
What is XML?
XML, which stands for “Extensible Markup Language,” is a data exchange format that is readable by both humans and machines. XML uses a hierarchical structure to represent complex, deeply nested data, and its extensibility makes it a great fit for applications that require compatibility with industry-specific data formats.
Here, we’ll discuss how XML works, review some benefits and challenges of using XML, and explore how you can work with XML in the Postman API Platform.
How does XML work?
XML relies on components, including tags, elements, and attributes, that are organized in a nested structure. This structure is designed to be just as easy for humans to read and understand as it is for machines to parse. Let’s review those XML components in more detail.
XML tags and elements
The data within XML documents is organized with tags. They come in pairs, like bookends—where <tag> is an opening tag and </tag> is a closing tag—and the data is stored between the two.
In XML, an element refers to the combination of an opening tag, some content or data, and a closing tag. This is an example of an XML element:
<name>Polly Postmanaut</name>
XML attributes
To provide additional information about an element, you can add an attribute to a tag. Attributes are frequently used to specify an element’s properties. Here’s an example of an attribute you might already be familiar with:
<a href="https://www.example.com">Click Here to Visit Our Example Site</a>
In the example above, the element (anchor) is using the attribute href (hypertext reference) to specify that the content being described is a link.
XML nesting
You can nest multiple elements in XML to create a hierarchical structure. The following example shows a collection of library books in nested XML:
<library> <book> <title>Introduction to APIs</title> <author>Polly Postmanaut</author> <publication_year>2023</publication_year> <isbn>212-1234567890</isbn> </book> <book> <title>API-First Development</title> <author>Cooper Newman</author> <publication_year>2014</publication_year> <isbn>415-0987654321</publication_year> </book> </library>
The example above describes a collection of two books and their attributes, including title, author, publication year, and ISBN. The collection starts with the <library> tag and ends with the closing </library> tag, and there is a set of <book> tags for each book. Each book’s attributes are nested inside these <book> and </book> tags.
The nested structure helps describe the relationships of these items to one another as books that belong to the same collection. As relationships between items become more complex, nested XML makes it easier to understand for both humans and computers.
How can you extend XML?
Once you have a strong foundational understanding of XML, you can start customizing XML documents to fit your specific use cases. For example, if you’re working with data that doesn’t have a standardized way to be defined in XML, custom XML allows you to create your own elements, attributes, and document structures (for the most up-to-date information about current XML standards, refer to the W3C XML 1.0 Specification).
Here are some other examples of ways you can extend XML:
- Metadata and annotations: You can include metadata like comments, instructions, or additional information about processing or working with your data.
- XML namespaces: XML namespaces can help you integrate XML data from multiple sources in the same document while avoiding naming conflicts.
- Transformations: If you need to convert your XML data into a different format or structure, you can use transformation technologies like Extensible Stylesheet Language Transformations (XSLT).
- Data exchange schemas: You can use schemas like Document Type Definitions (DTDs) and XML Schema (XSD) to define rules and formats for exchanging data between different systems, organizations, and platforms.
- Industry-specific profiles: Several industries have defined their own XML standards, including Extensible Business Reporting Language (XBRL) for financial reporting and compliance data, Health Level 7 (HL7) for healthcare data, and Geography Markup Language (GML) for geographical data.
Extending XML is often a way to make sure that the data can be shared across systems with as little friction as possible while keeping the data secure and compliant. For example, we could extend the earlier library example to include data from a different namespace:
<library xmlns:pub="http://example.com/publication-dates">
<book>
<title>Introduction to APIs</title>
<author>Polly Postmanaut</author>
<publication_year>2023</publication_year>
<isbn>212-1234567890</isbn>
<pub:date>2023-01-15</pub:date>
</book>
<book>
<title>API-First Development</title>
<author>Cooper Newman</author>
<publication_year>2014</publication_year>
<isbn>415-0987654321</publication_year>
<pub:date>2014-05-20</pub:date>
</book>
</library>
In this example, the root <library> element declares a namespace using the xmlns attribute and gives it the name pub. Within each <book>, elements with a pub: prefix contain data from this namespace, such as <pub:date>.
What’s the difference between XML and JSON?
XML and JSON are both popular data exchange formats. Although they may serve a similar purpose, the syntax and structure of JSON and XML documents are vastly different. XML can describe nested data through the use of tags, elements, and attributes, while JSON uses key-value pairs with a syntax resembling JavaScript objects to allow web apps to exchange data efficiently.
For example, this XML object describes a person with some basic contact information:
<person> <name>Schema Smith</name> <age>24</age> <contact> <email>[email protected]</email> <phone>555-123-4567</phone> </contact> </person>
Here is the same data represented as a JSON object:
{
"person": {
"name": "Schema Smith",
"age": 24,
"contact": {
"email": "[email protected]",
"phone": "555-123-4567"
}
}
}
While both formats are meant to be easy for both humans and machines to understand, XML is more verbose. JSON uses a more minimalistic syntax that is still very human-readable, but its simplicity is optimized for machines. With these differences in mind, it makes sense that XML is commonly used for documents and complex data structures, whereas JSON is more often used in web and mobile app development, data serialization, and real-time data exchange.
Another key difference between XML and JSON is in their native data types. By default, XML treats all data as text, while JSON has native support for other data types, such as strings, numbers, booleans, arrays, and objects. This might make JSON more intuitive for developers who are already accustomed to specifying data types, but XML might offer greater compatibility with a diverse set of data sources where the data types may be unknown. While JSON supports more data types natively, XML can support rich data types using custom extensions.
What are the benefits of using XML?
The benefits of using XML for data exchange include its structured format, established industry standards, and extensibility. All of these characteristics allow for interoperability between different systems and applications, which is essential in the context of APIs. The hierarchical structure of XML provides a way to organize information in a logical way and represent complex data relationships. For example, if you have a large set of interconnected data that needs to communicate with an e-commerce API, it’s critical to have a standardized way of defining the relationships within the data.
As mentioned earlier when we discussed extending XML, many industries have already established XML data exchange standards that meet their specific needs. The rules for working with data in sectors with a lot of regulatory requirements, such as healthcare, aerospace, finance, can be strict and expansive. By adopting XML-based standards together as an industry, these sectors can exchange data in a consistent, accurate, and efficient manner. It’s a great way to make sure that an organization’s internal systems can interact with one another, share data, and talk to other external systems—frequently through APIs.
What are some challenges of using XML?
Some of the challenges of using XML include its document size and complexity, verbose syntax, and parsing overhead. XML’s opening and closing tags for every element can feel redundant in comparison to more minimal formats like JSON. These same tags, which make XML more readable by humans, can also make the document seem bloated. When you’re working with a deeply nested document of structured data, it can become difficult to navigate and edit.
The complexity that comes with XML can also lead to larger file sizes, which increase the time it takes to transmit and process them. Compression algorithms are often built into client and server transport layers to speed up the transport of these files, but the time saved on transport might be spent compressing and decompressing the data. If your application depends on fast, low-latency performance, the resource overhead associated with parsing XML documents can pose a challenge. While you can implement parsing libraries to speed up this process, it’s still going to require more resources than a more lightweight data exchange format that uses a faster serialization process.
How can you use XML in Postman?
There are many ways to work with XML data in Postman, both as an API consumer and an API producer, such as specifying XML as the content type in the request header.
Requesting XML data from an API
When you send an HTTP request to a public API, you can use the Accept HTTP header to indicate the type of content you’d like to receive. If the API supports that content type, then you’ll receive the response in the format you requested.
For example, to request XML data from an API in Postman, select the request and navigate to the Headers tab. Add a key named Accept with the value application/xml. Read more about configuring request headers in the Postman Learning Center.
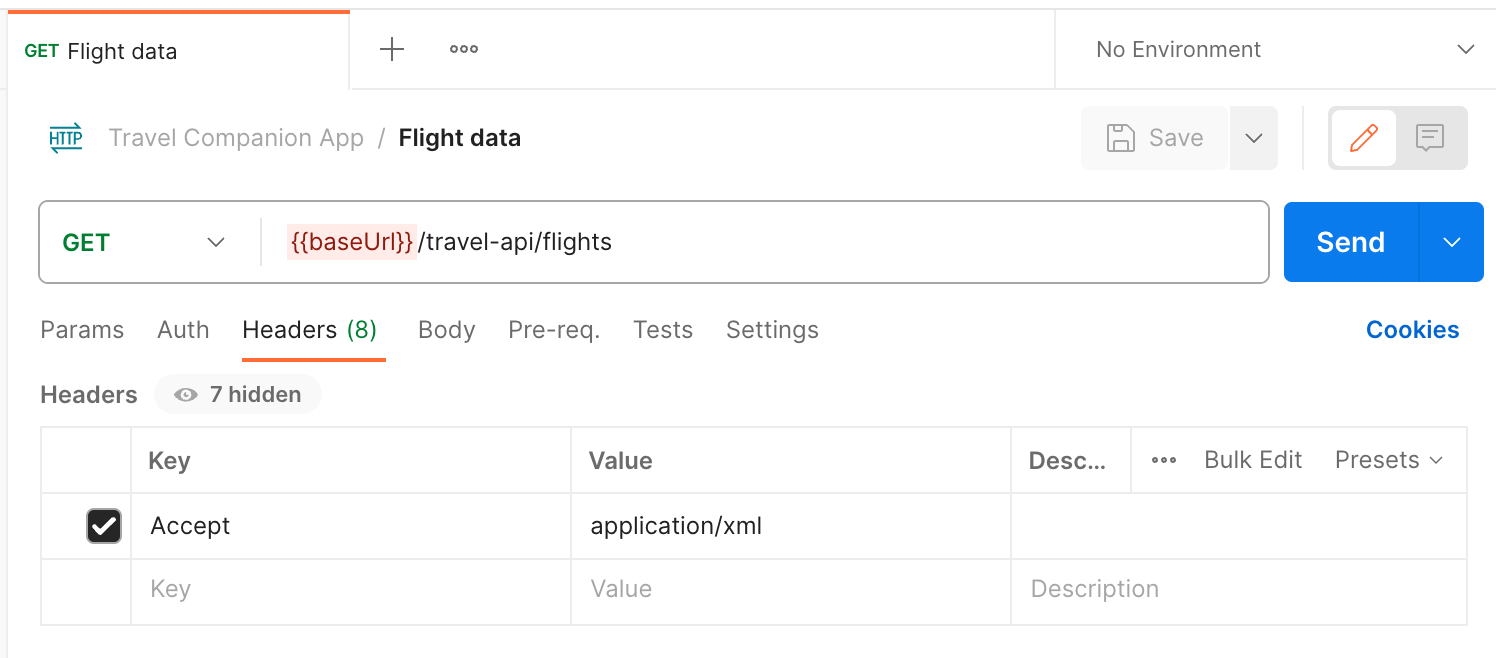
Sending XML data to an API endpoint
If you’re sending data to an API endpoint via a POST or PUT request, you can also specify the type of content you’re sending using an HTTP header. Similar to the previous example, select the request and navigate to the Headers tab. Add a key named Content-Type with the value application/xml.
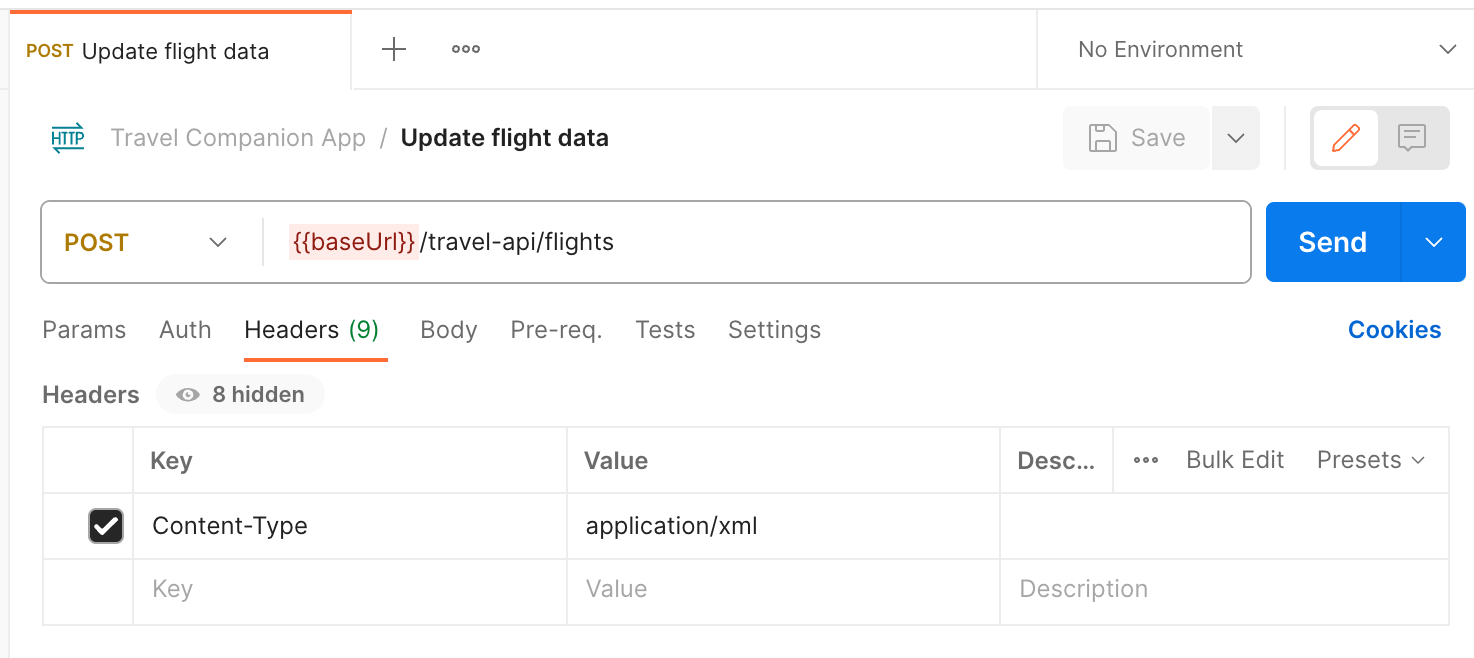
Supporting XML requests
To support XML as an API producer, you must configure API endpoints to accept XML data in requests. If you also want to support JSON data, you can try an approach like APItude by Hotelbeds did for their BookingAPI collection, which includes both JSON and XML versions of each request.
Closing thoughts on XML
In this article, we looked at the fundamentals of XML and its ongoing role in data exchange. We discussed how XML works, compared it to similar technologies like JSON, and went over its benefits and challenges. Additionally, we looked at how you can leverage XML when working with APIs in Postman, whether you’re an API producer or consumer. Now that you have a solid understanding of the basics of XML, you’re in a better position to navigate the diverse landscape of data exchange in today’s API-first world.
Technical review by Ian Douglas.


What do you think about this topic? Tell us in a comment below.