
The Twitter API: Confessions of a User
I recently wrote a blog post about my experience creating a Twitter hashtag search bot. While the accompanying Postman Collection works as I described, I eventually realized I made some incorrect assumptions and inefficient decisions. After chatting with Twitter Senior Developer Advocate Andy Piper during the “Searching for the Hidden Gems in the Twitter API” Postman livestream, I’m here to muse on some of my learnings and come clean about my previous complaints regarding the Twitter API.
To read, or to code?
I think all developers can identify with the dilemma of where to start: reading the docs first or diving in headfirst with an example. When working with a new API, I often try to take a sample request and get it working in my own Postman environment. From there, it’s a series of self-guided trials and errors, and I occasionally go back to reference the docs.
In the case of building a Twitter hashtag search bot, I chose to jump right into the Twitter API v2 collection in Postman. It was pretty easy to enter my auth credentials and start sending requests. But this same convenience ended up being a bit of a double-edged sword, as I arguably jumped in too swiftly. My hasty queries led to some misunderstandings and frustrations that could have potentially been avoided had I read through the documentation more thoroughly. Going forward, I may invest a bit more time upfront to understand the full functionality of an API.
Twitter taking after GraphQL?
I wrongly accused the Twitter API of lacking certain functionality. When I searched for tweets with a certain hashtag, I easily returned the content of the tweets, but I couldn’t seem to get any info on the person who sent the tweet without making a second request. Looking at the request below, you can see the query params include user.fields with values of created_at,id,name,username. Based on these request parameters, I expected the response for each tweet that was returned to include user info. But if you look at the response object, those values are nowhere to be found.
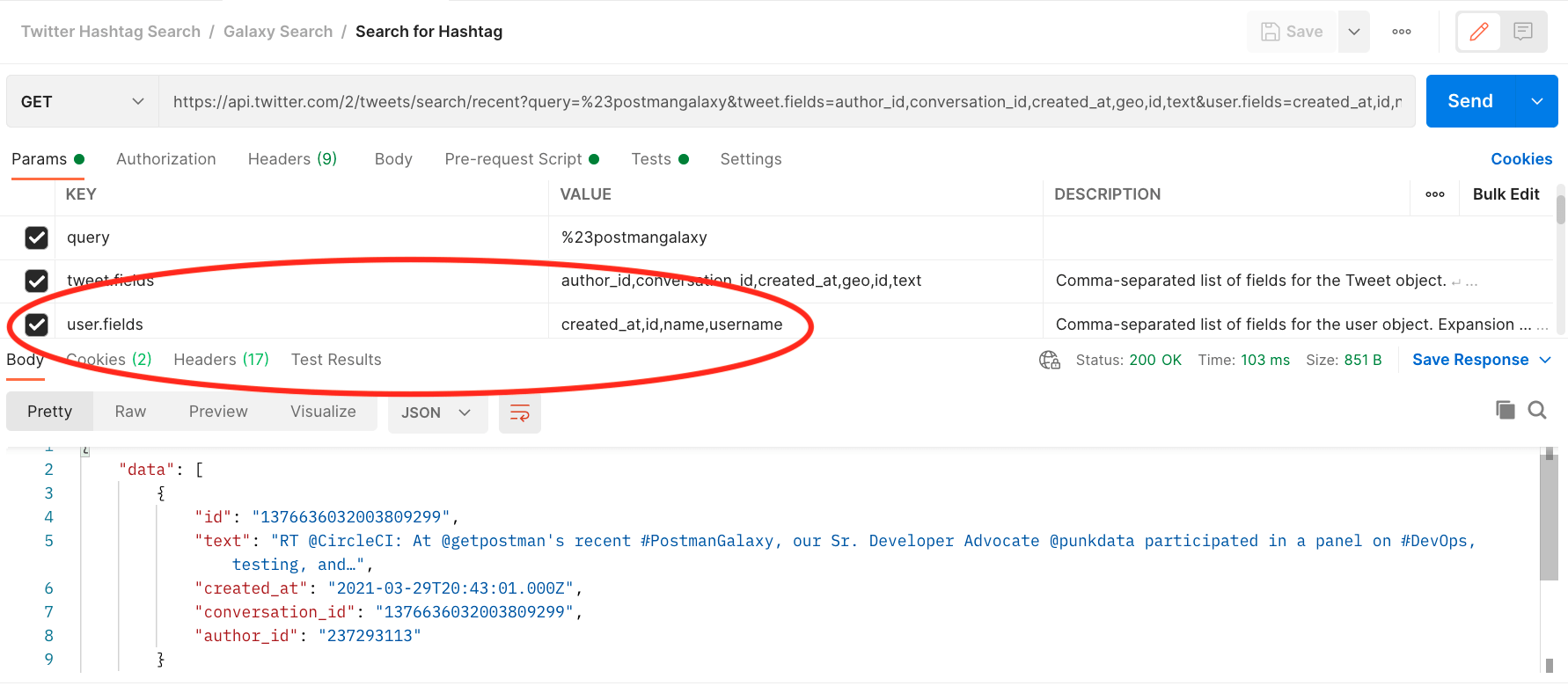
user.fields param, yet the corresponding response includes no user infoThis led to my incorrect assumption that Twitter was intentionally withholding certain information from the response based on my API access level. But this seemingly frustrating snag is actually an intentional API design choice. Andy taught me that the Twitter API has tons of data for every tweet, and the API response used to return everything. However, with so much info available, responses can get very large and unwieldy if all the available data is sent in the response.
The Twitter API now lets you have more control over what gets returned in your response. This is similar to GraphQL in that you can request specifically what you want to get back. As they describe in their official tweet object documentation, “Tweets are the basic building block of all things Twitter.” From the tweet object itself, there are several child objects from which you can request more data. One of these child objects is the user object, which returns information about the users of tweets.
How to include the child object
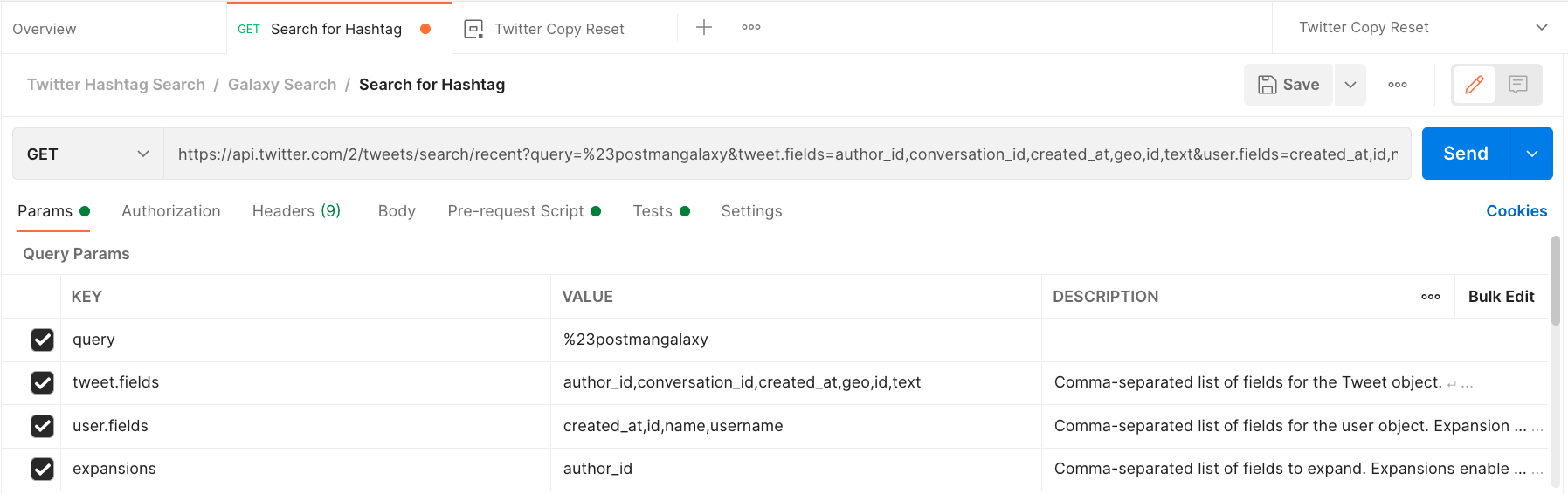
If you’re using the Twitter API from within Postman, you need to include a query parameter called expansions. Expansions allow you to expand objects referenced in the payload, such as the user object mentioned above. Below is the updated request with the new expansions key activated and author_id as the value:
And here’s the new response:
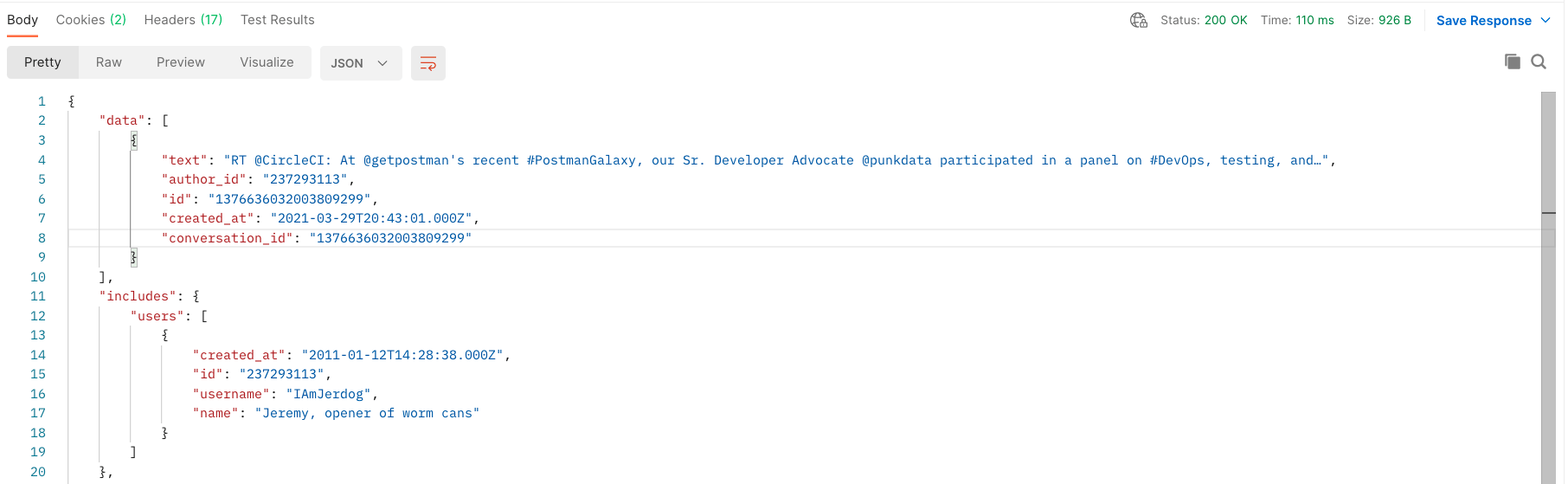
You’ll notice it has a new object tacked on at the bottom, called includes with an array called users. Success!
Also, notice that the value for author_id in the data object matches with the value for id in the users object. Using these matching IDs, you can sync the user information for each tweet. With a little bit of JavaScript code (see below), you can loop through both objects and pair them up:
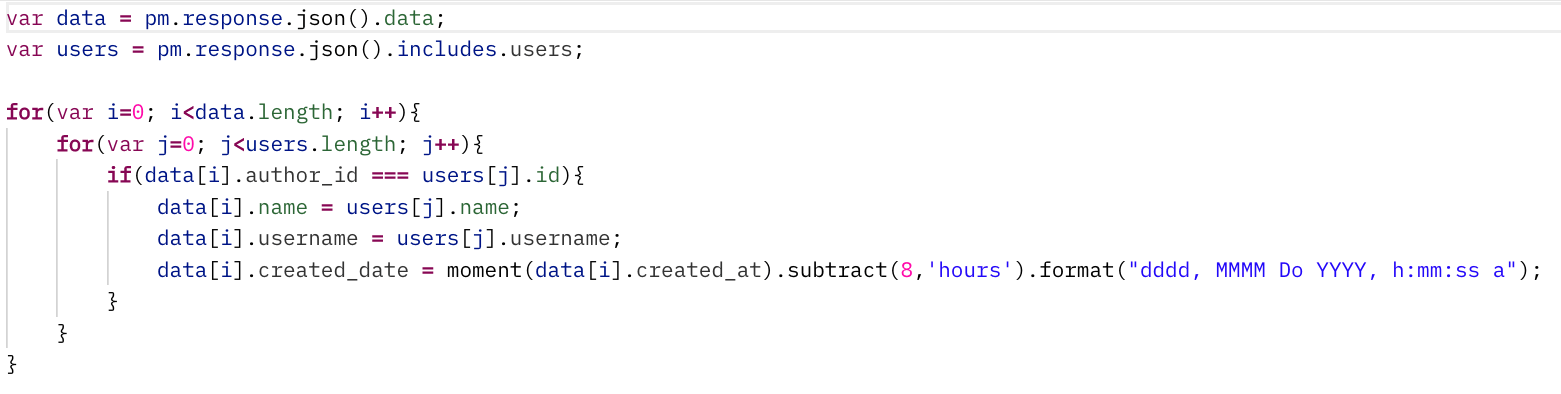
Want to contribute?
Are you a developer whose stomach gets queasy at the thought of nested for loops like the code above? Or just have some cool ideas to make this bot even better? If so, please feel free to help improve my code for the Twitter hashtag search bot. Postman’s public workspaces make it easy to fork a collection, make some improvements, and submit a pull request. Click here to go to the collection and then click “Fork” in the central menu bar to bring the collection into your own workspace.



Hi @Sean,
I am doing an academic project in Political Science with the Full Archive Research track. My tweets search does not return username and name (i am getting only author id). I have tried your suggestion but it did not work. I am using keywords instead of hashtags as queries. I have not authorized with OAuth (authorization type shows – Bearer token only). Any help from you would be highly appreciated.
Muhsin
Hi @Mushin! Sorry for the late reply here, but hopefully you were able to get something working! This is a great question to take to our community forum, as a bunch of people can chime in and help out 🙂 You can also post code samples or link directly to a collection or workspace, so folks can see what’s going wrong.