
How It Works: The Postman Data Team’s Hub-and-Spoke Model
The structure of a team is crucial to its success. Structure helps us determine the various communication patterns that enable a team to contribute to the organization’s overall growth. In this blog post, we’re going to talk about the structure of Postman’s data team, which includes our data engineers and data analysts.
Before going ahead, let’s look at the two team types we have at Postman:
- Type 1: A team that builds a user-facing product or feature
- Type 2: A team that works behind the scenes and helps Type 1 teams reach their goals
At Postman, we call Type 2 teams “foundation teams.” Foundation teams are the heart and soul of Postman; they help cater to the overall organization by building easy-to-use and highly effective platforms and internal products. Hence, the communication mechanisms (powered by the structure) of the foundation teams have a huge impact on the value that those teams can add to the organization.
The data team is one of these foundation teams, and we’ve adopted some specific approaches to help us achieve our goals.
The Hub-and-Spoke Model
While doing research to help us choose the most potentially effective team structure, we came across the hub-and-spoke model. This model dates back to the 1950s and was often used in the transportation industry as a way to distribute goods across various consumers. (You can read more about the history of the hub-and-spoke model here.)
Relating the underlying mechanism with our own use case, we discovered that we actually have a similar problem statement. Namely, much in the way that the transportation industry needs to get passengers outward to many destinations from a central hub, we have data-infused knowledge that we would like to share more broadly—and we need a channel or mechanism to disseminate that knowledge outward to the rest of the organization.
The above realization was a breakthrough for us. In addition to this, we imposed a few constraints on the structure as a measure of system design (more on this in the next section) which helped us build something really effective that we’re excited to share.
Designing the team structure
To design our team structure, we started the way we start most projects: with a problem statement.
Problem statement
We need to create a brand-new structure for the data team that enables superior scalability, efficiency, innovation, and communication.
Constraints
Once we had our problem statement, we looked at some of the constraints we faced.
The structure of Postman’s data team should be built on the following foundations:
- The data team should enable the organization to make decisions. (We consciously took this direction so that the data team doesn’t become a service-oriented team. More on this later.)
- The data team should scale sub-linearly with the organization. (By this, we mean that if the company grows to, say, 10x its original size, the data team shouldn’t need to grow 10x, too.)
Why should the data team scale sub-linearly? Taking an excerpt from the book Scale, we can think of the data team as a kind of gas station that fuels success. Let’s see how the number of gas stations can scale:
“Infrastructural measures, such as numbers of gas stations and lengths of roads and electrical cables, all scale sub-linearly with city population size, manifesting economies of scale with a common exponent around 0.85.”
— Scale, by Geoffrey West
Since Postman is split into multiple teams (across domains such as business, sales, engineering, etc.), the data team’s structure should be able to incorporate every domain’s problem statements and help them get the answers without growing to an unwieldy and inefficient size.
Our Solution
Given the above constraints, we built the first iteration of our solution, which is summarized in the following three team types:
- Central: A central team caters to the larger audience and solves analytical problems with limited context. At the same time, this team understands the pain points and builds products/platforms to make decision making self-served.
- Embedded: An embedded team gets activated when we need to deep-dive into an analytical problem.
- Distributed: A distributed team is fine-tuned within a contextual boundary of a domain and only caters to that domain.
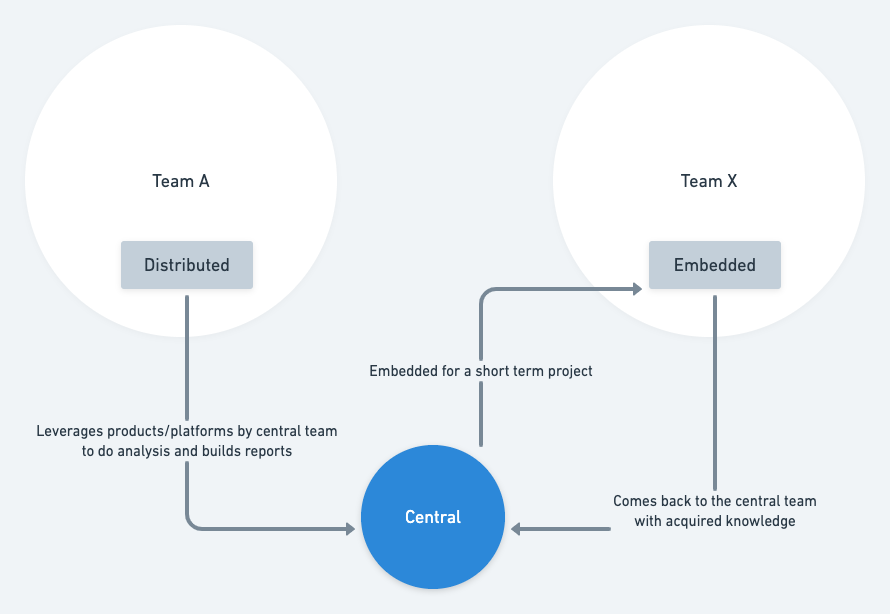
In short, the central team is a “hub,” and the embedded and distributed teams are the “spokes.” This is our hub-and-spoke model.
Benefits of the hub-and-spoke model
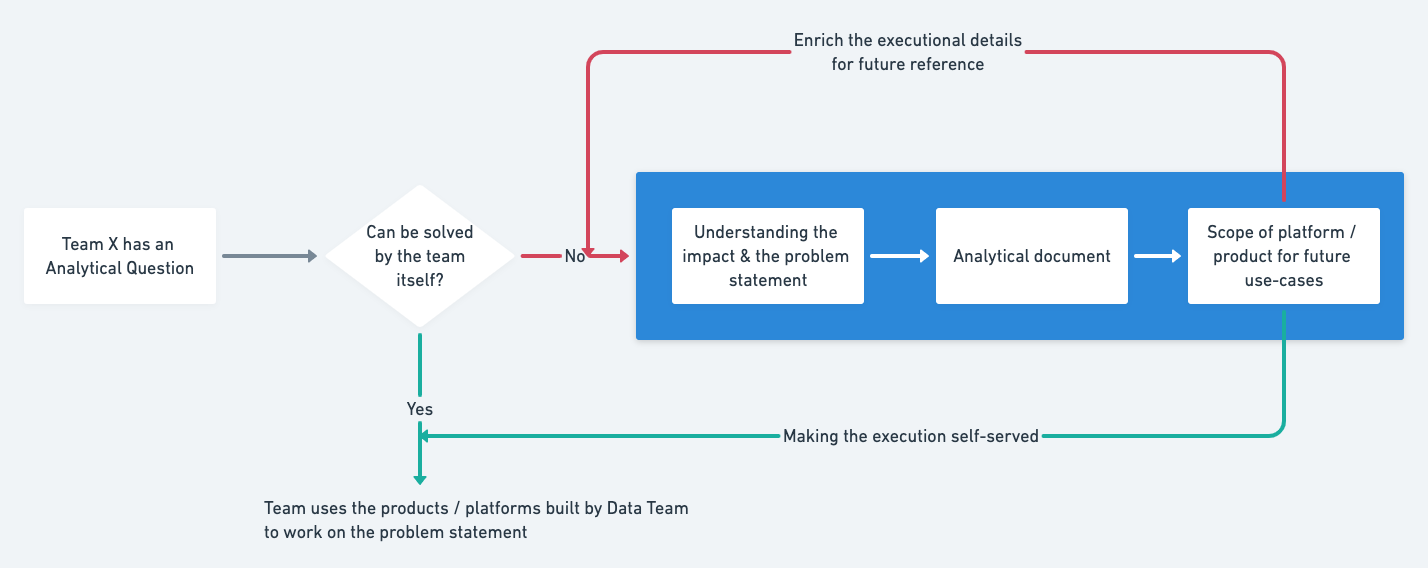
With this model, we can now tackle problem statements at scale. As the above diagram depicts, every problem statement (e.g., “Team X has an Analytical Question”) is treated as an experiment where we can build a platform/product as an outcome. However, not every solution can be self-served in this way, hence we also continuously build a knowledge repository over time so that the net-new effort required to work on a problem statement decreases over time.
In cases where we do get to build products—like a recent product that we built for forecasting (for any time-series graph)—we ensure that the usage of that product becomes streamlined over time.
Product/Platform Mindset
Building each product/platform is not just an executional activity based on the hub-and-spoke model; we believe this activity also requires a certain mindset in addition to the model. The Postman data team made a conscious choice to use Objectives & Key Results (OKRs) as a way to standardize that mindset and measure product metrics over time, including tracking our acquired, active, and retained users across every feature that we provide. This product/platform mindset, as embodied by OKRs, along with the power of the hub-and-spoke model, ensures that the data team is moving in the right direction as we continue to democratize data for the entire Postman organization.
Does this topic interest you? If so, you might also be interested in working at Postman. Learn about joining the Postman team here.

Is it safe to say that the Central Team builds dimensional models and dashboards based on the questions the Distributed Team wants answered, and the embedded team works on more analytics intensive questions, figuring out the right features that could answer the questions and pass on back to the Central team? If that is the case, have you faced any challenges with Distributed Teams wanting to build their own Analytics Intelligence subteams, acquiring cloud solutions for the same? In other words, does all of Postman know of and acknowledge the relevance and importance of a central analytics team?
Hey Janani, regarding the distributed to central team communication, either one of them could contribute to the dimensional models. Central team enables a platform for any distributed team member to come and contribute to the central repository of dimensions.
All 3 teams i.e. central, embedded and distributed work on analytical intensive questions. The only difference is the fact that central team also does additional platform building work hence they get to scratch the surface of the most analysis specific work. As soon as the complexity of the problem statement increases, one of the team members get embedded to dedicatedly work on the problem statement.
Regarding building features, central team takes inputs from embedded and distributed teams and also listens to various usage signals to build those features. Distributed teams can build analytics intelligence subsystems with a partnership with central team. This constraint is imposed so that we don’t have siloed systems or knowledge. In a way, we would like to truly democratize everything. 🙂
Hope this answers your questions.
Great post Shubham….but request you to change the font colour of your blog….the grey is too light to read.