
How We Built Docu-Mentor to Win the Postman API Hack
This is a guest post cowritten by Carson Hunter and Andrew DeCarlo, software developers at Metadata Technology North America.
Earlier this year, we were honored to win the Postman API Hack Intergalactic Grand Prize, which was announced at the Postman Galaxy global conference in February. As two long-time Postman users (and fans), we jumped at the chance to create a project using the API platform and dive deeper into what is possible with the new public workspace functionality. With our resulting creation of Docu-Mentor—whose tagline is “Documentation review, without the judgment”—ultimately earning top nods, we thought it would now be fun to walk through the process of how we came up with the idea and what we learned along the way.
Brainstorming a problem to solve
With the contest prompt instructing us to create something that would make developers’ lives easier, we talked over what our pain points were in our current Postman workflows and how we might be able to solve them. We’ve done some work with generating Postman Collections as documentation using the Postman JSON schema and the resulting Java models, but one thing we found we missed from our previous Swagger/OpenAPI docs were the expandable and linkable object models for request and response bodies, as shown below. The saved response feature in the Postman documentation view is great for seeing what comes back from an API, but describing a request body and giving context to each property in both request and response object models isn’t as easy of a process.

In the past, we had played around with creating some similar model descriptions in Postman by creating markdown tables by hand, but talk about tedious and error-prone…oof. It wasn’t something that was easily maintained or updated, so it quickly became a pain point.
Andrew threw out the idea of trying to generate these tables automatically: Could we extract what we needed from request bodies and saved responses stored in Postman Collections? And then take it one step further and link to the requests where they are used? This would prevent the confusion-scrolling that sometimes occurred in our larger docs, but we knew that linking within the generated HTML documentation page would be tricky. We weren’t exactly sure if or how it would work from the beginning, but decided to run with it and see where we got.
We kept brainstorming on the documentation theme, as we wanted to take it a step further and utilize the multi-collection capabilities that public workspaces offered.
When we were thinking through our documentation process and how it could be improved, one thing that came to mind was keeping track of our collections and how far along they are in the documentation process. Since we’ve used Postman in our work as employees at Metadata Technology North America (MTNA) for years, our number of collections and workspaces has grown steadily. Keeping up with our public-facing collections and making sure they meet our standards for documentation can be tedious, especially with multiple people contributing. It was just one of those tasks we had resigned ourselves to thinking couldn’t be automated.
Once we started thinking about it in terms of the Postman JSON schema, however, it dawned on us that maybe this was something that could be somewhat automated—we were already programmatically adding in documentation for our collections, so why couldn’t we test for it? With a few iterations, this idea evolved into a to-do list for keeping track of documentation progress on a collection.
With a rough plan in place, we split up the work: Andrew would work on the object model generator, and Carson would work on the documentation monitor (which came to be known as the Documentation Assistant). Over the course of a couple weekends, the projects came together.
Executing the project
Andrew explains the model generator
One of the big things we like about using Postman is that unlike the Swagger/OpenAPI UI, we can document the flow of how the API is intended to be used, not just list out the available methods. When it comes to connecting the dots for our frontend team, the last piece of the puzzle is describing the objects that are used in the API, where they are used, and what the intended purpose of the objects’ properties are.
Typically, to fill this gap, I need to point the members of our frontend team to the BitBucket repository of our Java code that is serving up the responses. Then it’s up to them to dig through the repository and look through the Java docs on our models to understand what everything is and how it is meant to be used. While this works, it isn’t always ideal. Members of the frontend team constantly have to revisit the Java code to reference the docs or see where they are used in the different requests. It would be nice to have the documentation of the models alongside the requests that use them—all in one spot for everyone to see.
The Docu-Mentor model generation capabilities built for the 2021 Postman API Hack were really just that, a hack we came up with to deal with this issue. Carson had tried to solve this problem a few years ago in some of our collections by handwriting markdown tables that listed the properties of the models in different requests descriptions. For the hackathon, we built on that idea to automate the solution. By inspecting the JSON request and saved responses in a catalog, we have all the information we need to know about the models. In addition to descriptions of the models and their properties, we also wanted the models to link to each other and to the requests that they were used in.
To accomplish this, we decided Docu-Mentor would add a dedicated “API Models” folder to the collection it was working on. This would keep the models separate from all the other requests and give users a consistent place to locate the models across any collections that use Docu-Mentor. Each request in this folder is dedicated to a unique request or response body that was found in the collection. Docu-Mentor generates a markdown table with a column for the name, description, and data type of each property in the model. If the data type is another object, the parent model provides a link to it. To take it a step further, each model also links to the requests it is used in and specifies where it is used (the request or the response). By doing this, we provide users with the ability to jump back and forth between models and the requests that use them. The ability to link between requests is especially nice in the published Postman documentation, which really provides a great way to view these models.
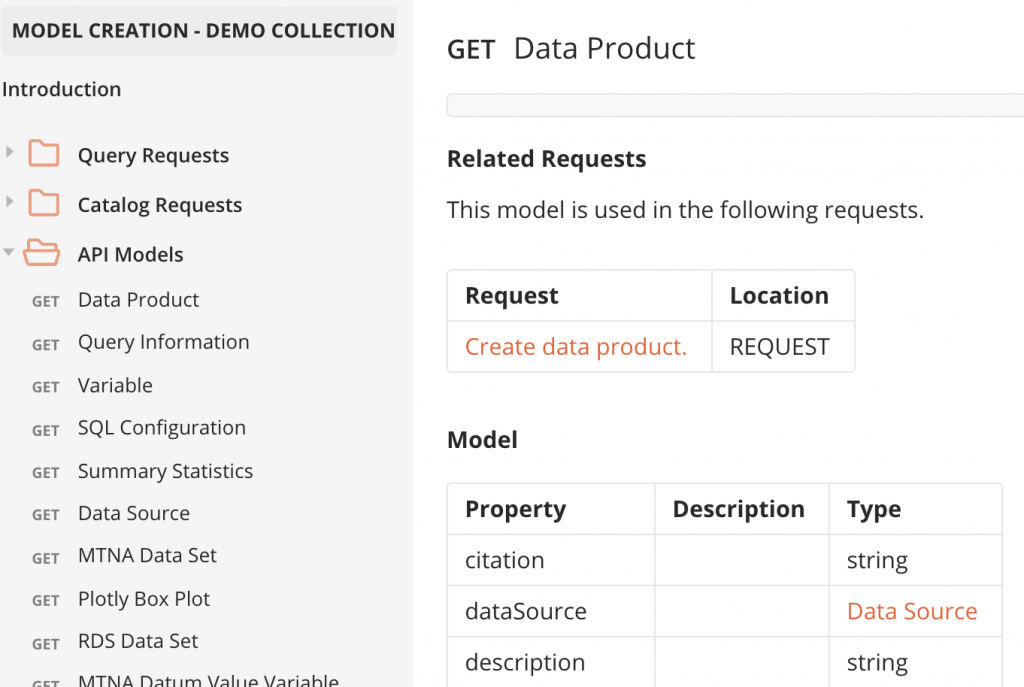
If you would like to try the model generation collection for yourself, it is available through our public workspace here. The documentation on how to use it is included in the collection and request level descriptions.
We hope Docu-Mentor provides Postman users with a way to not only document the models that are used in their APIs, but also to explore interacting with the Postman model itself to design apps and utilities that benefit Postman and the API community. Docu-Mentor and the Java model it uses to parse and update the collections are open source and available through our Github repository.
Carson explains the Documentation Assistant
Over the last year or so, we had done some work around identifying what we thought made for good Postman documentation: adding detail at the collection, folder, and request levels, as well as expanding on each parameter of a request—so I already had a solid rubric to grade our collections against. I wrote up a quick proof-of-concept script in the Tests section of a request that used the Postman API to return a sample collection’s JSON representation. The script went through each item in the collection, checking if it had any documentation attached.
Though we had originally planned to write the whole project in Java and create REST API endpoints to do all of the work (since that’s our day-to-day tech stack and what we’re most familiar with), the ease of writing the initial scripts in Postman JavaScript made me question if Java was the right choice for this portion of the project. I ultimately decided to keep this portion of the project written entirely in Postman to make it as easy as possible for other users to adapt the collection for their own use, and to push the limit of what we thought Postman could do.
To report the results of our collection checks, I made both a Postman Visualizer table output that users could check while they’re working inside the Postman app, and a custom Slack message reporting on what was left to be documented. I calculated a simple completion score or “grade” by taking the number of completed tasks and dividing by the total number of tasks available. I thought this could be a good way to kind of gamify the often tedious job of documenting every aspect of a collection and give a more concrete metric that I could report when asked how far along I was on a project. “75% completed” sounds a lot better than “It’s, uh, getting there.”
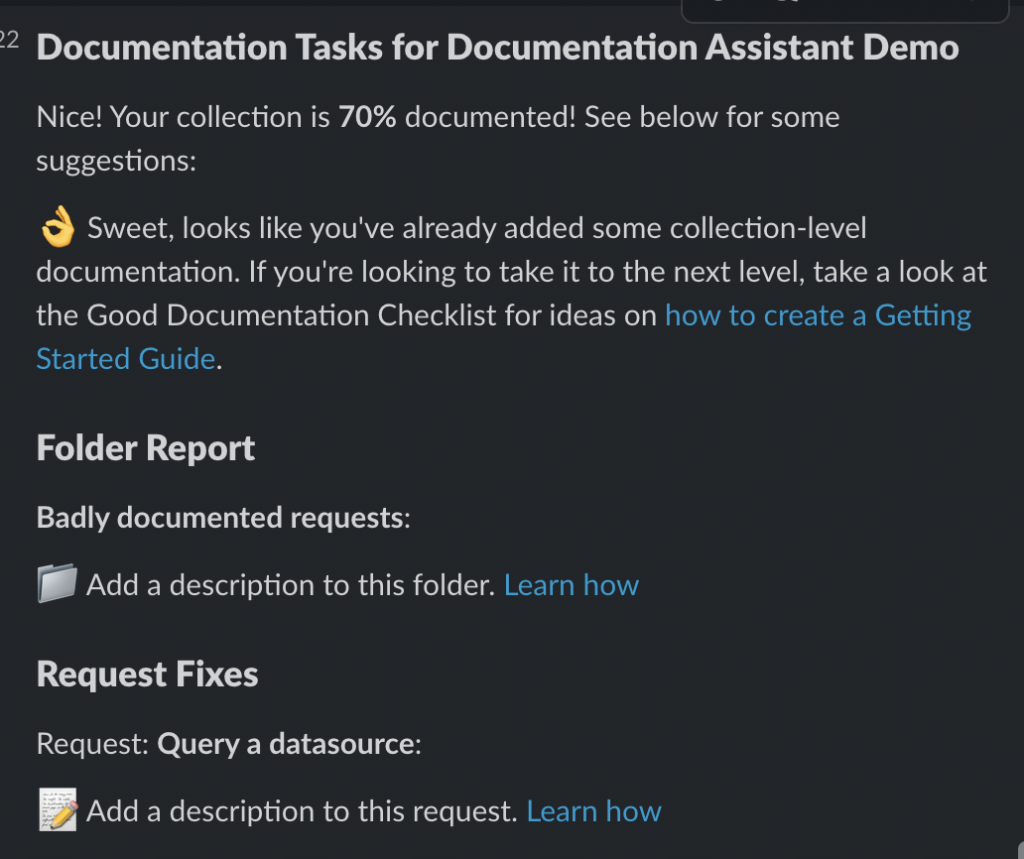

At this point, we basically had a collection report card. Pretty cool, but how many teams would only be working on one collection at a time? After a little more scripting and shuffling around some environment variables, we came up with an all-encompassing workspace report card as well, giving each collection an emoji grade based on its score. This would give teams a broader view of their progress, and they’d then be able to dive into the details of an individual collection’s tasks if they needed to. Plus, with the added functionality of Postman monitors, they could get a report about a different workspace each day, allowing them to keep an eye on their entire Postman ecosystem.
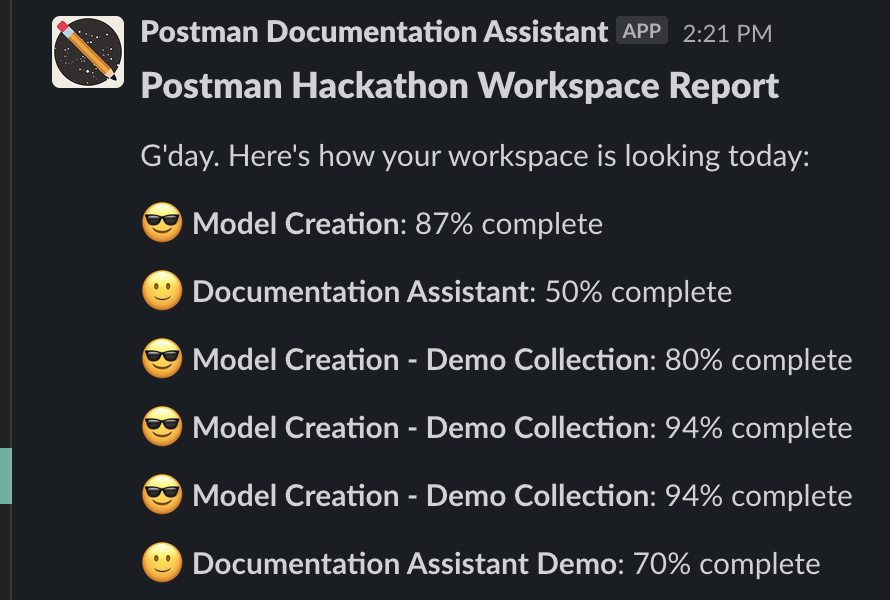
Though building the utility in Postman had the limitation of only being able to send one-way webhooks to Slack instead of facilitating an interactive conversion, it turned out to be a pretty cool way of quantifying documentation and hopefully a useful tool that others can adapt and build on. If you’d like to try it out for yourself, there are instructions for setting up the utility either with or without the Slack integration, all on our public workspace page.
Submitting Docu-Mentor to the Postman API Hack
To wrap up the project, we spent a lot of time documenting everything we had done—this seemed like something we had to get right since we had built our whole project around the premise of helping others write excellent documentation. This was the first time we had really built out a public workspace home page, and it turned out to be the perfect landing page for laying out instructions for multiple projects, showing how they fit together, and then allowing users to veer off in the directions they choose. The page was pretty text-heavy with so many instructions, but we did our best to break it up using markdown lists and headers. We then recorded a video walk-through, filled out our DevPost page, hit submit, hoped for the best, and spent the next couple of weeks browsing the other incredible projects that had been submitted.
The announcement day finally came: We tuned in to Postman Galaxy to watch Postman Chief Evangelist Kin Lane’s livestream and we were shocked to hear we won first place. We couldn’t have been more excited, and we remain really grateful to Postman, DevPost, and the judges for putting on such an enjoyable event.
Even though the contest is over, we hope to keep adding to Docu-Mentor’s two components as we integrate them into our own workflows—and we would love for you to use them for yourself and your team to see how it can help you. Don’t forget to let us know what you think: We hope to see you and your feedback in the public workspace comments.


What do you think about this topic? Tell us in a comment below.