
Introducing Postman’s Open Data and Research Intelligence Initiative
Data has become a digital commodity that we can no longer survive without. It drives our global economy, national and international policies, and scientific innovation. It is fundamental to the media and the press to keep the public informed, and it underlies our education systems. We use it in our day-to-day life for personal or family decision-making. Almost all choices we make today, whether for ourselves or to decide the fate of our planet, are driven by digital data.
Our data tools have evolved from the Ishango bone and good old pen and paper, to information systems capable of crunching numbers at incredible speed and applications performing amazing analytical feats. Machine learning is rapidly evolving and we dream of artificial intelligence and metaverses.
But are we doing it right? Is data as we know it what it needs to be to fulfill our expectations and unleash the full capabilities of today and tomorrow’s information technologies? Surprisingly, the answers seem to be no.
It is well known that data scientists, rather than doing research, spend the majority of their time data wrangling (looking for the information they need or reorganizing data in useful ways). Application developers commonly have to invest a significant amount of effort to access data across too many formats, supplementing it with user interfaces to make it understandable. Simply finding the data we need seems to be challenging. Why is that? What are we doing wrong? What can we do better?
The core issue is that the way we typically store and manage data falls short of meeting our needs. Data commonly lives either in files of databases, essentially raw physical storage for strings and numbers. While such formats are efficient for processing or querying, they tell us nothing about the data besides some minimal information about its structure.
To do something meaningful with data, we need to understand what it is about, where it comes from, how it was collected and produced, its geospatial and temporal characteristics, and many other fundamental attributes. We also need to share this knowledge with others. This is commonly referred to as “metadata” and has a tendency to exist in various publications, documents, email threads, or simply in people’s heads. As a result, it does not come alongside the data, and can actually be very hard and cumbersome to find. Furthermore, such metadata is rarely machine-actionable, so it remains out of reach of computer applications, keeping the knowledge away from information systems, and pretty much reducing machine intelligence to the role of a pocket calculator. This also precludes the concurrent delivery of data and metadata through APIs.
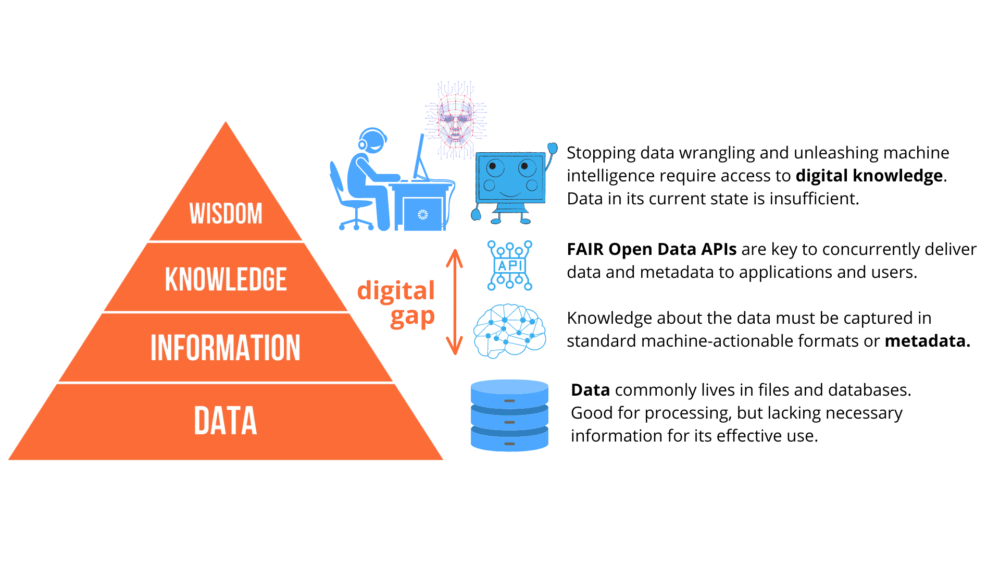
Using the data, information, knowledge, wisdom (DIKW) pyramid to illustrate this situation, databases and files lay at a lower level, with a small intrusion in the information layer. The wisdom level is where users, researchers, data scientists, applications, and intelligent computer systems live, doing the grinding and thinking. The knowledge and information levels are the weak points and show the gap that needs to be filled by metadata and APIs. This is why we need to elevate data into digital knowledge.
The good news is that there are ways to address this data incompleteness issue. Metadata standards and related best practices are available to us to capture knowledge in machine-friendly formats, the GoFAIR initiative being globally recognized by data and scientific communities as a reference. And naturally, we have the know-how and expertise to design and implement necessary APIs to manage and deliver.
How Postman’s Open Data and Research Intelligence can help
The key is to turn all this into reality, which is a challenge we are looking to help undertake at Postman. To do so, we are introducing, under the umbrella of our Postman Open Technologies program, a new Open Data and Research Intelligence (ODRI) initiative.
Built around three core challenges—science, data, and machine—the initiative aims to produce rich data-oriented OpenAPI specifications, open source tools, training and reference materials, and more, all to support the establishment of global web services-oriented infrastructures for delivering data and metadata to both machines and researchers.
This work will build upon globally recognized data management standards and best practices, and it will be accomplished in close collaborations with scientific communities, data agencies, private sector, and academic partners.
Turning passive data into an intelligent commodity is key to fostering sound scientific research, and enabling machine learning and artificial intelligence, so humans and computers can work hand in hand.
As data lead at Postman, I feel privileged to spearhead this work. Concrete actions will include the establishment of collaborative API workspaces (such as current workspaces focused on COVID-19, Digital Representation of Units of Measurement (DRUM), and CMS Price Transparency), synergistic activities with data custodians and scientific communities (like CODATA, FAIR, Research Data Alliance, World Data System, or the Open Data Institute), exploring machine learning and AI tools and techniques to build intelligent data solutions, and sharing stories and experiences through various blogs, videos, and social networks.
Through the Open Data and Research Intelligence initiative, Postman aims to contribute to the global modernization of data management—and ultimately make our world a better place. Stay tuned for updates on this exciting new endeavor. And if you have any questions or suggestions about this initiative, feel free to leave me a comment below.



What do you think about this topic? Tell us in a comment below.