Codebase Postman Integrations: How We Crafted Cloud Connections

This is a guest post written by Codebase, a UC Berkeley student organization that builds software projects for high-growth tech companies.
Codebase is a UC Berkeley student organization that builds software projects for high-growth tech companies. During the Spring 2021 semester, we worked with Postman to develop a Postman public workspace containing several cloud integrations that use technologies such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). The result was the Codebase Cloud Integrations public workspace. In this blog post, we’ll share our experience working with Postman—detailing what we learned throughout our development process and the challenges we faced along the way.
A tale of two teams and one development process
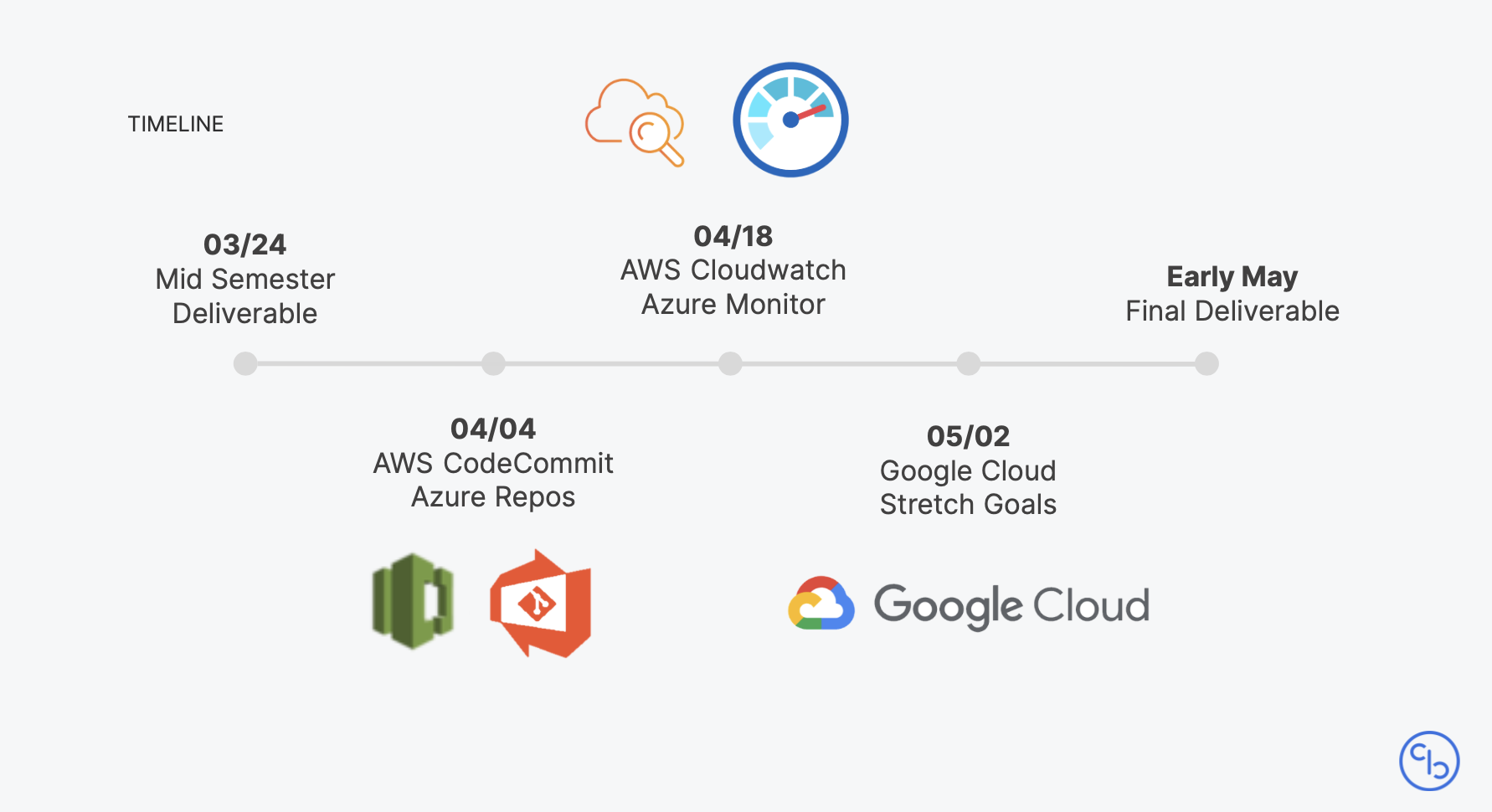
To chart a clear path for this large endeavor, we divided the project into multiple stages throughout the semester—starting with an onboarding project and then working in small groups to tackle each integration in weekly sprints. We remained in close contact with the Postman team during the entire development process, holding weekly standups with two of Postman’s developer advocates, Sean Keegan and Arlémi Turpault. In addition, we consistently provided updates and asked questions within a shared Slack channel to clarify any blockers we faced.
Our standups were every Monday morning, during which we presented our work from the previous week and discussed any questions that we had in regards to using Postman. One of the biggest areas of confusion, especially for us on the Codebase team, was understanding and utilizing the full power of mock servers to our advantage. When we brought this up to Sean and Arlémi, they not only helped us clarify our initial questions during standup, but they arranged for times outside of our weekly meetings to further clarify and aid our comprehension.
We also worked closely with the Postman team to ensure conventional usage of different cloud services (such as Azure) and appropriate access within our Postman accounts. Our project culminated in two formal presentations (live and recorded) to Postman employees; we presented halfway through the semester and again at the conclusion of the project. People from around the world tuned in, with teams based in the United States, the United Kingdom, and India.
Key learnings and takeaways
The power of research and documentation
Throughout the process of building our Codebase cloud integrations, we learned a lot about AWS, Azure, and GCP. And while we gained a deeper technical understanding of each cloud service provider, we also gained valuable experience conducting research. We constantly read and learned from any documentation we could find, and we followed many tutorials and guides to fill in information gaps during the development process. In particular, the Postman API documentation allowed us to familiarize ourselves with the Postman API platform quickly and effectively, and focus our efforts on researching our approaches to our cloud integrations.
Overall, the usage and implementation of the different cloud services were relatively similar in terms of concepts, workflows, and information needed to complete each integration. The main difference between the cloud services were the authentication methods and the documentation. Some services we worked with had better documentation and were more popular with the public, resulting in the corresponding integrations being slightly easier to create. For example, when we were creating the Website Management Integration, AWS Cognito was much better documented than Azure Active Directory B2C, which made the latter integration much more challenging.
At the start of this project, many of us were new to Postman and the technologies that we were interacting with, so doing proper research was critical. At times, finding documentation for what we wanted to accomplish was easy—sometimes simply searching for a certain key phrase would output clear steps for exactly what we wanted to do. Other times, as with the Azure Log Collection Integration, we weren’t exactly sure what services we should be utilizing. It was particularly frustrating since many of the services sounded like they would allow us to complete the functionality, but unfortunately fell short. Oftentimes, this was due to a lack of information. In searching through the various technologies we were using, certain endpoints and services were poorly documented, with some not even fully completed. There were several instances of blank descriptions for request headers and URI parameters that we found while working on the project, which confused and frustrated us. Nonetheless, we learned and bonded over the process of researching. We had one particularly fun surprise that we like to look back on: when we were searching for faker variables in mocks, we came across a Quora article in Russian that ended up being super helpful for debugging.
As a result of these experiences, we learned the importance of good documentation. So, to create a better experience for our users as they explore our own public workspace, we made sure to thoroughly document every step we took in creating the integrations.
Mock servers and dynamic variables
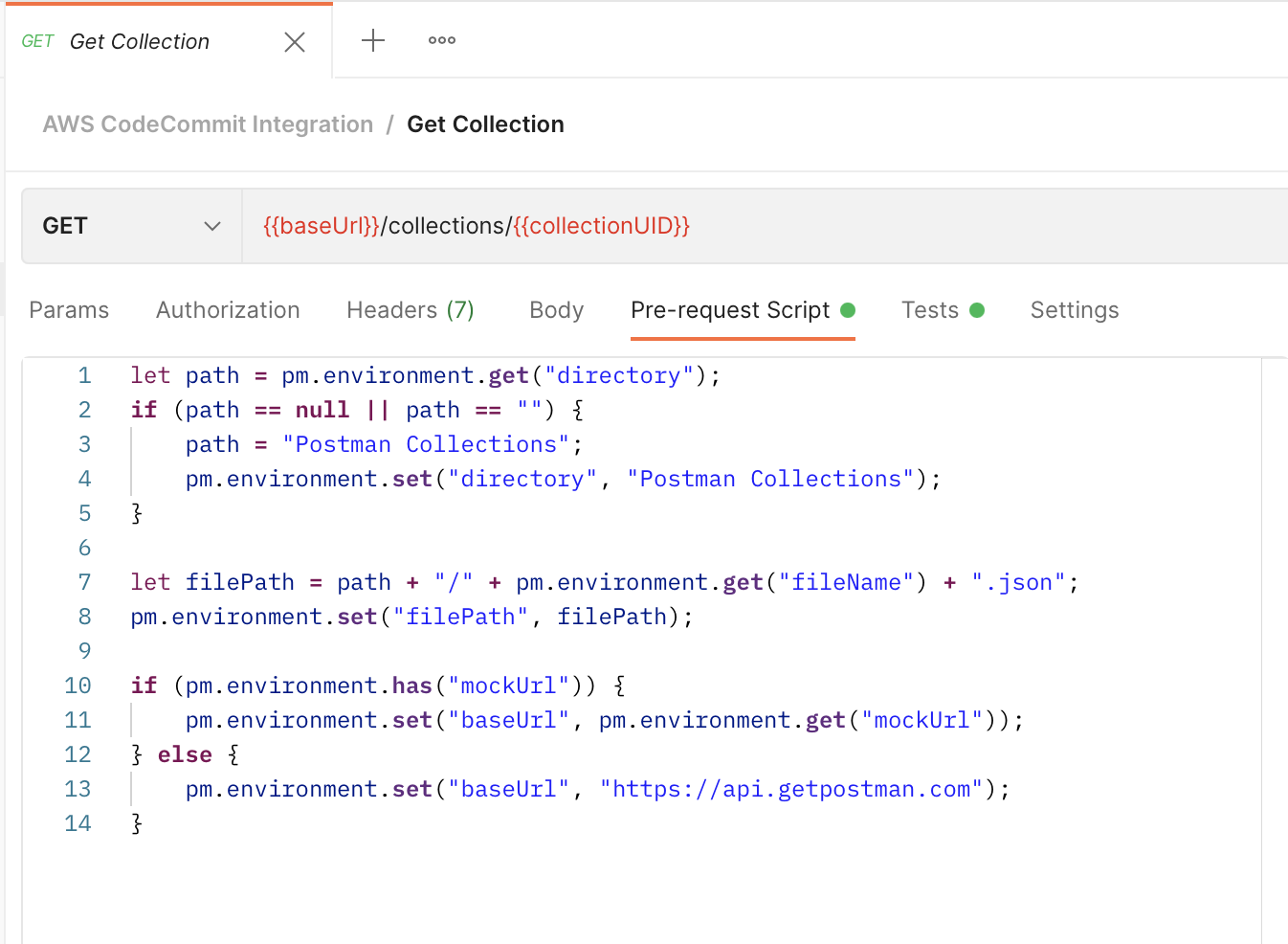
In order to give the user a feel for what kinds of responses our services give, we built in logic that allows for easy integration of mock servers and environments. This process was a lot of fun, as we got to familiarize ourselves with some cool Postman features. For example, our mock responses are tailored based on mock environment variables by inserting these as dynamic variables into request examples. In addition, Postman also allows a single request to return one of multiple examples. This enables us to return examples of successful responses as well as error responses if the user forgets to input a necessary variable into the mock environment.
We were also excited by Postman’s integrated random environment variables, which allow mock requests to have randomized output (such as timestamps) without any extra code. This feature is powered by the built-in faker.js library, so users can customize possible responses in their request script. Our key takeaway? If you can think of it, there most likely exists a Postman feature for it!
In order to make switching between mock servers and regular use as seamless as possible, we added logic pathways for the code portion of all requests so that any request works with either environment. During this process, we quickly realized that mock server requests required more background guidance, as we had to ensure that all of the requests in a collection could run in order. An interesting consideration was how much of the process we wanted to make obvious to the user—we decided to focus on accessibility. The result is that the user doesn’t have to worry about implementation as much but can still “look under the hood” if they want more customization.
Trial and error with Google Cloud Source Repos
One of our stretch goals was to create a Google Cloud Source Repos Integration similar to our AWS CodeCommit and Azure Repos Version Control Integrations. While we thought it would be a simple task, we ended up running into several issues along the way. We eventually decided not to pursue the integration as fully as the others. Here’s why.
In our first attempt, we tried finding the correct API calls to make, thinking there would be a simple set of endpoints we could hit to achieve the desired functionality. However, after looking into the documentation, we realized that this approach wouldn’t work because Google Cloud doesn’t allow uploading or managing files through API calls. Instead, there was only an endpoint that allowed for creating new repositories. This is because the intention of this API is only to allow users to create a remote repository from which they can execute normal git commands from their terminal to add files and manage branches.
Knowing this, we explored the possibility of using Postman to inject commands into a user’s terminal, but this required creating an empty git repository in a user’s laptop and transferring data over from Postman to this repository. Additionally, we tried a workaround that involved importing libraries into Postman and forcefully running terminal sudo commands. We eventually found this process too invasive, as we were trying to modify the contents of a user’s laptop. Another consideration was that the libraries we used were inconsistent across Windows and Mac. As a result of these issues, we decided it was best not to pursue the integration and instead focus our attention on polishing the other parts of our workspace.

Creating a custom policy for the Azure Log Collection
Another challenge we ran into was with our Azure Log Collection Integration. The collection retrieves API call logs from Azure API Management, and recreates requests from the logs in Postman. However, retrieving the logs from Azure using a REST API proved to be more challenging than we originally thought, since the REST endpoint was still in development with preliminary documentation.
After exploring a few different approaches, we realized that the first step of logging the request information in Azure also required a complex setup between multiple Azure services. In addition, many of the services we considered were premium Azure services, which we wanted to avoid because we were creating these integrations in a public workspace. As a result, we implemented a workaround that used only Azure Blob Storage to store logs (rather than Azure Monitor, Diagnostic, or Activity Logs). We wrote a custom policy for incoming calls into the API, which logged all essential information to a container in Blob Storage, from which we retrieved the logs in Postman and parsed them. While this method requires a significant amount of setup, we are proud to have overcome this challenge to develop this integration within our means.
Conclusion
We are extremely grateful to have had the opportunity to work closely with Postman this past semester in order to develop Postman cloud integrations and leverage fascinating, cutting-edge cloud technologies. A huge thank you to Postman’s team of Sean Keegan, Arlémi Turpault, and Joyce Lin for all of their help and guidance along the way. If you are interested in exploring more of the technical details of our integrations, please check out our recent blog post or dive straight into the Codebase Cloud Integrations public workspace.



What do you think about this topic? Tell us in a comment below.