
gRPC vs. GraphQL
REST has long been the dominant architectural style for building APIs, but several other API protocols have gained prominence in recent years. Two noteworthy examples are gRPC and GraphQL, which offer new approaches to data transfer that address some of REST’s shortcomings. gRPC is a high-performance, schema-driven framework that facilitates communication between distributed services, while GraphQL is a query language and a server-side runtime for APIs that gives clients the exact data they request.
gRPC and GraphQL are both relatively new technologies that are often discussed together, but they support different use cases and follow different design strategies. In this blog post, we’ll review gRPC and GraphQL in more detail before comparing their features and functionalities. Finally, we’ll discuss when you might choose one approach over another.
What is gRPC?
gRPC is an implementation of RPC that was developed and open-sourced by Google in 2015. RPC, which stands for “Remote Procedure Call,” is a protocol that enables clients and servers to interact with one another as if they were both on the same machine.
gRPC includes many features that modernize the way remote procedure calls are made. For instance, it uses Protocol Buffers (Protobuf) as its interface definition language (IDL), which provides strong typing and facilitates code generation in multiple languages. It also uses HTTP/2 as its underlying transport protocol, which enables multiple data streams to share a single TCP connection.
gRPC is ideal for scenarios that prioritize cross-platform communication, real-time data exchange, and high performance networking. It is commonly used in microservice-based architectures, in which individual services may be developed in different programming languages. Additionally, its broad streaming support makes it a good fit for real-time chat and video applications, online gaming applications, and live data feeds.
What is GraphQL?
GraphQL is a query language and a server-side runtime for APIs that gives clients the exact data they request. It was developed by Facebook, and the specification was published in 2015.
GraphQL enables clients to request precise data by querying multiple fields through a single /graphql endpoint, eliminating the need to chain multiple requests together. For example, you can request information about a user and their associated posts, comments, and likes in a single query. This approach improves performance and is especially beneficial on slow or unreliable network connections.
Requests from the client are validated and executed against the schema. A GraphQL schema describes the complete set of possible data the client can access, such as object fields, relationships, and supported operations. Clients can learn about the schema through introspection, which we will discuss in more detail below.
A comparison: gRPC vs. GraphQL
Both gRPC and GraphQL aim to enhance an application’s performance and flexibility, but they do so in different ways. In this section, we’ll explore the key differentiators between these two protocols.
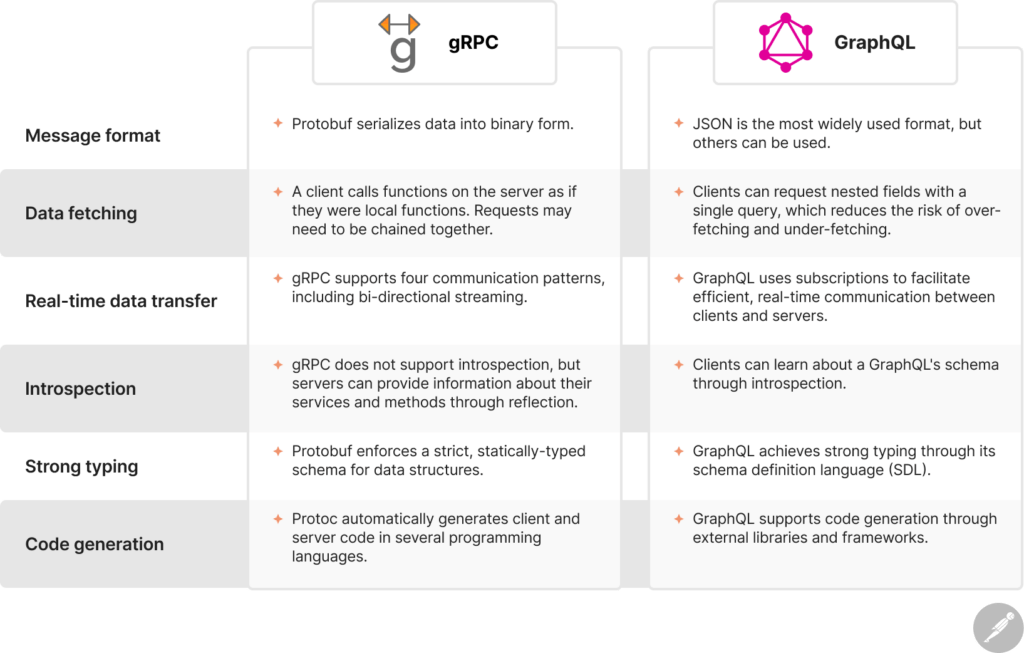
Message format
gRPC uses Protocol Buffers (Protobuf), which provides a language-agnostic mechanism for serializing data into binary form. When defining a service and its messages in a gRPC service definition (.proto) file, developers use Protobuf to specify the message types and their fields. These message types are then compiled into language-specific classes, and the data is serialized into a binary format before transmission.
GraphQL, on the other hand, is transport-agnostic, which means it can be used with different protocols and data formats. That being said, HTTP is the most common transport protocol for GraphQL, which makes JSON the default and most widely used data format.
The compact binary format used by Protobuf helps reduce the size of data that is being sent over the network, which improves performance and makes gRPC a lightweight and efficient option for applications that require rapid data transfer. JSON messages are larger and therefore take longer to transmit, but they are also human-readable and therefore easier to debug.
Data fetching
A gRPC client operates by calling functions on the server as if they were local functions. gRPC clients can send one or many requests to the server, and the server may send one or many responses back. gRPC may require clients to chain requests together to get the exact data they need, much like REST.
In contrast, GraphQL allows clients to request nested fields to retrieve related data with a single query. This reduces the risk of over-fetching and under-fetching, since only the necessary data objects are transmitted. This approach leads to significant performance gains, especially on slow or unreliable network connections.
Real-time data transfer
One of the main benefits of gRPC is its support for four communication patterns:
- Unary: a client sends a single request to the server and waits for a response.
- Server streaming: a client sends a single request and receives many responses.
- Client streaming: a client sends a stream of requests and waits for a single response.
- Bidirectional streaming: the client and server can both send a stream of messages to one another concurrently.
These streaming patterns enable services to share and process data as soon as it becomes available—without having to repeatedly establish new connections. This unlocks a wide range of modern use cases, including real-time chat and video applications.
GraphQL, on the other hand, uses subscriptions to facilitate efficient, real-time communication between clients and servers. GraphQL subscriptions are typically implemented with the WebSocket protocol, which creates a bidirectional communication channel. The subscription-related functionality is incorporated into the GraphQL schema with the dedicated Subscription type, which contains fields that represent the events available for subscription. Clients can then subscribe to these events and receive the relevant data from the server as soon as they occur.
Introspection
GraphQL supports introspection, which means that a GraphQL server can provide information about its own schema. Clients can use the __schema and __type introspection queries to dynamically inspect the schema, which makes introspection a powerful tool for documentation generation and client side operations. Introspection also enables clients to adapt to changes in the schema without manual updates, which promotes flexibility and improves the developer experience.
gRPC does not support introspection, but it does allow servers to provide information about their services and methods at runtime through reflection. Reflection is often used for service discovery and inspection, but it does not offer the same level of dynamic, detailed querying of the API’s structure as GraphQL introspection.
Strong typing
In gRPC, Protobuf enforces a strict, statically-typed schema for data structures, ensuring that both clients and servers adhere to a well-defined contract. The generated code from Protobuf definitions provides strong type checking at compile time, which reduces the likelihood of runtime errors that are related to data types.
GraphQL achieves strong typing through its schema definition language (SDL), which explicitly outlines the types of data that can be queried, along with their relationships. As discussed above, GraphQL schemas are introspectable, which allows clients to discover the available types and their fields dynamically.
Code generation
Automated code generation is one of the main benefits of gRPC. Developers begin by defining gRPC service contracts and data types in .proto files, which are then processed by the Protobuf compiler (known as “protoc”). This involves generating client and server code in various programming languages, such as Java, C++ Python, and Go. gRPC’s language-agnostic approach to code generation makes it well-suited for distributed systems and microservice-based architectures, in which services running on different nodes may have different runtimes.
While GraphQL supports code generation, it requires the use of external libraries and frameworks. These tools analyze the GraphQL schema and generate client-side code, including types, queries, and mutations. They can also generate server-side components such as resolvers and data models.
When to use gRPC vs. GraphQL
No API technology is a “one-size-fits-all” solution, and choosing between gRPC and GraphQL requires careful consideration of the specific requirements of your system.
gRPC is well-suited for scenarios that necessitate high-performance communication between services, making it ideal for microservices architectures. These distributed architectures also benefit from gRPC’s language agnostic approach, as microservices are managed independently of one another and may be written in different programming languages. Additionally, gRPC’s comprehensive streaming support makes it an appealing choice for applications that require real-time data exchange.
On the other hand, GraphQL is designed for flexible data retrieval, which makes it a good fit for applications with complex data requirements, such as e-commerce platforms and content management systems. GraphQL is also well-suited for applications that have different frontend clients for multiple platforms (like web and iOS), where each one has different data requirements. Mobile applications, in particular, will benefit from GraphQL’s precise approach to data fetching, which optimizes data transfer on slow or unreliable network connections. Finally, GraphQL helps aggregate data from multiple sources behind its API—and merges them into one schema. This is especially important for legacy infrastructures or third-party APIs that have grown over time.


New Research Architecure which is Competeor of MicroSoft and and Dast query execution apart from Graph ql ,Alternative solution of Graph ql