
Open data APIs: standards, best practices, and implementation challenges
At this year’s API Specifications Conference (ASC), Postman Data Lead Pascal Heus gave a presentation on open data standards. Pascal has been working with data and statistical data management around the world for many years. In the past, he’s led both a company and a non-profit focused on metadata standards and best practices, and he has significant insights to share on this topic that he is deeply passionate about.
Managing data is an interesting technological challenge and is also a critical part of every society in the world. Data is everywhere. But is it being handled correctly? Read on for some of Pascal’s thoughts.
Using and storing data
We use data to make decisions about personal, professional, economic, and government matters. Data informs us about the state of our nations, the health of our planet, and where our economies are going. For example, at any given point in time, policymakers can use data when deciding to invest in agriculture, health, education, or infrastructure.
Data is a collection of strings and numbers that are stored in different formats, such as CSV files, SQL databases, Excel and Google spreadsheets, and more specialized formats like Stata and SPSS. These formats haven’t really changed since their introduction in the 1960s and 1970s. While we’ve added formats like NoSQL, RDF, XML, JSON, and key-value, most of the data is rectangular. To really work with the data, you need a lot more information, including context, quality, how it’s weighted, where it came from, and more. This knowledge isn’t stored with the data and it’s not always easy to find. In fact, it’s estimated that researchers have to spend up to 70% of their time looking for this missing information.
Data scientists and technologies like machine learning (ML) and artificial intelligence (AI) require digital knowledge. Because documentation does not accompany the data, there is currently an information gap, making it difficult to effectively analyze the data.
The following diagram is known as the DIKW Pyramid, and it depicts the relationship between data, information, knowledge, and wisdom. Data makes up the base of the pyramid and represents the files and databases where the data is stored. For data to be useful, it needs to be paired with information and knowledge about the data. This is where a gap currently exists.
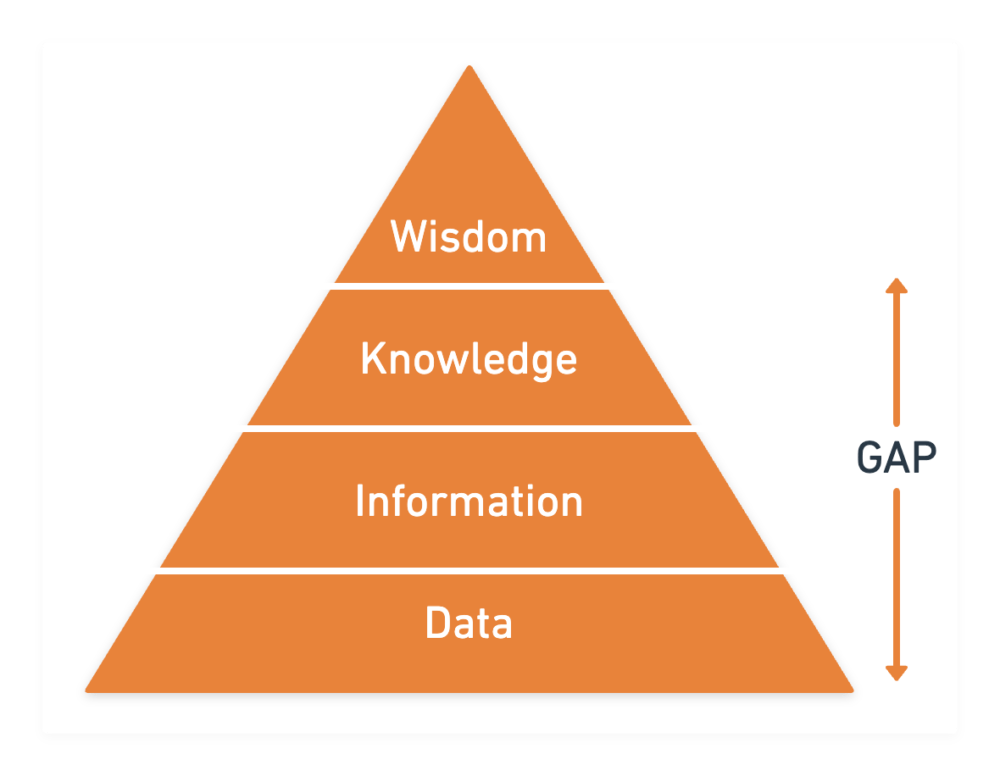
Turning data into digital knowledge
Pascal presented several great ideas to bridge the gap between data and knowledge:
- Supplement data with standards that are based on machine-actionable metadata and tools driven by ML and AI.
- Design and implement standard-driven findable, accessible, interoperable, reusable (FAIR) open data APIs.
- Foster collaboration between data custodians, scientists, and developers to encourage knowledge sharing.
- Pass the torch to the next generation of data engineers, scientists, and developers.
- Create a new breed of metadata and API-driven data management tools and infrastructure.
Understanding metadata
As Pascal pointed out in his talk, “Everybody knows metadata, and also, nobody knows metadata.” We need metadata for every decision we make. For example, when you’re at the grocery store, you review the metadata on a food label to decide whether or not to buy it. Today, the way we distribute data is a little bit like buying food that has no label.
Pascal went on to show an example of metadata surrounding the results of a survey. How do we know what to do with this data? What is it about? What questions were asked? Some of the results are also numbers that correspond to a key that is stored in a different file. Without the additional information, you can’t draw any smart conclusions from this metadata.
Developing metadata standards
Over the past two or three decades, there has been a lot of work done to develop standards for defining many different types of data science metadata. Many standards exist, but not all are robust and enterprise ready, and sometimes lack maturity, support, or tooling. Almost none of them have an official API.
To sort this out, a new initiative under the auspices of CODATA known as the Cross-Domain Interoperability Framework (CDIF) has recently been launched, working to agree on a small set of standards that work across different domains. Check out the video of Pascal’s presentation at the end of this post to hear more about the standards that are under consideration.
Making data FAIR and available
The FAIR initiative has been underway for several years and is recognized by most data producers, data custodians, data archivists, researchers, and data scientists worldwide as the agreed-upon reference. The FAIR principles basically say that everything should be identifiable. To make existing metadata FAIR (also known as the “FAIRification process”), you start with the metadata, capture knowledge about the metadata in a machine-actionable format, and then make it available through open data APIs. This process makes the data available along with the metadata that makes it meaningful. Visit the FAIR initiative website for more information on this topic.
Working together to make data meaningful
A good amount of work has already gone into defining metadata standards. The gaps that need to be filled now include tooling, infrastructure, and especially APIs—one of the reasons why Pascal joined Postman! Contributing in these areas can make a real difference in the data space, and the timeline is urgent.
Pascal shared some facts about the cost of using data that doesn’t comply with FAIR. According to a 2018 study, it is costing the EU tens of billions of euros each year that they continue to not use FAIR data. This cost comes from the time that researchers have to waste on solving data and storage problems instead of being able to do research.
We must work together to solve this problem. In the community of developers, data engineers, cloud architects, and API designers in the private sector, there is a great understanding of the technology, but not necessarily an understanding of the data itself. Data custodians, data scientists, and policymakers in the public, academic, and non-profit sectors have a greater understanding of the data, but often have limited expertise with technology. Bridging these two communities is what we need in order to move the FAIR data initiative forward.
What we can do as API designers
Pascal shared some actionable steps that API producers should take when making data available:
- Don’t manage or publish data without metadata, and preferably use FAIR/CDIF standards.
- Design and implement FAIR open data APIs to deliver digital knowledge instead of just data.
- Develop ML and AI toolkits to support both data producers and consumers.
- Collaborate, educate, and join the global efforts.
- Realize our dream and vision of a data-driven world.
Wrapping it up
Data is everywhere, but digital knowledge is what we need to drive effective research and unleash machine intelligence. We have the standards we need, but we’re lacking tools and APIs to move forward. Information technologists and data scientists need to work together to understand each other’s worlds. This work has a direct, global impact because, at the end of the day, data is about people, societies, and the well-being of our planet. We must work together to make data accessible and meaningful to make better, data-driven decisions that affect every part of our lives.
Watch the full presentation
Want to learn more?
To learn more about how Postman is getting involved with open data APIs, check out Pascal’s recent blog post about Postman’s Open Data and Research Intelligence Initiative.
Technical review by Pascal Heus.



What do you think about this topic? Tell us in a comment below.