
How Postman Engineering Handles a Million Concurrent Connections
In the Marvel Cinematic Universe, Bifrost is the name of the rainbow bridge that allows instantaneous travel between the realms of gods and humanity. Similarly, and equally magically, our Bifrost websocket gateway lets Postman clients instantaneously connect to Postman services.
As I’ve previously shared in How Postman Engineering Does Microservices Today, all software architectures are a continuous work in process. Operating in the real world means occasionally re-evaluating old ways of thinking to adjust to new circumstances. That is the natural evolution of software design.
Here is the story of how Postman engineers developed the Bifrost websocket gateway by chipping away at a service that grew too big.
Development teams at Postman
Most development teams at Postman work in cross-functional squads focused on a single core domain, such as documentation or version control. Guided by the principles of domain-driven design, each squad develops internal microservices and Postman features for Postman users.
While most engineers work in squads, some work in functional teams that build components shared across the entire engineering organization. The Server Foundation team is an example of a functional team at Postman. These engineers create the utilities used by other squads to build, ship, and observe their own features. This team is also where the resident AWS and infrastructure experts reside.
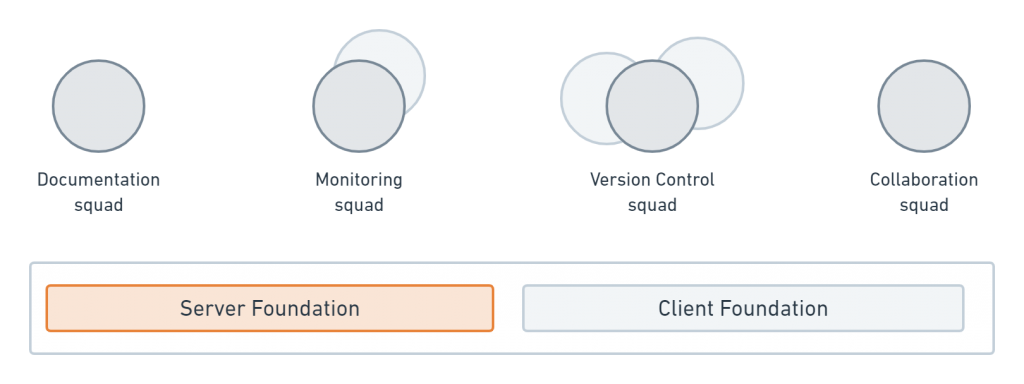
Most microservices at Postman are loosely coupled so they can evolve independently of other teams. Unfortunately, a service can sometimes grow too big, providing a breadth of seemingly unrelated services. These services allow the team to rapidly iterate, but may start acting more like a bloated monolith, a big ball of mud, or whatever you want to call these unwieldy creatures.
When this happens at Postman, many engineers across different teams end up contributing to the code, requiring careful coordination across every team for each and every update.
The monolithic Sync service
One of the Postman services that grew too big to be managed efficiently is called Sync. It has the daunting task of synchronizing all the activity in the Postman client on your local machine with Postman servers. Every user action in Postman results in a series of API calls handled over websocket connections, following a publish-subscribe pattern, so that information flows in real time between users and across teams.
For example, this is what happens when you log in to Postman and update a collection:
- You add a parameter to the Postman collection.
- Postman keeps a record of the update in version control stored with your profile.
- Postman displays the latest information to viewers of the collection in real time.
Sync was originally intended to handle database transactions, like updating a collection. However, this time last year, Sync also managed additional activities, such as notifying and displaying the latest version to everyone subscribed to the collection.
Sync under pressure
When you’re building a car, the frame is the main supporting structure to which all other components are attached. A tiny crack in the frame might not seem like a big deal. It could probably go unnoticed driving around at low speeds. At higher speeds, however, there’s a ripple effect escalating misalignments. The seemingly insignificant crack allows vibrations to amplify throughout the rest of the vehicle until it escalates into a flaming wreckage.
“Stuff that goes unnoticed in smaller systems becomes inescapable in more complex systems.”
—Kunal Nagpal, engineering manager for the Server Foundation team at Postman
Sync was one of the earliest services at Postman, and its monolithic architecture allowed the team to ship Postman features quickly. Over time, it began handling more and more responsibilities. To this day, the Sync service still has widespread influence across the engineering organization, and lots of engineers feel the pain when Sync behaves unexpectedly or there’s scheduled downtime.
In 2019, Sync was handling both websocket connections and database transactions. With more and more collaboration happening among our 11 million users at that time, Postman was approaching a million concurrent connections at peak load.
As the foundation for virtually every microservice at Postman, the strain on Sync was growing.
- Cascading failure due to backpressure: Every deployment to Sync results in disconnecting Postman clients connected over websockets. When a million sockets reconnect, server resources are degraded, which can then result in more disconnections, causing a predictable but unavoidable surge that can take 6 to 8 hours to recover.
- Impacting user experience: Even though it didn’t happen often, dropped connections meant an occasional delay in seeing the latest updates and activity in a Team Workspace.
- Higher cost of maintenance: Since every squad relied on Sync, virtually every engineer at Postman had to learn how to handle dropped connections, initiate new ones, and then reconcile any conflicts in the data.
The Server Foundation team knew they wanted to increase the efficiency of websocket connections, and also handle them separately from the Sync service. The destination was clear, but the path to get there was not.
“This is the natural evolution of software design. Microservices start nimble, but they build up, and need to be broken back down. We wanted to separate socket handling from Sync because we were about to introduce a lot more functionality.”
—Yashish Dua, software engineer for the Server Foundation team at Postman

Here is what happened
Step 1: We got organizational buy-in
The first challenge to tackle was not a technical one. This was not Postman’s first ambitious rollout. Engineering had learned from past go-arounds to begin with the people. Starting in October of 2019, the Server Foundation engineers held a series of reviews dedicated to communicating the goal to the broader organization, and explaining the benefit for all dependent services.
If this new system succeeded, handling dropped connections and dealing with the aftermath would no longer be commonplace. This was a real incentive for the other engineering teams to support and migrate to the new system. This open communication and coordination would continue throughout the duration of this project.
Step 2: We identified the unknown unknowns
Engineering knew the direction they were heading in. Despite that, they took some time to think through all the scenarios and better understand the underlying concepts. The engineers scheduled exploratory sessions with other stakeholders to identify unknown unknowns, the unforeseeable conditions which can pose a greater risk than the known knowns.
While the Postman organization is used to researching and planning, this part of the process took a lot longer than normal due to the critical nature of this change. They researched different options, considered auxiliary requirements, and came up with a plan over the course of two months.
Step 3: We built the Bifrost websocket gateway
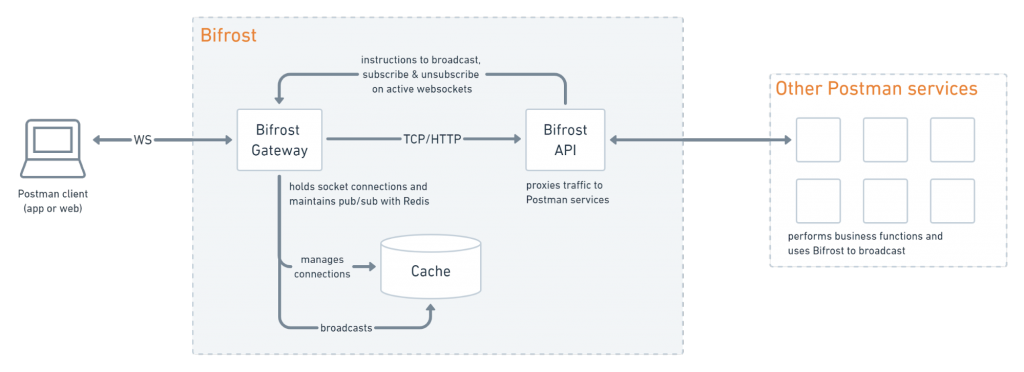
The Bifrost is composed of two parts:
- Public gateway: The gateway uses the Fastify web framework and Amazon AWS ElastiCache for Redis as a central message broker to manage all websocket connections.
- Private API: The API also uses Fastify as a low overhead web framework to proxy traffic to other internal Postman services.
Step 4: We tested the new gateway
When Postman engineers are ready to ship a feature, they are expected to test the feature, along with any related features. Since almost every Postman feature relies on websockets, this meant every single feature had to be tested for this release. Furthermore, a framework for automated testing of websockets had not yet been set up at Postman, so all the testing was completed manually before Bifrost could be used in production.
This was an arduous journey, but by the end of January 2020, engineering had a working proof of concept.
Step 5: We migrated to the new gateway
All Postman clients, such as the Electron app or the Web, rely on an initial bootstrap call to another core service named Godserver. This server determines the clients’ access and configuration, and is how engineering controls incremental product rollouts. Because this was all predetermined and controlled by the Godserver, migrating to the Bifrost gateway would not require a single Postman client code update.
The Server Foundation team outlined the squads’ migration steps, the required code changes and configuration to apply. Over the course of a few weeks, dependent services began transitioning from relying on Sync to Bifrost-based handling of their websocket connections. The Godserver diverted more and more traffic to the new websocket gateway to see how Bifrost handled the load and responded to edge cases.
“It’s like changing an engine on an aircraft in mid-flight.”
—Numaan Ashraf, director of engineering at Postman
Step 6: We scaled the service
The Bifrost gateway was working!
But Postman had acquired another million or so users while the gateway was in planning and development. And the other engineering teams had not paused their own work during this time. New collaboration features, like version control and role-based access control (RBAC), relied heavily on websockets for information to be updated in real time. There was a flood of upcoming product releases that would truly test the new gateway.
Bifrost was ready to support the increased demands and scale websocket handling.
- Horizontal scaling: Most of the time, Postman services handle increased usage by either scaling to higher capacity instances or by adding more compute instances to the fleet. So engineers at Postman usually scale up a service by increasing the size and computing power of AWS EC2 instances, for example, by using AWS Elastic Beanstalk. But for Bifrost, websocket handling scales out by using more machines. Its optimum efficiency is achieved when smaller-sized instances are used in large numbers. This type of hyper-horizontal scaling works well for Bifrost because clients don’t require high network throughput, and limiting each machine to fewer connections limits the blast radius of failures.
- New load factor of CPU and memory: Most Postman services can effectively scale with a single dimension of scaling metric, like CPU, memory, or latency. However, for Bifrost, things get a bit more nuanced because both memory and CPU usage have different impacts on operations at various levels of throughput. To account for that, Bifrost uses a custom scaling metric based on load factor. The load factor is a multidimensional calculation that imparts a custom non-linear scaling profile.
Let’s dig into the architectural and technology decisions made by Postman engineering.
The Bifrost architecture and tech stack
The Bifrost system has two major components—a Gateway and an API. This two-part architecture is the secret sauce to the stability and scalability of the system.
The Gateway acts as the termination point for all websocket connections. Even though commercial gateways are available for purchase, it was important to preserve the legacy business logic accumulated over years of optimization. Postman engineers also wanted to fully control how websockets are handled, for example, if they wanted to tap into the protocol handshake. For the Bifrost gateway, they used Amazon ElastiCache for Redis allowing them to query the Redis cache using reader and writer nodes. Splitting the traffic into two nodes for read and write operations further allows the team to optimize the performance.
“Bifrost is our gateway for all websocket connections. It’s a proxy for all Postman clients, and responsible for handling low-level socket operations for internal Postman services.”
—Mudit Mehta, software engineer for the Server Foundation team at Postman
Most every other service at Postman uses Sails as a real-time MVC framework for Node.js. For the Bifrost gateway, however, the engineers needed a performant backend framework capable of handling high volumes with speed and optimized memory usage. Once again, they wanted to go deeper into the socket layer, below the higher-level abstractions provided by Sails. So they turned to Fastify and forked the socketio-adapter middleware to optimize for their own use cases.

In addition to the gateway, the other component of Bifrost is the private API that proxies traffic to other Postman services. It is based on flexible business rules, and so constantly re-evaluated for how and where to forward inbound traffic.
“Simple components. Complex logic.”
—Kunal Nagpal, engineering manager for the Server Foundation team at Postman
For both components, the engineering team decided to roll their own. Although the gateway part of Bifrost isn’t updated frequently, the team has full control over what happens in the deeper layers of websocket handling. The API part of Bifrost is the brains of the operation and converts incoming real-time messages to standard HTTP calls. It can also be updated more quickly as an independent component from Sync and the Bifrost gateway. Remember that secret sauce? Decoupling Bifrost into these two discrete systems allows both parts to optimize for their own objectives.
The journey is far from over
As with all juicy engineering stories, this isn’t the end. I’ll leave you with a few cliffhangers about what’s coming up next for Postman engineering.
- Build additional redundancy: The Redis cache is a central message broker. Websocket handling still relies on a single point of failure, so what happens if the cache ever goes down?
- Increase bandwidth and throughput: The gateway is currently capable of handling 10x concurrency, but the Postman community is growing fast and engineering is building out more collaboration features. The need to handle more websocket traffic is coming up quickly.
- Continue breaking down the monolith: The Sync service contains a jumble of other services entwined within its codebase. Decoupling socket handling from Sync loosens its grip on other services, so other services can now be more easily peeled off. This was another behind-the-scenes peek at how Postman engineering operates. Stay tuned for more stories from the trenches.
Technical review by Kunal Nagpal, Yashish Dua, Mudit Mehta, and Shamasis Bhattacharya.



What’s the actual hardware scale range @ load? We’re currently doing 1.2M requests/s on a streaming service layer via fargate ECS on 6.75 max total cores, sub 16gb ram (excluding redis) for the operational cluster, it’d be interesting to compare relative usage metrics against the two architectures to assess economies of scale, if not scope.