
A Year Later: Evolving Postman’s Universal Search Feature
Over the years, the software industry has moved from device-first to web. And with that evolution, APIs became essential to the developer ecosystem. Then came API-as-a-Product (AaaP) companies like Stripe, Twilio, and Sendgrid, which brought APIs to the epicenter of the ecosystem. However, because this was a new shift, the ecosystem lacked standardization of practices and tools to help companies govern, standardize, observe, and secure the API development lifecycle. Inspired to solve this problem, Postman is on a mission to provide the first-ever complete API platform to support the entire API development lifecycle, helping companies of all sizes to build robust, resilient, responsive, and reliable APIs for their customers. Today, Postman is used by more than 17 million developers around the world. They rely on the Postman API Platform for designing, mocking, developing, monitoring, testing, and collaborating on APIs.
As we grew to be one of the most influential developer tools used globally, we realized a gap in API discovery. If your development workflow involves implementing APIs, you might know the pain of re-inventing workflows because there is a lack of an API discovery tool (internal to your company or global). We were aware of this problem, but as every paradigm-shifting solution needs a good foundation, we waited for that right moment. And last year, we introduced Postman’s Public API Network, which was the foundation we needed, along with our current offerings, to sit down and build a world-class universal search for your private and public APIs.
One of the critical constraints we were working with was shipping universal search with the Public API Network. We believed that we were about to build the world’s largest API Network for the developer community (and it happened sooner than we thought), and it needed a robust search experience. The same holds for the Private API Network.
How do products and teams evolve inside Postman?
Before going into the details of the whys of certain product decisions, it’s essential to explain how we look at products holistically. We believe that it would be arrogant to look at every idea we come up with as the game-changer for the developer ecosystem. So, we push each product (sometimes even features) through five different battle-tested phases:
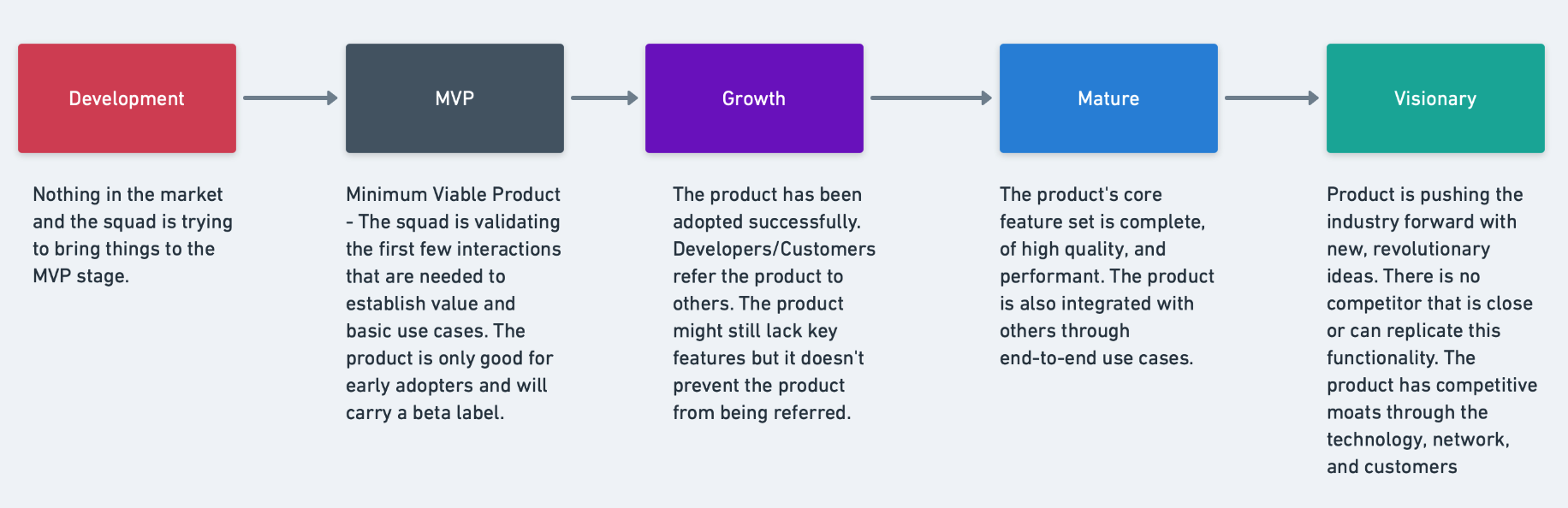
1. Development
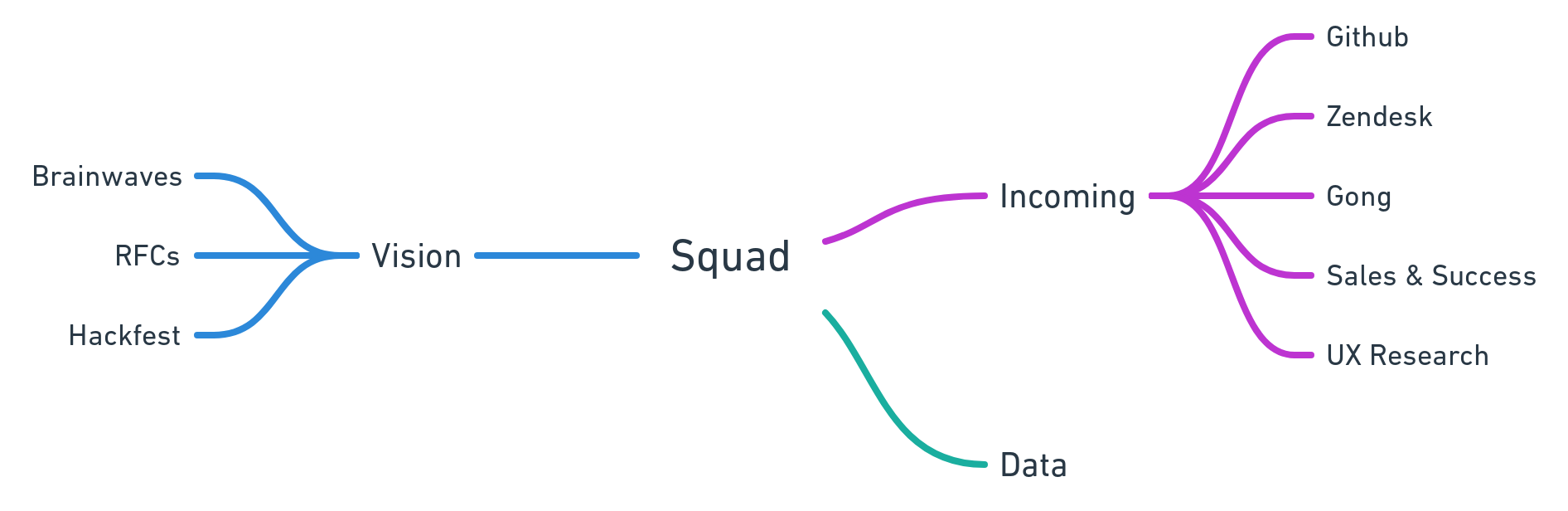
During the development (ideation) phase, we analyze various incoming feedback streams like product analytics, Github/Zendesk feature requests, customer calls, and more. Then, based on those signals in conjunction with our vision stemming from the deeper context of the market, we finalize a product with a finite feature set. We also make sure that our efforts contribute towards the Postman Flywheel.
2. MVP (Minimum viable product)
In the MVP phase, we start getting realistic about the vision. We define constraints that we are working within this phase. These constraints could be time, features, alignment with other products, etc. The usual timeline is three to four sprints (i.e., approximately 1.5-2 months), based on the complexity of the product/feature. Once built and approved (from our product, UX, and security teams), we start rolling out these MVPs in a controlled manner behind feature flags. Dogfooding is a big part of MVPs; we ensure that we have something working and enable the Postman team to try it out within a few sprints.
MVP stage is an indefinite stage. We keep on iterating based on the user feedback, our research, and customer behavior. If nothing works, we take a pause, go back to the drawing board again, or, in the worst-case scenario, kill the product.
3. Growth
Once customers love what we are building and keep loving for a considerable time, we move the product into the growth phase. In this phase, we know what works and what does not, so we start doubling down on things that are working. In this phase, we don’t experiment a lot, but it’s not discouraged. Of course, if we have strong signals to improve what is already working, we will consider those signals carefully and consider modifying the feature accordingly.
The growth phase also focuses on product robustness, reliability, responsiveness, and resilience (I call it the “Golden Rs”) from the engineering side. From the product side, the Customer Satisfaction Score (CSAT) and North Star Metric performance are the guard rails for our team.
4. Mature
The mature phase is the goal for everyone inside the team and company; when the product is validated, customers are happy, usage is growing, and those Golden Rs are achieved. The product has become part of the Postman API Platform and provides end-to-end use cases for our customers.
5. Visionary
In the visionary phase, we start taking bold steps based on the context gained throughout the evolution. We take chances often no other competitor has even imagined yet, with one underlining guideline of contributing to the Postman flywheel. In most cases, we make each innovative feature go through this entire pipeline again.
Starting with the UX first
Search is an engineering-intensive problem, and we knew the risk of adding limitations based on time, technology, and bandwidth constraints. Still, we decided to ignore that for a moment to build the best UX that we could think of in the Postman app.
Our vision for universal search is for it to become the entry point for all the APIs in this world. We are sure that given the foundation of the Postman ecosystem, we have a great chance of building the best API Discovery tool in the world through this Universal Search.
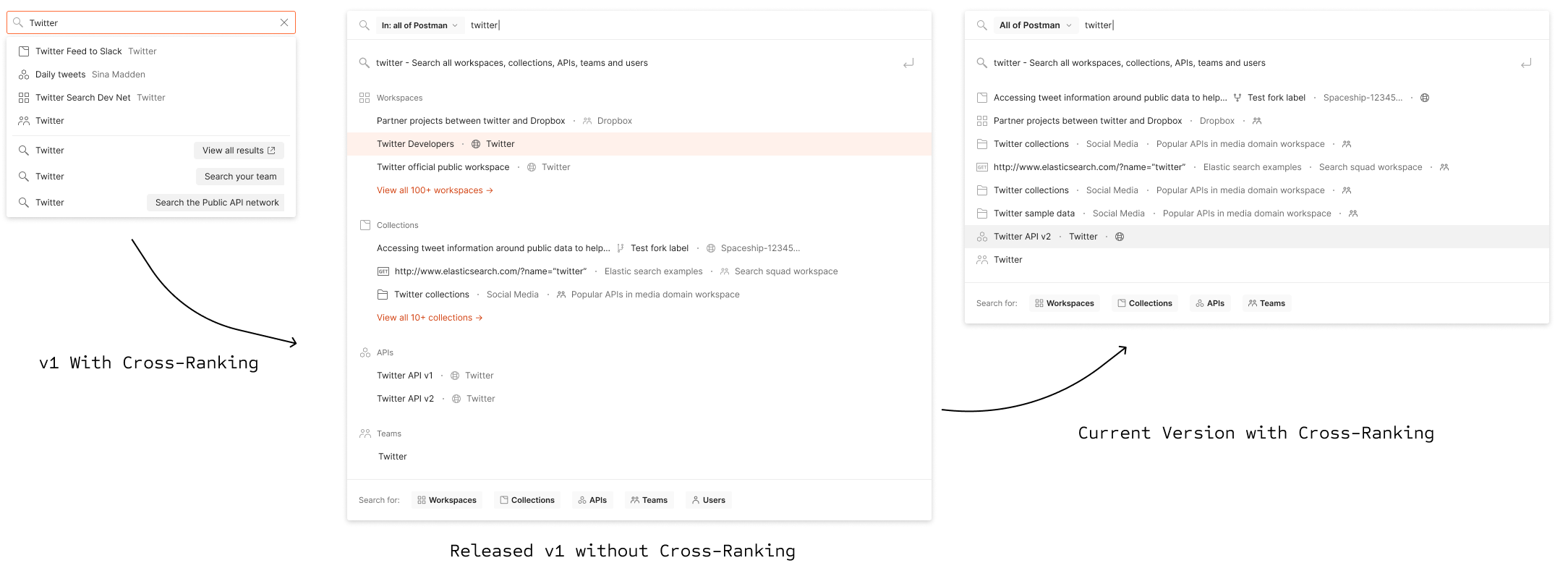
We had to take realistic baby steps towards our end goal. And we had approximately 1.5 months to release. So the best UX was to have a single list of all the elements we have in Postman (i.e., collections, workspaces, public workspaces, requests, and APIs), but that had to take a backseat because it was a substantial technical challenge given the time constraint and amount of data. So we started with grouped ranking, which made our task easy.
Building engineering solutions given the business constraints
Our next enormous task was to build the data pipeline. How will data flow from all the different microservices, what database will we use to index this data, and what algorithms would we use to improve the search results?
Our constraints were:
-
We had to release universal search experience with Postman v8, which was scheduled in a couple of months.
-
We needed the
Search As You Typefeature. -
We could not rely on other teams for data sourcing because they were already busy with their own product releases.
Choosing the right database
We evaluated Solr and Elasticsearch because they were the clear long-term choices. Though both Solr and ES are based on the same foundation (i.e., Lucene), we realized that ES has the best hosting support from AWS, which will reduce our DevOps efforts significantly, creating more reliability, resilience, and robustness. Also, ES has a good amount of feature parity for our context. We went ahead with ES as an index database.
Data sourcing
Data pipelines/sourcing is where some of our long-term bets came in handy. Over the last couple of years, we have spent a lot of time building a robust and scalable data pipeline inside Postman. Considering all the constraints, we decided to take advantage of our existing data pipeline:
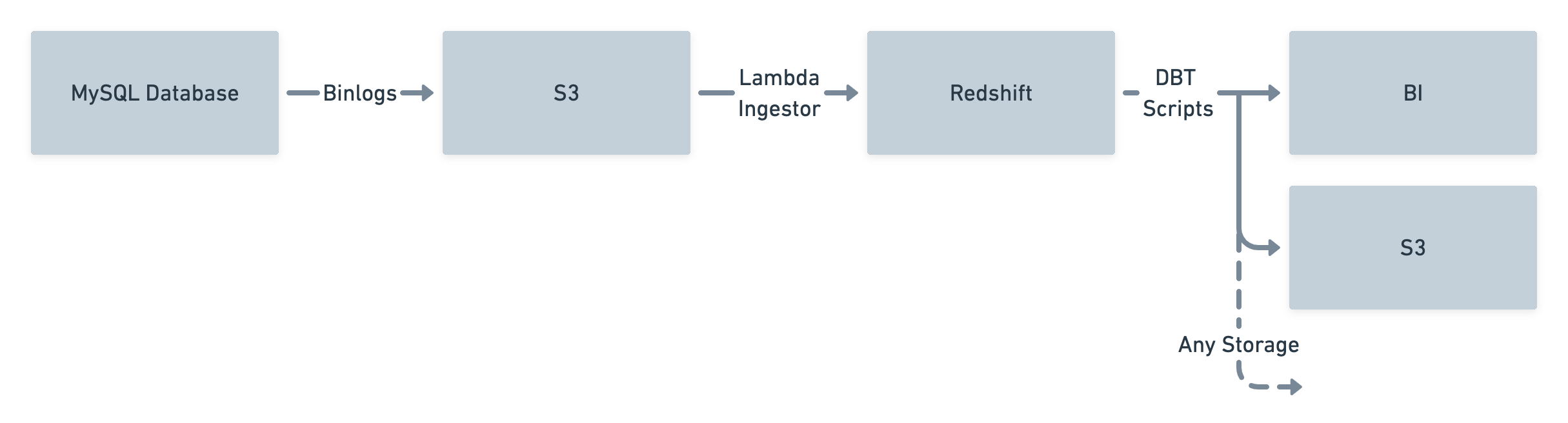
We attached an AWS Lambda-based ingestor to the S3 storage where we were pushing data as required using the DBT script. And—voila!—we had a complete data pipeline ready for our search service:

After the first release, cross-ranking was our target
Once we released our first version of Postman’s universal search feature, we were flooded with appreciation and suggestions. But we knew that, before considering any of those, we needed a better cross-ranking solution. Once we ranked different elements inside Postman based on various parameters, we could then build an effective UX for building a fully equipped universal search.
What is cross-ranking, and why is it important?
In Postman, we have multiple elements like collections, workspaces, teams, users, APIs, monitors, and more. These elements are related to each other, but each has a different significance in Postman with different properties associated with them. How do we rank a collection and a workspace against a search query? This is a cross-ranking problem.
To build a better search UX, we had to solve this problem. For example, when you search on Google, you see content from all the sites ranked against each other. So we needed to do the same for all Postman elements in order to build an optimal search experience.
Before going into the solution for cross-ranking, let’s see how we store our searchable elements
Each element has a separate index in Elasticsearch. But not all elements in Postman should rank the same because some rely on others. For example, a request cannot exist without a collection. Similarly, a folder cannot exist without a collection. Therefore, these two elements are indexed in a nested manner in the collection index.
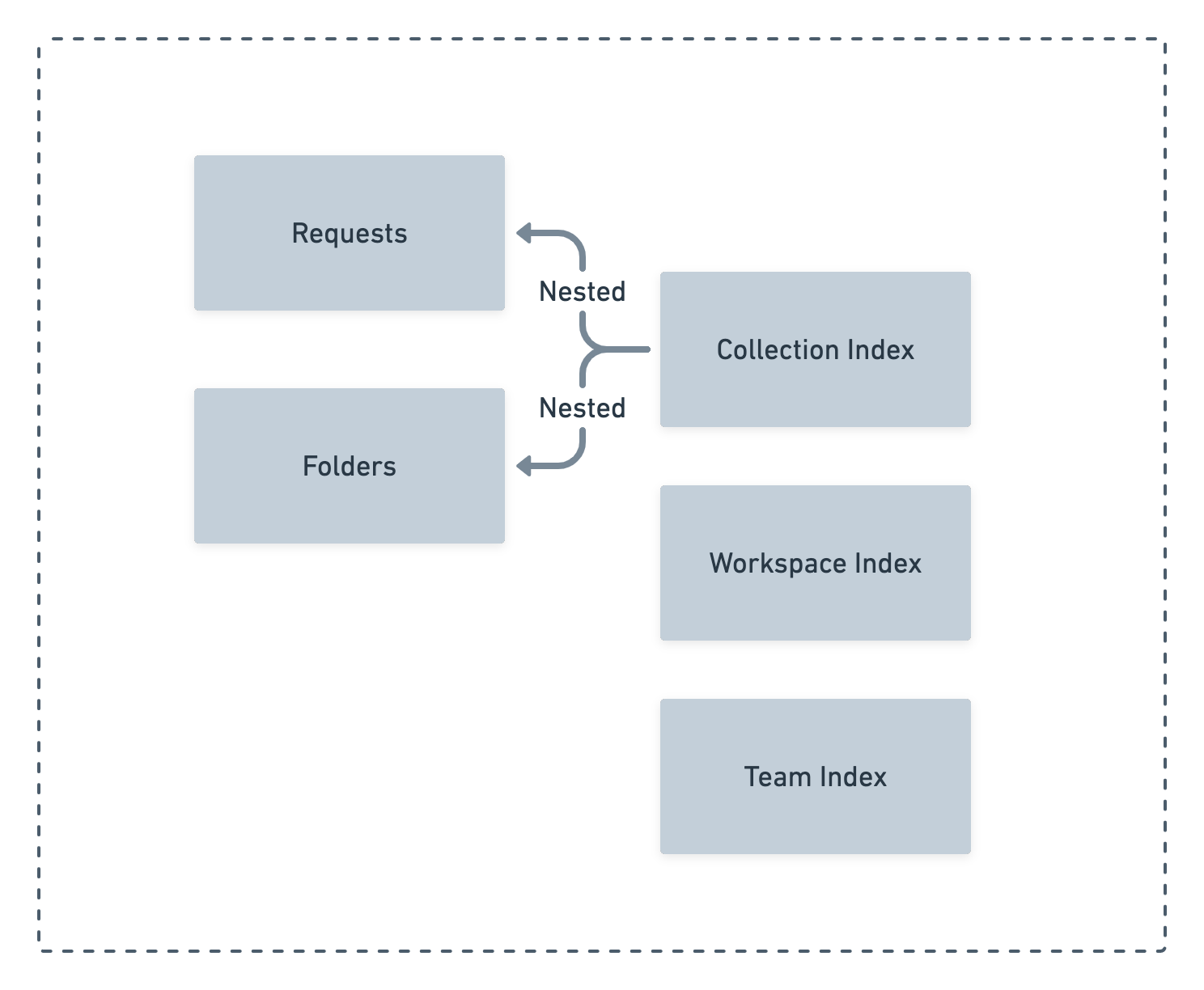
Cross-ranking algorithm
The core problem was bringing a normalization factor for ranking these heterogeneous elements. This is where our data on user behavior came into action. We realized a clear distribution pattern behind which our users consume elements in the search results.
Collections were the most popular search results by consumption, and teams were the least. Therefore, we decided that for the first version of cross-ranking, we would keep this as a normalization factor.
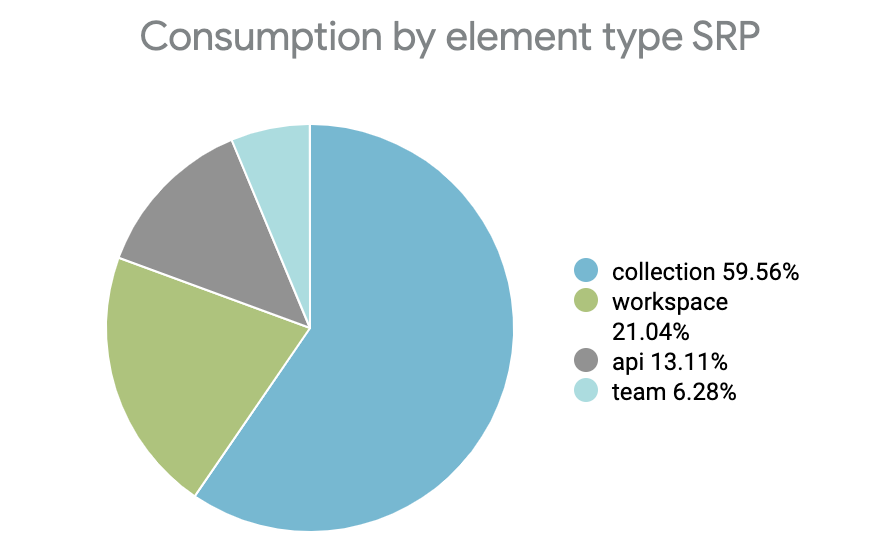
With this change, we also added what we call “boosting parameters.” Some examples of boosting parameters are the number of forks on a collection, the number of views on a collection or workspace, the verified team profile, etc.
How does this cross-ranking algorithm work?

Building extensions on top of the universal search stack
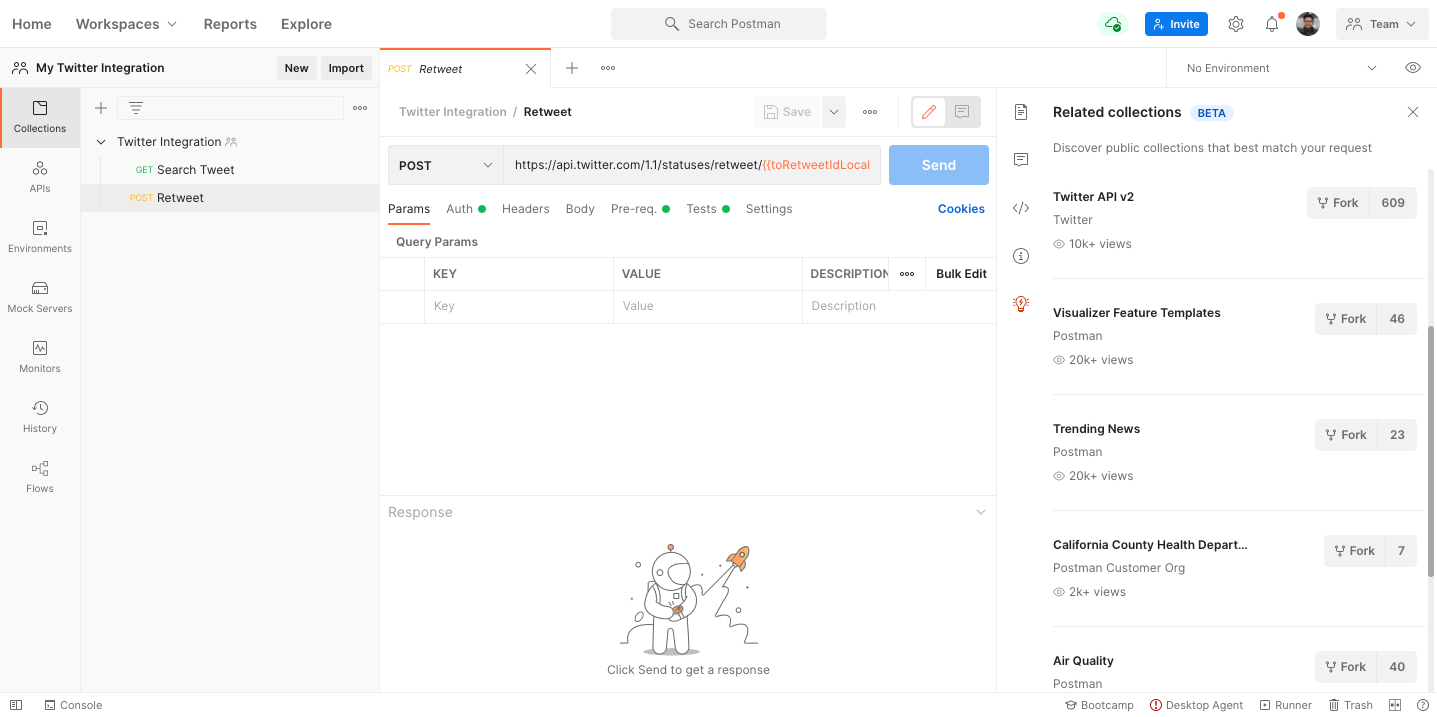
Once we knew how to rank different elements against a query string, the possibilities were infinite. We, as a company, intend to build more API intelligence and bake it inside the product at every level. We have released one such feature recently, called recommended collections. When Postman sees that you are working with APIs that are already available in our Public API Network, the platform contextually starts recommending collections for you to fork, in order to save you time and provide easier discovery:
What’s in the future?
This is just the beginning. We have tons of things planned for the future—like query understanding, a machine learning-backed algorithm to improve search relevance and automatic spelling corrector—all to continue improving the overall search experience in Postman. We are hopeful about what’s next for the rapidly growing API ecosystem and confident that Postman’s universal search will play a crucial role in API discovery by the global API community.
What’s in the future?
This is just the beginning. We have tons of things planned for the future—like query understanding, a machine learning-backed algorithm to improve search relevance, and automatic spelling corrector—all to continue improving the overall search experience in Postman. We are hopeful about what’s next for the rapidly growing API ecosystem and confident that Postman’s universal search will play a crucial role in API discovery by the global API community.




What do you think about this topic? Tell us in a comment below.