
What is caching?

This is a guest post written by Allen Helton, ecosystem engineer at Momento.
“It’s probably a caching issue.”
No matter how long you’ve been in the software industry, you’ve probably heard that statement before. Next to “Did you try turning it off and on again,” it’s one of the top excuses for random software problems. Caching is a quick and easy scapegoat for when something that was working fine blows up all of a sudden.
They say the two hardest problems in computer science are naming things and cache invalidation. I can personally vouch for the difficulty of both of these things. There’s a lot to caching and none of it is particularly intuitive.
So, what is caching?
Caching is a technique that involves temporarily storing data to avoid loading it more than once. Often kept locally or in-memory, a cache prioritizes speed over durability. Cached data is meant to be available in an instant to provide lightning-fast performance.
By caching data, you can improve your application’s performance while reducing network calls, database strain, and bandwidth usage. These benefits make it a great pattern to implement.
Caching is everywhere. Server-side, client-side, browser caching, and proxy/CDN caching are all opportunities for you to take advantage of the concept. Each layer can temporarily store data, making your app faster no matter how it’s used. That said, caching can also add complexity all the way down your stack.
The anatomy of HTTP caching
Most people associate caching with databases. They aren’t wrong; you can and should cache database calls. But that’s not the only way you can add caching to your app.
Remember: caching is the practice of temporarily storing data to minimize redundant calls to your app, which includes your API.
Imagine you have a website that tracks how busy local restaurants are. Restaurants send your website new data every 10 minutes, which includes information like current capacity and average wait time. Your website then serves that information to users so they can make informed decisions on where to eat.
The website’s high-level architecture is depicted below:
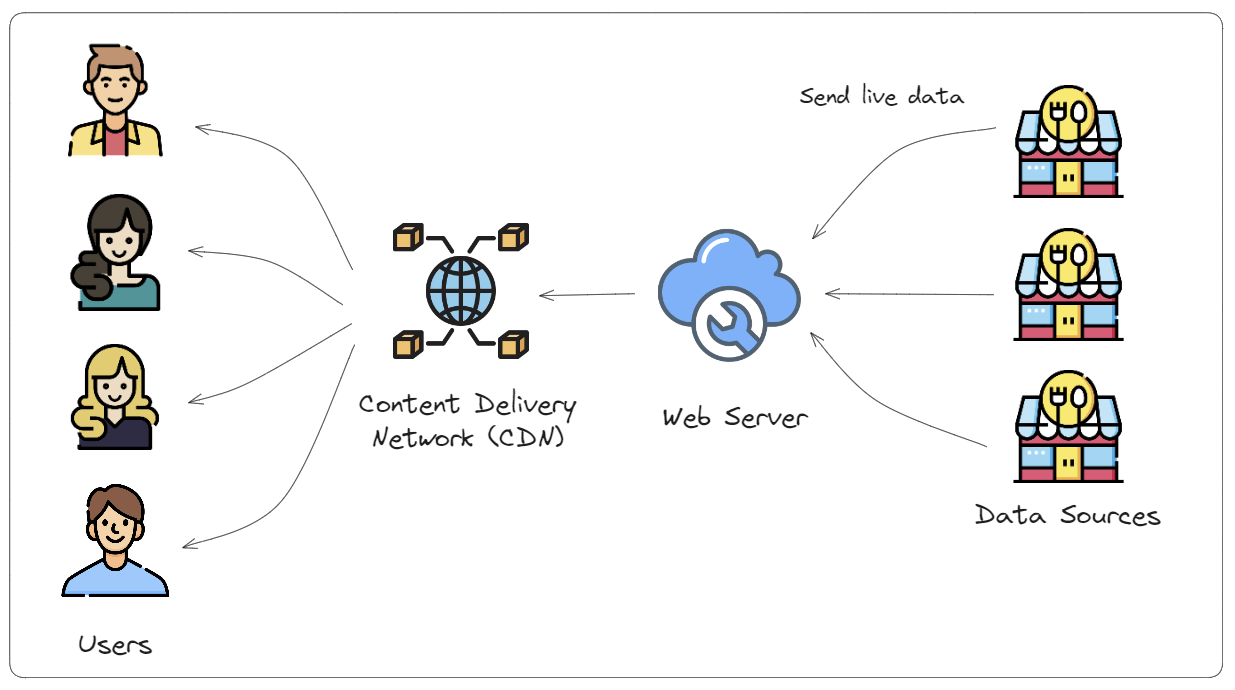
Server-side caching
When you receive data from restaurants, you normalize the format and save it to your database with a lastUpdated timestamp. We know this data is only valid for 10 minutes, so we then put it into a centralized, remote cache like Momento or Redis.
The act of saving data to a durable store like a database before saving to a fast, temporary store is called write-aside caching. We save the data to the cache as we write it, ensuring it’s there when we go to fetch it later.
On the flip side, we could lazily add the data to the cache. On the first fetch of the data, we check if the data is already in the cache. If it’s not, we get it from the database, save it to the cache, and return the data back to the caller. The next time someone tries to load the data, it comes out of the cache and the call to the database is skipped. This approach, which is called read-aside caching, is used more often for larger queries or lists of data. A write-aside cache is generally more purposeful for single item cached data.
Getting data out of the cache is only a small part of caching. We also need to talk about a critically important and often overlooked part of HTTP caching: HTTP headers.
Server-side code must return a certain set of headers if it expects the caller to cache the returned data. The following headers can be used by browsers and server-side integrations to determine caching strategies and data freshness:
Cache-Control: This header defines the caching policy for data and is used to determine cache privacy, expiration, and revalidation.ETag: This header uniquely identifies the version of the data. Its value is typically an alphanumeric string or a timestamp.Age: This header indicates how long the data returned in the response has been in the cache. It has a numeric value that represents the time in seconds.
When data is returned from the server in our example application, we should include these headers along with the payload so callers can cache the data appropriately:
{
"headers": {
"Cache-Control": "max-age=600 public must-revalidate",
"ETag": "Wed, 10 May 2023 07:28:00 GMT",
"Age": 60
}
}
Let’s talk a bit about the values we used for our headers.
Cache-Control
The max-age=600 value of this header indicates this data will be stale after 600 seconds. Since we get a refresh of the data every 10 minutes, we set the time to live (TTL) to 600.
We also indicated the cache data is public, which means any cache can store the contents—even if it’s shared by multiple users like a CDN. Since our data is for everyone, we can safely set this value. If we had restricted data, we could provide a private directive, which indicates only the caller can cache the value.
Lastly, we included a must-revalidate directive in our header. This means that once the caller has cached the data for more than 600 seconds, we require them to call the API again to refresh the data.
For a full list of Cache-Control values, click here.
ETag
The ETag header is a unique identifier for a specific version of the data. Our data is frequently changing, so instead of saving version numbers, we save the timestamp from the moment the data was provided. This means that in our specific use case, the timestamp provided in the ETag header represents unique data.
If the caller makes another request to our GET endpoint and includes this ETag, the server code will use it to validate if there is a newer version. If the ETag matches the current data in the database, the server will return a 304 Not Modified response, indicating the caller already had the current version. If the ETag does not match the server cached value, the newer version is returned with a 200 OK status code.
Age
Our response has an Age header with a value of 60. This header is used by the caller to determine the data’s freshness. By returning a value of 60, we not only indicate that the returned data was pulled out of the server cache, but also that it had been in the cache for 60 seconds. If the data was loaded from the database instead of the cache, we would have returned a value of 0.
Client-side caching
There tends to be some confusion around the term “client-side” when it comes to software. Many application developers assume it refers to the user interface. However, service developers assume it means server-side code integrating with their service.
Both are right.
“Client-side” refers to the caller of an API, which could be a user interface or a web service.
When it comes to caching, browser-based user interfaces get a huge benefit, as it’s all handled automatically. Modern browsers like Chrome, Firefox, Safari, and Edge all know of and accommodate for standard caching headers.
This means that in our restaurant app, when the browser receives the response we just talked about, it’s going to store that data in a browser cache for 10 minutes. If a user tries to refresh the page or visits it multiple times, the cached version will be used without sending another call to our API.
Cache headers are a little different for requests, though. Requests don’t dictate caching strategies or inform anyone about how old the data is, so different headers are used.
If-None-Match
This request header contains the value provided in the ETag of a response. The first time you load data, the ETag is returned and saved in the browser cache. When it’s time to refresh the data, this value is provided in the If-None-Match header, which the server uses to validate the data.
If the value provided in this header matches the server-side ETag, that means the client already has the latest version. As mentioned earlier, the server would return a 304 Not Modified status code and an empty response body in order to minimize unnecessary data transfer.
If the value does not match the ETag, data is loaded from the server-side cache and all the values we discussed earlier are returned to the caller so they can update their end.
In our restaurant app, we’d have our cached values for 10 minutes. When the max-age of the data is passed, our app fetches the latest from the API, being sure to provide the last ETag we got in the If-None-Match header.
If we got data from the restaurant like we should have, the ETag wouldn’t match and the latest data would be returned. However, if the restaurant didn’t report data to us, the caller would already have the latest value, so it would receive a 304 Not Modified status code and continue on its merry way.
If-Match
You can also use cache data as a locking mechanism. Imagine that a restaurant in our app let patrons manually edit the wait time (I’m not sure why they would do that, but let’s pretend).
This functionality opens the door to potential concurrency issues, as several people could attempt to edit the data at the same time. However, if we use the If-Match header, our problems are solved.
Much like If-None-Match, the value of this header is the ETag returned in response to a GET request.
In API calls that modify data, like a PUT, PATCH, or DELETE, the ETag is used to make sure you’re modifying the latest version of the data. This prevents users from unknowingly overwriting data that has been modified since they loaded the page.
If you make a call with the If-Match header and the ETag does not match, the server will return a 412 Precondition Failed response, indicating the caller needs to reload the data before making the modification.
If the ETag does match, the operation will continue as normal.
Try it out
Caching is an advanced technique that gives applications that much-needed performance boost, as well as stress relief during times of peak traffic. There are many moving parts in caching, and all of them are optional. While it’s not 100% necessary to implement caching in your app before you make it to production, it will help ensure a smooth launch.
If you want to try it out yourself, start small. You don’t have to implement server-side and client-side caching at the same time. Generally, the easiest way to get started is to pick your endpoints that have cacheable data and return the caching headers. If you don’t already have your data versioned, start saving a lastModified attribute on creation/modification so you can use it for your ETag.
How frequently does your data change? Does it update every 10 minutes like our restaurant app? If so, set the max-age in your Cache-Control header to 600. You don’t want your data cached longer than the average update period or you might accidentally use a stale value.
If you’re unsure what your values should be, iterate! Start with the most restrictive policy you can think of and start easing out from there. Software is never finished; we’re constantly honing it and making it better. Caching is no different. Our strategy evolves as we provide different data and understand customer usage better. Be flexible and keep learning.
Happy coding!


What do you think about this topic? Tell us in a comment below.