
How We Built Postman’s New Activity Feed System
The activity feed is a central element powering workspace collaboration in the Postman API Platform. Located on the Overview page, it provides a unified picture of all changes made in a workspace over time. This information is critical when multiple people are collaborating in the same workspace and you want to see the updates made by your peers.
The activity feed used to be powered by a monolith service called sync service, which accomplished the daunting task of synchronizing all the activity in the Postman client on your local machine with Postman servers. As part of this synchronization, it also kept a recording of all the activities over time using an append-only logic. As Postman scaled to more than 20 million users, and workspace activities quadrupled, the sync system became a bottleneck as we tried to scale the activity feed. We record approximately 15 million activities per day.
In this blog post, we’ll go over the challenges the Postman team faced and how we solved this problem by building a new activity feed system, which we named Chronicle.
Challenges with sync service
The monolithic sync service became a bottleneck for scaling the activity feed due to the following reasons:
- Deriving of feed was happening from a separate table called Revisions (an internal change management log)
- Performance bottlenecks due to huge data size (150GB) and indexes (320GB) impacted query performance
- Extending to future use cases became challenging due to the tight coupling with the Revisions system and the above performance issues
- There wasn’t an archival system in place for storing old feeds
- Performing operations on a live and highly accessed table was tricky
As Postman was scaling really quickly, the reliance on this increased heavily both from an end-user perspective and from an internal perspective.
7 features of a future-proof feed system
We decided to take a step back and started listing to what was needed to make the system future-proof and sustainable through Postman’s continued expansion over the next few years. These are the seven system capabilities we decided our activity feed system must have:
- It is capable of being generic in nature and can be adopted by any entity. For example, a collection can show a collection timeline, an API can show an API timeline, a user can have a user timeline, etc.
- It inherently archives data; recent data (from within three months) is stored in DocumentDB and older data is stored in MySQL.
-
It has collation support (collating entries with X entries in Y time range).
- It is easier to introduce a newer class of feeds; makes new class of feeds seamless and backward-compatible with the product.
- If has paginated support for pulling entries from hot storage, and a background system which can even stitch the complete activity on demand.
- It has the ability to understand a hierarchical model (most actions in Postman happen inside a workspace or a team umbrella, so we wanted the capability to gather granular subtrees, which will help us get data even quicker if it’s directed for a particular entity or audit purposes).
-
It has the ability to run analytics to predict future usage.
Introducing Chronicle
“Chronicle” in Greek terminology is referred to as “a written record of historical events describing them in the order in which they happened.” It is also Postman’s new feed system.
Chronicle allows consumers to ingest data in whichever form they like and renders the same form in the activity feed of a workspace. It abstracts out functionalities like access controls, parent-child hierarchy (as applicable), data partitioning, and archival-related aspects from its consumers. It returns the data in raw format that other consumers can use as needed.
Architecture
After multiple brainstorming sessions to consider future uses and Postman’s needs as it scales, we chose these technologies:
-
DocumentDB (AWS-based MongoDB Service): Primary data source having schema-less architecture fitting best for our use cases, catering to Postman scale and giving inherent TTL-expire functionality needed for data partitioning and archiving.
-
Amazon Simple Queue Service (SQS): Controls throughput due to the high volume of incoming data along with Dead Letter Queue (DLQ) for retry support and specific processing.
-
AWS Lambda: Periodically listens to Document DB change streams and helps to archive data at various secondary data sources (RDS, S3, etc.).
-
Secondary Sources (S3, RDS etc): When data gets expired from primary data source of DocumentDB, it gets pumped into various secondary sources. This can be assumed as a plugin-able layer that according to feed type and timeline can dump data in various spaces.
-
S3: Object storage
-
RDS – MySQL: Store in a partitioned table for quicker retrieval
-
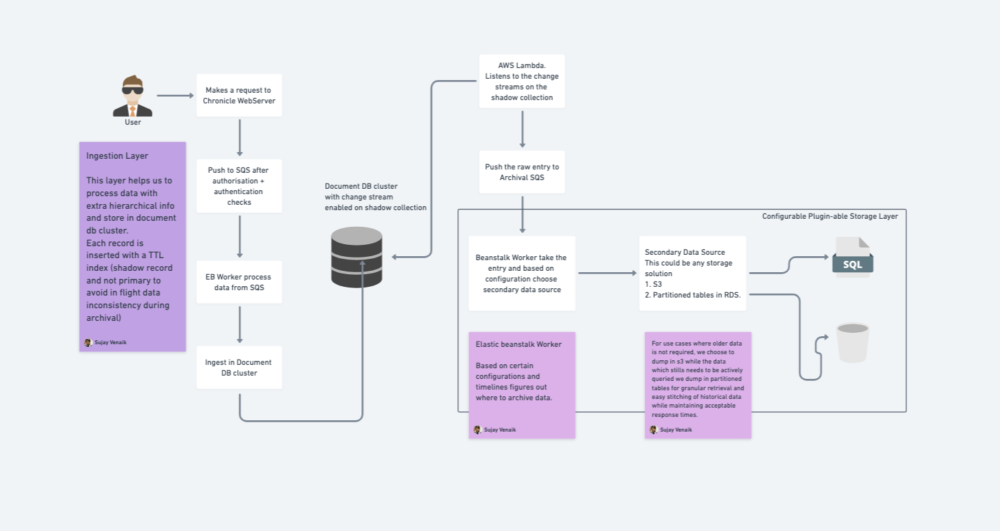
The above diagram can be broken into three high-level components:
1. Ingestion system
Whenever any activity happens, it is pushed to an ingestion queue, which is connected to a worker. The worker processes the incoming feed event, validates, adds additional meta, determines if collation is applicable, and then ingests the data in the DocumentDb primary cluster.
2. Archival system
When the ingested feeds hit the TTL period, they are processed with the help of change streams. That helps us to capture the expiring feeds. The expired feed is pushed to a queue, which is further processed by workers by gathering data and identifying correct secondary data source to dump.
Note: We do not expire the main feed but a shadow feed which just contains the reference. Integrity is maintained that a feed should never be in-flight, it should reside in one of the data stores at any instant.
3. Retrieval
Retrieval is important because we need to make sure of low latency (less than 30ms to 40ms) and return data. We pick the data from hot storage first (DocumentDb) and according to the timeline queries, we stitch data from secondary sources. Data is returned in a paginated fashion with strategies such as bucketing (no-SQL storage) and range partitioning (MySQL) used.
To address the thundering herd problem and keep latencies under acceptable thresholds, the worker scale-up policies are configured to be more aggressive than the scale-down policies. This approach enables the computing power to catch up quickly when the queues grow for both ingestion and archival.
With the new system in place, we wanted to make sure it scaled with Postman. With auto-archival, we now don’t have to worry about all the growing data; we can operate on archived data as well as new data in terms of live traffic for the Postman API Platform.
As we decoupled this from the existing legacy monolith, we were able to add more support and also iterate quickly in terms of application layer code.
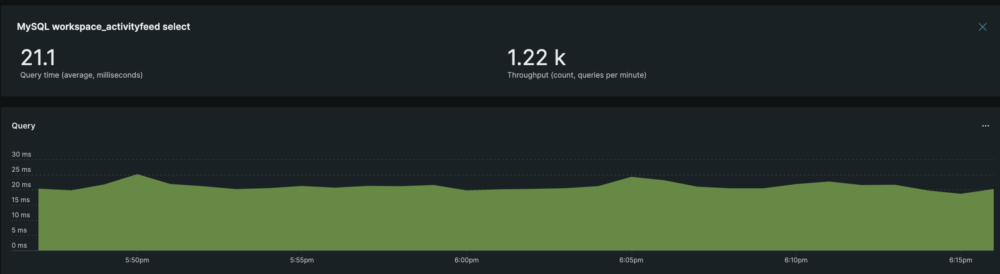
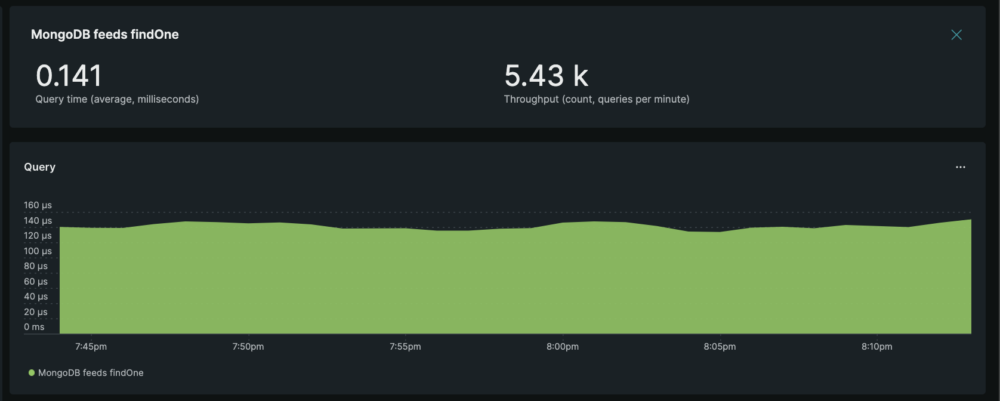
Impact metrics
The DB latency was reduced by approximately 99% from (21.1 ms → 0.14 ms):
What’s next
We’re always working on how to improve. In the future, we want to listen to all events in the Postman ecosystem with the help of our internal eventing system called Synapse and generate tons of activity automatically. As far as the activity feed’s architecture, we’re also evaluating where we can make feeds more actionable from the product perspective. Finally, we’ll be experimenting with showing feeds not just chronologically but ordered in a way that is custom to each user based on their activities. Stay tuned for more updates.
Technical review by Pratik Mandrekar, Akshay Kulkarni, and Divyanshu Singh.
Did you find this blog post interesting? If so, you might also be interested in working at Postman. Learn about joining the Postman team here.



What do you think about this topic? Tell us in a comment below.