Choosing the right data API for NoSQL with Apache Cassandra and Postman

This is a guest post written by Pieter Humphrey, Developer Product Manager at DataStax.
The cloud allows us to focus on things other than infrastructure. Evolution in app frameworks and release management has made getting code-to-cloud relatively straightforward. As these concerns somewhat fade into the background, web APIs come increasingly into focus. But why web APIs specifically?
Well, firewalls, L7 load balancers, and network infrastructure have all converged on using HTTP as the cloud networking protocol of choice. As most new applications are on the cloud, it follows that web APIs based on HTTP and HTTP/2 will dominate, which, of course, REST does already. As APIs and SaaS become the main entry points to digital business, it’s easy to see why early movers like Postman enjoy runaway popularity with developers. Web APIs are easy to learn and provide refreshing productivity. Postman is well aware of this and is delivering on critical API infrastructure for developers.
However, there is a relatively new web API kid on the block that is up and coming for high-performance systems: gRPC. With gRPC, Postman API platform developers are beginning to venture into the space of high-performance systems, as more and more systems become gRPC-enabled.
The database space refers to growth in low latency HTTP as the driverless (r)evolution. Cassandra/Stargate, etcd, ClickHouse, PrestoDB, Apache Pinot, Apache Flink, and others are already starting to join. But how did we get here, is it all about gRPC, and what does “driverless” really mean? This post endeavors to answer these and other questions about databases-as-APIs. We’ll start at the beginning, without forgetting that other web APIs are, of course, here to stay.
You can also join the livestream on November 3, 2022 (or check out the replay) to learn more about the driverless (r)evolution in high-performance systems with Postman’s Ian Douglas and DataStax’s Jeff Carpenter.
In the beginning, there was LAN
Most databases are struggling to adapt to the cloud and SaaS. Most of them were designed in the era of limited disk space and single, long-lived servers. Relational models joined different tables, which could then be located on different disk volumes if needed. Web, application servers, and connection pools everywhere struggled mightily with a database that was dislocated from them in the DMZ network. While clustering the apps and databases across machines for scale was certainly doable, responding quickly to changing load conditions without virtualization was not. Also, dislocating storage volume from the database server process across process and network boundaries was definitely not in the traditional RDBMS design plan. Crossing those boundaries can wreak absolute havoc with the ACID transaction guarantees that are the sacred promise of databases to developers:
“Here, hold my data, no matter if others are trying to change it at the same time, and make sure it’s here when I come back.”
So—hold my data—what’s the big deal, you may rightly ask? Does living on the cloud just mean a database needs to be designed for network, virtual machine, and/or container awareness? Well, we can oversimplify by saying that, in essence—yes. But this ignores the unavoidable compromises that arise between data consistency and database server availability when network linkage fails. This is why RDBMS cannot simply be forklifted to the cloud. The road to high-performance, multi-region operational databases is littered with out-of-sync shards, Oracle RAC invoices, and downtime. This is part of why NoSQL and NewSQL are ascendant. But we are just talking about system design here. What about connecting apps, other cloud services, and serverless functions to your cloud database?
Low latency HTTP, and other fables of computer science
Many application frameworks already offer ways to transform databases into REST. That works great in a lot of use cases, except that REST is slow. This tends to exclude it from high-performance use cases, and from complex systems that already have a long end-to-end latency chain. APIs like GraphQL have emerged to solve the REST over/under-fetching issues, particularly in systems where there are multiple data sources. At the very heart of the HTTP performance discussion is the fact that data needs to be serialized. Web APIs to date seem to have an affinity for one, or maybe two, approaches to serialization. For example, GraphQL is JSON/HTTP by convention, but nothing in the specification mandates that. Data serialization has a major impact on both your application code and performance.
Generally speaking, too much focus on raw performance results in a complex, constrained development process. Too much focus on ease of development (time to market), and the resulting performance in production may disappoint and require an expensive redesign shortly after launch. Recently, data gateways have emerged to modernize databases for multiple web APIs and use cases. They can transform databases into web and other APIs independently of any application framework. Today’s cloud-scale apps need high-speed options alongside slower, but easier-to-develop ones. Also, as APIs become the primary point of digital interaction, APIs will proliferate. That will make it hard for general application frameworks to keep pace, making extensible data gateways desirable. Consider how long it took for your favorite app dev framework to add support for GraphQL, for instance.
However, new technology also needs to find ways to accommodate the old. Native database drivers, the mainstay of the traditional app-to-database connection, are high performance but aren’t very cloud friendly. Sure, drivers can be made cloud-aware, but they aren’t cloud native. Native drivers typically encompass tasks like connection pooling, TLS, authentication, load balancing, retry policies, write coalescing, compression, health checks, and more.
Usually, these operational tasks are abstracted away from applications in cloud environments for a reason and are simply handled automatically on behalf of the application. For example, load balancing, health checks, and TLS termination are intrinsic to most cloud environments; even retries can be configured within the environment. Building native drivers into an otherwise cloud native, real-time application has real and negative consequences. Also, developers are forced to learn proprietary driver APIs and expend precious skill-building energy on network management code, not business logic.
With gRPC, low latency HTTP is no longer a contradiction in terms or an impossibility.
gRPC outperforms REST over HTTP 1.1 by 7x-10x, and it outperforms REST over HTTP/2 by 50% – 70%. Postman has an excellent blog that expands on the comparison, complete with a nice REST vs. gRPC comparison table. gRPC has matured in the past several years, and it’s growing. Is REST going away? Of course not.
Fire from the gods: Big data, high performance, and WAN
Machine-generated data volumes are exploding like wildfire, in everything from IoT to IT monitoring and management systems. Worldwide data is expected to hit 175 zettabytes (10,000 TB) by 2025—and we’re not even talking about human-generated data! Much of it will be stored in the cloud. This is why both operational and analytical databases designed for the large-scale data cloud will play such an important role. More information is just more information. It takes structure and analysis, or search in the case of unstructured data, to be useful.
Apache Cassandra is a popular OSS operational database (OLTP) for apps, functions, and cloud services that were initially inspired by concepts from the Dynamo paper (no, not Dynamo DB), and Google’s Bigtable. It has evolved significantly since then, often employed at big data and cloud scale—you might say it was the original cloud-native database. One of the things its leaderless architecture does best is replicate across wide area networks and geographic regions, something that RDBMS often struggles with. Having data colocated with your applications is essential in maintaining performance at scale as your business expands into different regions, or simply puts basic, database-level disaster recovery plans into place.
With the addition of Stargate, Cassandra supports wide-column, key-value, and document NoSQL models. And with next-generation ACID transactions and secondary indexes coming in Apache Cassandra 5.0, some of the most powerful arguments for accepting the compromises of RDBMS in the cloud are starting to evaporate.
The driverless future for high-performance apps
Stargate is a data API gateway that elevates web APIs like gRPC to native-driver-level performance while modernizing Apache Cassandra for other web APIs and JSON. Stargate completes the transformation of the Apache Cassandra powerhouse database to a cloud service that simplifies data access and management.
Stargate for developers
- Automatic app-to-database web APIs over secure gRPC, GraphQL, and REST endpoints.
- Go multi-model with Stargate and transform Cassandra into a document database using the JSON Document API. Start schema-less, or use JSON Schema for unstructured or semi-structured JSON.
- Cassandra auth upgrade: table-based and JWT-based token authorization for both driver and API connections.
Stargate for operations
- Stargate deploys anywhere—bare metal, VMs, Docker, GKE, EKS, K8ssandra, DSE—and is available as a managed service on Astra DB.
- Stargate v2 transforms Cassandra into modular architecture by separating coordinator and storage nodes into independently deployable and scalable services. Tune performance to best match your application workload.
- Stargate v2 architecture is further modularized by separating web API services and gRPC/Native driver nodes into independently deployable and scalable services. Tune performance to best match your API workload.
Stargate extensibility
- Creating new API services for Cassandra is easier than ever using Stargate’s gRPC Bridge API and modular architecture. Adapt Cassandra to the APIs and data serialization formats your organization uses.
- Stargate is Apache v2 licensed and uses public GitHub repos and discussions for transparency and collaboration.
- Cassandra 4.1 itself has new extension points for storage, network encryption, authentication, schema storage, and guardrails.
Lighting your path to the right data API
As you consider your options for modernizing Cassandra with Stargate, you’ll want to understand the available tradeoffs between developer productivity, flexibility, and performance. Here is a brief look at the web APIs Stargate currently supports, along with some (hopefully) illuminating guidance on when different options could make sense for you:
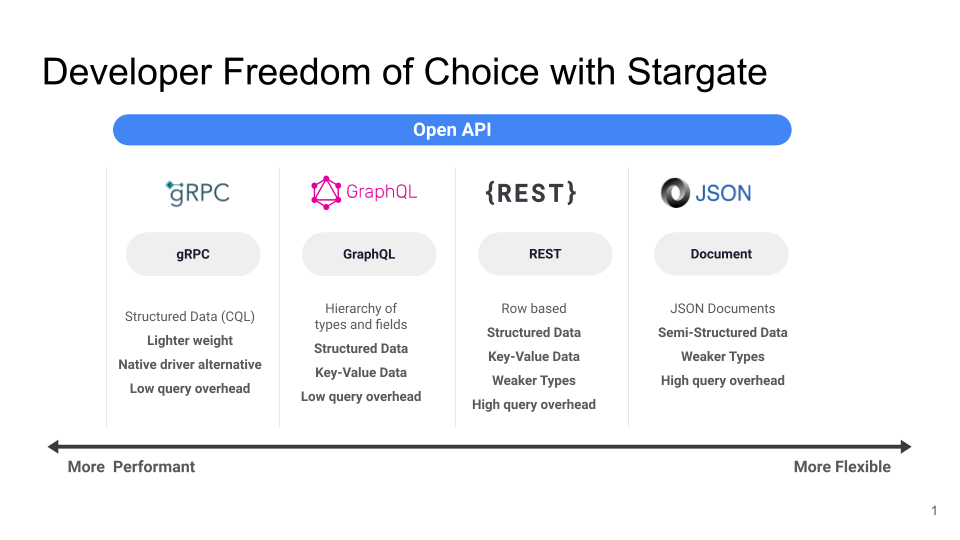
CQL over gRPC
This should be the default approach for backend developers with latency-sensitive apps, microservices, and serverless functions in Rust, NodeJS, goLang, or Java. More clients are coming, but it’s fairly straightforward to generate a client for another language with gRPC. Stargate’s gRPC API delivers wire-speed equivalent to native drivers, but over HTTP/2. gRPC itself handles native driver tasks like connection pooling, TLS, authentication, load balancing, retry policies, write coalescing, compression, and health checks automatically, so it’s easier to learn than drivers.
GraphQL API
This is great for frontend developers, as well as general app, microservice, or serverless function development. When you need to solve REST under/over-fetching or query multiple backend services, Stargate allows Cassandra to participate in the GraphQL query path. Or perhaps your project has simply chosen GraphQL over a purely RESTful approach. The Stargate GraphQL API is usable in both schema-first and CQL-first modes.
CQL over REST
This is great for frontend developers. It offers the greatest level of portability and accessibility for all languages, and is helpful when you don’t have a supported driver or gRPC client for your language or language version.
JSON Document API
This is great for frontend developers and is the easiest possible development path. Use it when you have unstructured data, or when you are doing initial development and don’t want to invest the effort in data modeling and schema definition yet. For apps with semi- or well-structured JSON, JSON Schema support in Stargate facilitates easier testing, data validation, and API documentation.
Light a fire, build something awesome
Ready to start working with big data and web APIs? So are Cassandra and Stargate, now available on the Postman API Network. Check out the DataStax Medium blog for a tutorial on how to use the collections!



What do you think about this topic? Tell us in a comment below.