
Driving Search Intelligence with Query Understanding and Federation
Search at Postman involves querying over many different verticals of the product. We call these entities. For example, a collection or a workspace can be an entity. When we launched Postman’s universal search in 2020, the core problem we were solving was the discovery of a wide breadth of entities in Postman. This was crucial considering the amount and diversity of data produced and consumed on the Postman API Platform. It hasn’t been a one-step success, and we’ve been incrementally shipping a lot of changes to improve the relevance and scoring of our universal search by tapping and incorporating more signals into scoring, entity recognition, spell correction, and many other things.
Searching across Postman’s vast entities should not seem disconnected but should be unified. This is commonly referred to as “federated search.” Furthermore, merely matching text in these entities is not a very slick search experience. “Query understanding” has to be built for the analysis and enrichment of queries to provide an intelligent search experience.
In this blog post, we will talk about some of these problems, and how our Postman team tried to solve them.
Federated search across indices
The challenges we faced
Inside postman, we have multiple types of entities like collections, workspaces, and APIs to name a few, that a user can search through. These entities are different enough to have unique structures, metadata, metrics, and data volume. So, they are stored in separate Elasticsearch (ES) indices. Initially, when we built universal search in Postman, we took the path of showing results categorized by entities:
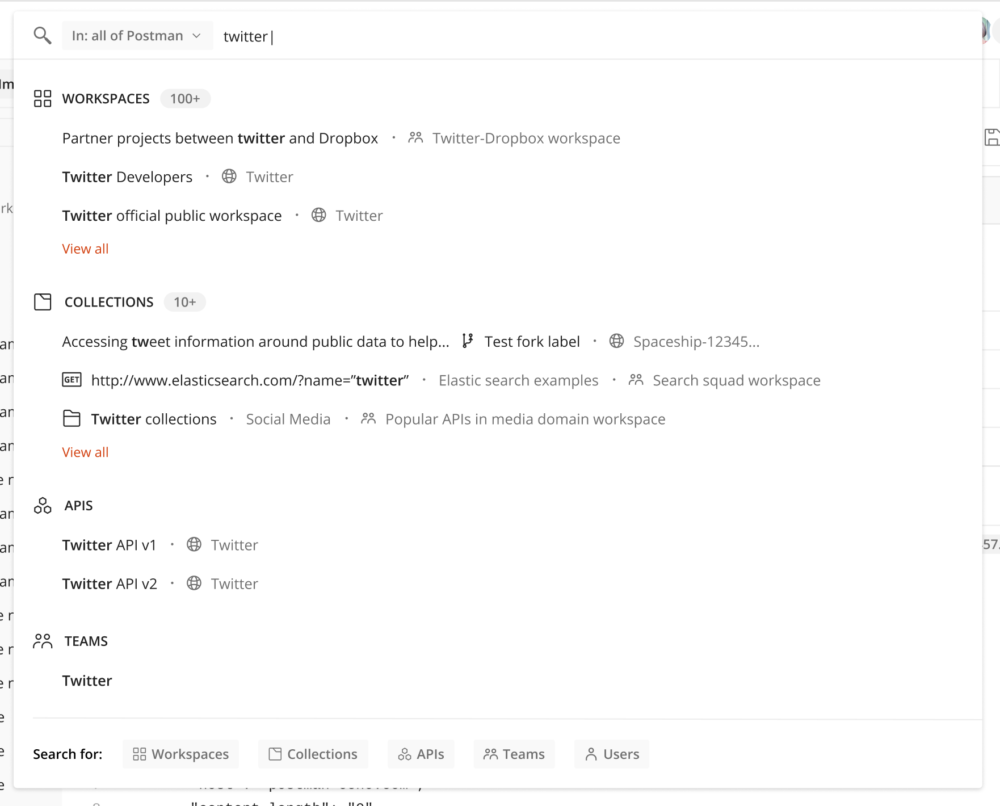
While querying the data, users could select the entity as a filter to narrow down the scope. This worked for the dedicated search result page as it provided a lot more options to customize the search using filters.
However, for the search dropdown, a unified result list that combines results from all entities by a federated search is a much better experience. Not only does it help users arrive at a useful result faster, it also makes adding more entities easier to the search product.
There are many ways of doing this:
- Storing different entity types in a single index was not considered because these entities have notably different schemas, metadata, and metrics. They have different classes of data too, and keeping them separated provides more customizability.
- Querying different indexes and merging them before returning them to the user. This could work with the indexing constraints. However, we had to be smart about it. We couldn’t simply merge and sort the results from different indices, as the scores returned by ES are index-specific. More on this in the next section.
How Elasticsearch scores work
Elasticsearch since the 6.0 version relies on the BM25 algorithm (by default) to arrive at the similarity score. There are plenty of resources on the internet that delve into the details of this algorithm.
One key property of BM25 is that the similarity score obtained from it is meaningful only in the context of an ES index. This is because the properties of a document used to compute the score are a function of index-specific properties. There are two such properties in particular that result in this behavior:
- Inverse document frequency: The measurement of how many times a term appears in an index. This is used to reduce the impact of common words on the final score.
- Field length normalization: The measurement of how long a field is in comparison to the average field length in the index.
How the results were merged
We needed a way to make the scores across indices comparable. This is a common problem in statistics when the dataset comprises multiple sources. In such cases, the data is scaled to make the comparison meaningful and avoid bias toward the dataset that is measured on a higher scale. This is referred to as “feature scaling.”
The two most common methods for feature scaling are min-max and z-score. Both of these methods work on datasets of arbitrary ranges and reorganize them into a smaller range while preserving the relative order of data points.
Min-max formula:
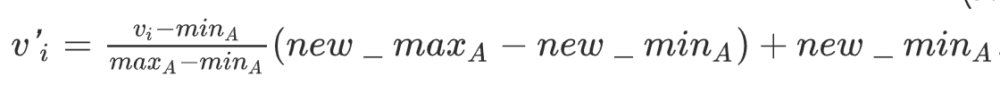
Here, new_max and new_min are the new ranges in case we want to scale the data outside the default [0, 1] range.
Z-score formula:
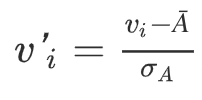
Here, Ā and σ are the mean and standard deviation, respectively.
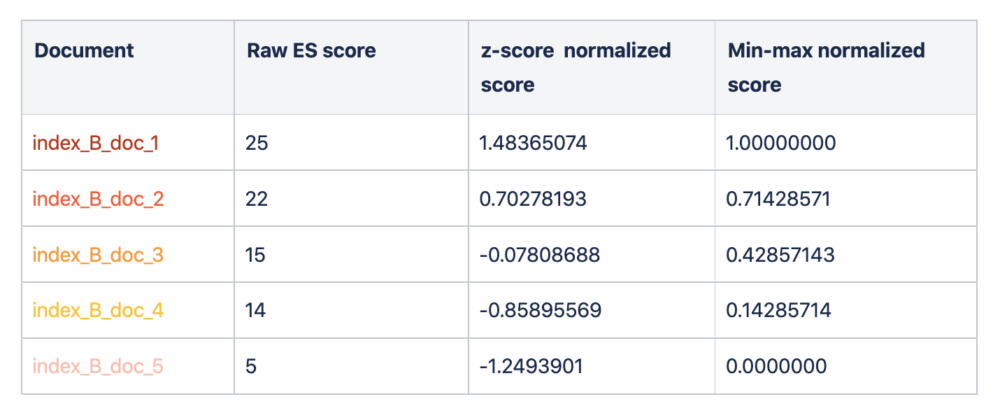
Let’s understand these with an example. In the table below we have a combined list of documents from two different indexes.
Index A:
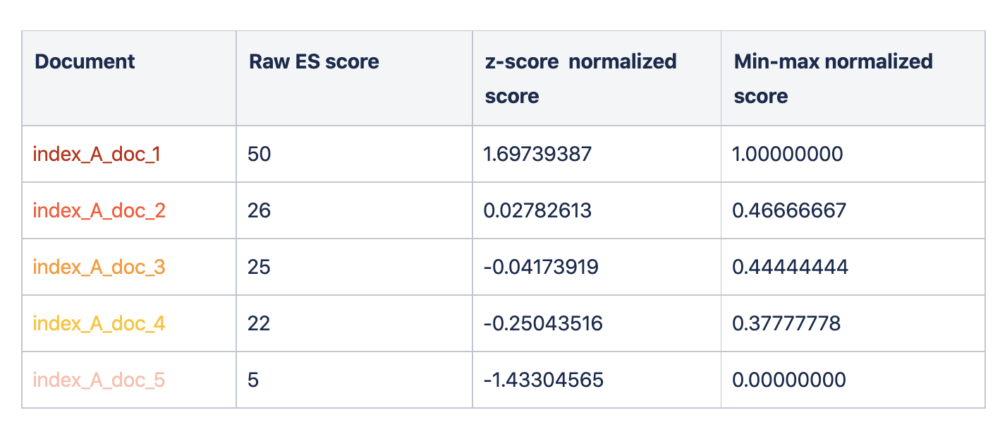
Index B:
Result order:
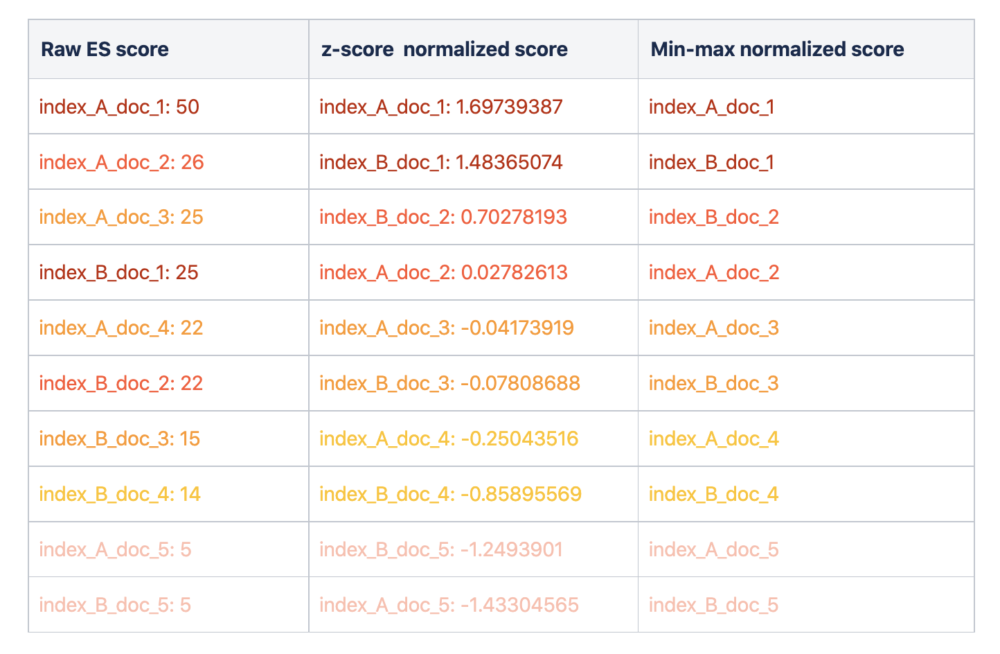
As you can see above, combining results based on raw ES scores led to a bias towards index_A, as it had overall higher scores. Whereas scaling the ES scores resulted in a better merging of results.
The min-max method uses a simplistic approach where the maximum and minimum values of the dataset are the boundaries of the new scaled range and all other values are proportionally fit inside this range. This can lead to outliers causing a biased result.
The z-score method depends on deviation from the mean of the dataset, handling outliers comparatively better and distributing data more evenly over the range.
Since the scores in ES are dynamic and outliers cannot be ruled out, we chose to go with z-score scaling. This normalization module was implemented at the application layer that interfaces with the ES cluster.
Once we knew how to normalize the scores, getting the results from all the indexes was simpler. We used the multi-search API provided by ES. This saved multiple network calls to ES and offloaded querying multiple indices to the ES cluster. In multi-search API, ES queries the indexes in parallel and hence the performance is not compromised.
The index-wise results returned by the multi-search API were then passed to the normalization module. After normalization, the scores are merged and sorted before returning the top results to the client.
This is what the final result looked like: a much cleaner and more intuitive UX. However, we believed this could be improved further by understanding what exactly the user was looking for.
Query understanding for better scoring of results
Why this was needed
The ES scoring algorithm is exceptionally good at retrieving relevant docs, based on textual features of the documents. However, every search product is different and product-specific insights can be used to further improve the relevance of the results beyond the BM25 algorithm.
Now that we solved the problem of providing federated search to users, we decided to look a step further—we wanted to try to understand the intent of the user to serve them better results.
How we did it
Since the launch of universal search, we have been tracking and measuring user interactions with the product. Over a few months, we acquired a significant amount of data around search results consumption.
By grouping the consumption metrics by entity type, we knew the relative consumption of each entity type. We also knew what the users were querying and what the click-through result for that query was.
We decided to use this data to predict the user intent for the queries and re-score the results to better answer the queries.
Static boosting based on consumption
Below is an example showing what the entity-wise consumption looked like after a few months of releasing universal search:
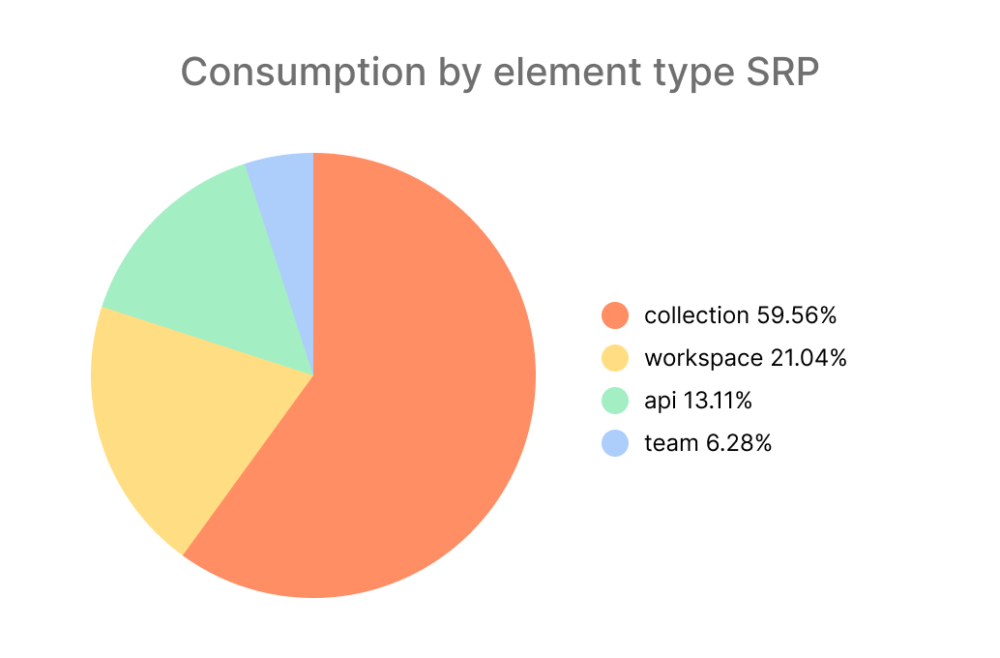
We had a federated result list, with normalized ES scores, without any Postman-specific context in the results. As a first step toward intelligent search, we decided to augment these normalized scores with the respective probability distribution. There can be many approaches to changing the normalized score based on probability distribution. For example, the formula can be as simple as:
new_score = normalized score + (probablity distribution * normalized score)
Borrowing from the example above:
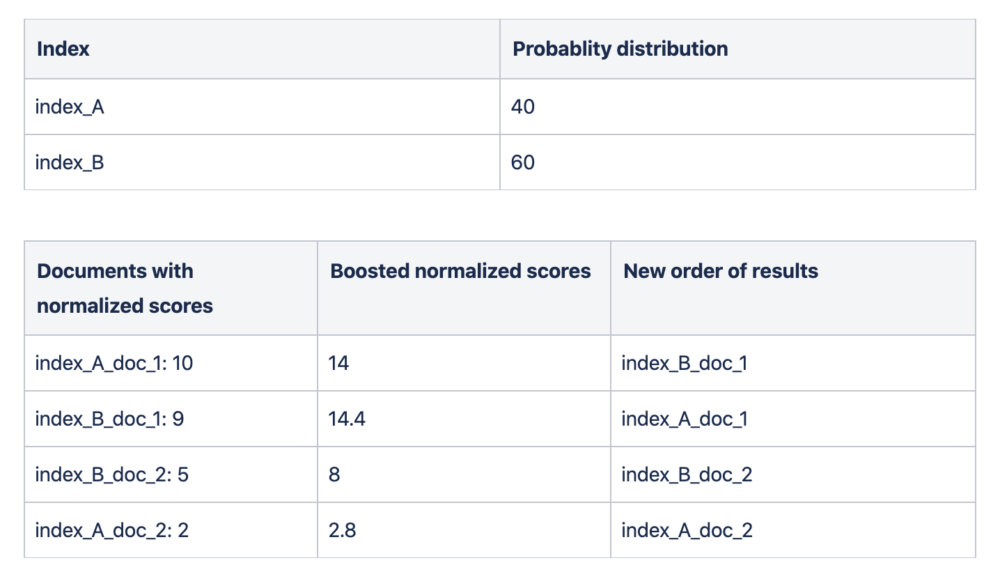
This resulted in entities that are more likely to be consumed based on past usage being pushed up in the result list, much better than simply merging normalized scores.
Building query understanding
Static boosting based on result consumption greatly improved the relevance of the result list. However, we had more interesting data around usage and we believed we could do better. Rather than boosting result scores using a static entity-consumption ratio, we wanted to dynamically predict the entities the users were more likely querying for.
The question we wanted to answer was: Given a query input, what is the probability distribution of the query being intended for a collection, a workspace, an API, etc.?
As with any statistical prediction problem, the most crucial part was getting the data right.
To begin with, we started by looking at one facet of the data such as:
- What were the exact queries users were making?
- What were the corresponding results being consumed by the user?
- What were the entity types (i.e., ES index) for these consumed results?
But the data could not be used directly for training any models, as it had many irregularities such as:
- Incomplete queries where the search-as-you-type feature allowed users to consume a result even before the query was fully typed.
- Queries with spelling errors, where ES still returned results due to sub-phrase or edge nGrams being matched.
- Queries with special characters that didn’t necessarily contribute to matching, and so on.
These issues are common in data science and there are methods to clean and enrich the data. But to perform enrichments like spell correction and completion, the standard human language corpus was not enough. Postman is an API development platform and most of the keywords we perform searches on are technical jargon and abbreviations.
So we went ahead with constructing a custom corpus from the data that existed inside Postman. To ensure the quality of this corpus, we defined a rule-based quality score using the properties of the entities. These properties could be as simple as a number of results in a collection or the number of users watching an API. Using this quality scorer, we created the custom word corpus with only the data that cross a quality threshold.
This corpus was used to build data enrichment and other query analysis models, for example:
- Trie-based text completion model, to complete incomplete queries before training.
- Language generation using symspell-based spell correction mode. This enabled query correction before querying ES.
- Named entity recognition (NER) model using spacy to identify names in the queries.
After cleaning and enriching the data, we had to develop a multiclass classification model, which could perform query entity disambiguation and tell us the likely target entity for a query.
We ruled out deep learning for the classification because we observed that the queries being made in Postman did not have any semantic structure but were mostly keywords. We went ahead with machine learning models because they fit our requirements.
We trained several ML models like Logistic Regression, Random Forest, SVM, KNN, Multinomial Bayes Classifier, etc. with various vectorizers for textual features. We found SVM with TF-TDF vectorizer to have the best accuracy (at around 90%).
The probability distribution predicted by SVM was used to boost the normalized scores instead of the static probability distribution mentioned in the previous section. This further improved the relevance of the results.
We took this opportunity to add further language understanding to the queries:<
- Since URLs are one of the most queried entities in Postman, we built URL identification (query intention) which could then be used to dynamically boost the results that have a match in the URL field.
- Queries often included the team names, like “Twitter auth API,” where it made sense to boost entities owned by that particular team. Here we used the output from the NER model for dynamic boosting.
End result
After adding the above components for query understanding, we arrived at a system with the following subsystems. While language generation and language understanding kick in as preprocessing before querying ES, the normalization and blending take place after we get the results back:
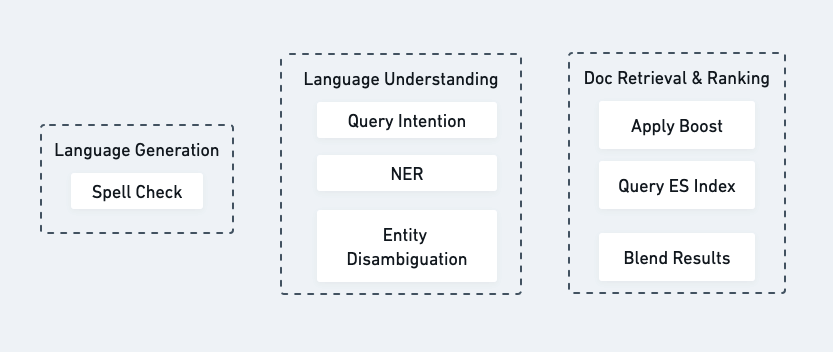
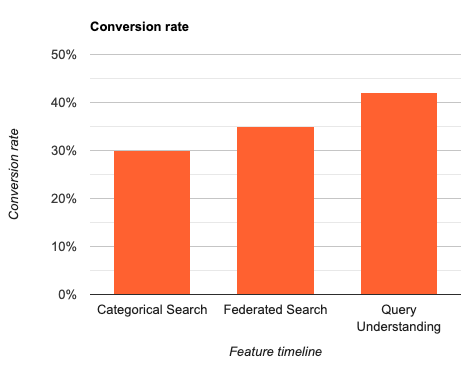
Since the release of the federated search and query understanding system in 2021, we have seen the search conversion rates (i.e., percent of search results successfully consumed) go up, and that highlights the success of the engineering efforts. The conversion rate before these initiatives was about 30%. We saw this jump up to about 35% in the months following the federated search release. The conversion rate was further improved to about 42% after the query understanding efforts—and it’s consistently increasing as we improve it even further.
This system is still in its early stages though. There are many improvements on the roadmap ahead—like semantic search, better feature engineering, and better analysis of query intention. We plan to incorporate user-specific interactions and behavior to further improve search result relevance, instead of relying on a user-agnostic approach. We are also focused on providing a more powerful and customizable search over request URLs and API schemas, as well as near real-time data replication in ES. Stay tuned for future blog posts to learn more.
Did you find this blog post interesting? If so, you might also be interested in working at Postman. Learn about joining the Postman team here.

What do you think about this topic? Tell us in a comment below.