Postman collections. If you prefer kubectl, you could use that instead.
- Experiment with Dobby APIs to learn more: The Dobby app has APIs such as
/control/health/sick, which will make the app return an internal server error. You can run these and observe their effect on the liveness and readiness probes to learn more. - Fork collection and raise PR: Additionally, you could also fork the collection and raise a pull request with your changes.
Technical review by Kevin Swiber, lead solutions engineer at Postman.


I have followed the article to the letter but finally I get
“pods is forbidden: User \”system:anonymous\” cannot list resource \”pods\” in API group \”\” in the namespace \”default\”