
Embedding Security from Code to Cloud
Earlier this year, we shared that Postman had joined Wiz’s Zero Critical Club, a milestone that reflects a deliberate, engineering-first approach to security we’ve been building for some time. That post covered the outcome. This one is about how we got there.
As Postman grew, we encountered a problem every scaling engineering organization eventually faces: security findings arrived too late, were too stripped of context, and sometimes in volumes that were hard to keep up with. Even with dedicated security engineers embedded in product teams, the feedback loop was too long. A misconfiguration deployed on a Tuesday might surface as an alert weeks later, by which point the engineer who introduced it had to reconstruct context from scratch.
We also had a review bottleneck. Every release touching security-sensitive surfaces required a manual review, and our team wasn’t large enough to turn those around at the pace engineering was moving.
Our response was to build a program that addresses both problems at once: get findings to developers earlier and with more context, and automate the judgment calls that don’t require a security engineer’s time so that the ones that do get faster attention.
A Pipeline Built Around the Developer
Our security controls span four stages of the software delivery lifecycle, and ensure that findings are evaluated consistently across all of them.
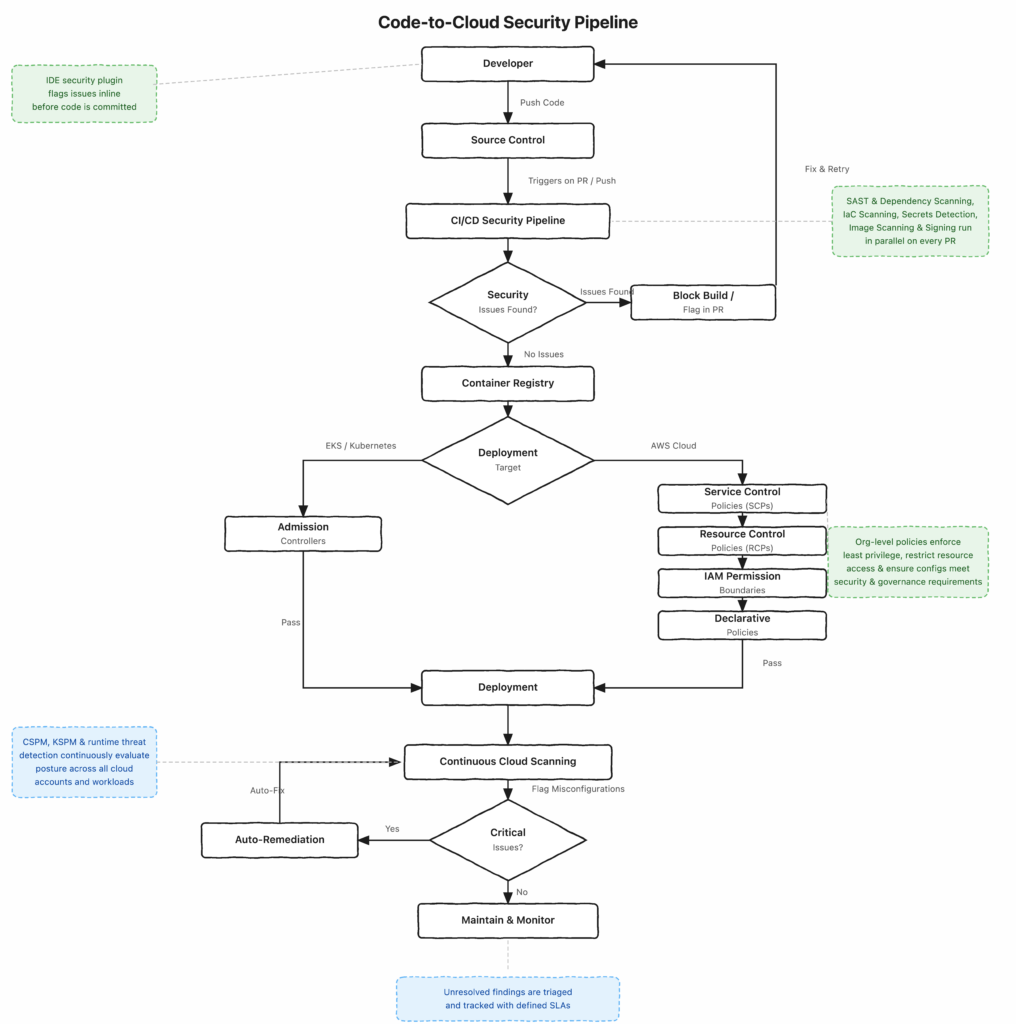
Code: Developers have Wiz IDE integrations that flag vulnerabilities, misconfigurations, and exposed credentials inline as they write, with no context switch required. Push protection is also enforced across our repositories, blocking secrets from ever reaching source control. Developers can also run on-demand CLI scans against their local working directory before pushing.
Build and Deploy: When a pull request is opened, multiple scans run in parallel with the build. Static analysis, dependency scanning, secrets detection, along with scans for infrastructure definitions across Terraform, Kubernetes manifests, and our internal deployment configuration format, surfacing misconfigurations as inline PR comments before anything touches our cloud account. Container images are scanned before and after push to our registry, to ensure that we have a full context of where the issue originated from in the runtime. We’ve also extended the standard ruleset with custom policy checks specific to Postman’s infrastructure patterns, because commodity scanners don’t understand our internal service topology.
Cloud and Runtime: We run continuous CSPM and KSPM across our AWS accounts and Kubernetes clusters. The capability that most directly affects remediation speed is code-to-cloud traceability: when it flags a vulnerability in a running workload, the finding traces back through the container image, the CI/CD build, and the specific commit in our GitHub repository that introduced it. This connects directly to our Product Security Scorecards framework, keeping team-level attribution accurate and maintained. Findings are additionally enriched with contextual exposure scoring, so teams focus on what truly reduces risk rather than triaging on CVSS score alone.
Finding issues early matters, but closing them fast matters just as much. For a while, we had the detection side working well, but remediation was still a manual process end to end, CSPM/CNAPP would flag something, a ticket would get created, it would sit in a queue, an engineer would eventually pick it up, triage it, apply a fix, and close it. For genuinely complex issues this workflow makes sense, but a portion of our findings were low-ambiguity misconfigurations where the correct fix is deterministic. Running those through the same manual process was creating unnecessary backlog and pulling engineering attention away from work that actually required judgment.
So we approached this at two levels:
The first was to eliminate certain categories of misconfigurations by building a layer of preventive controls. We kept discovering the same classes of issues recurring, unencrypted databases getting created, Lambda functions exposed without IAM authentication, resources inadvertently accessible to principals outside our organization without approval, among others. So we implemented organization-wide guardrails using AWS Service Control Policies, Resource Control Policies, and declarative policies that deny these configurations at the AWS organization level before anything gets deployed.
The second corrective level handles everything that guardrails don’t cover, either because the issue type doesn’t lend itself to a preventive control or because it exists in infrastructure that predates them. For a set of these, we built auto-remediation functions that apply the fix directly at the infra level, the moment a misconfiguration is detected. This covers corrective actions like blocking public access on S3 buckets and SNS topics, tightening overly permissive SQS policies, restricting IAM role trust policies, and other controls that prevent unintended public exposure.
Edge: Our external attack surface is continuously monitored for unexpected exposure, with Cloudflare providing a defense layer in front of external-facing services.
Measuring Where We Stand: Cloud Security Maturity Model
For a long time, we didn’t have a consistent way to answer a basic question: how secure is our cloud environment, broken down by team? We had findings, we had scan results, but we didn’t have a structured picture of posture across the organization. Different teams were at very different levels of cloud security maturity, and we were largely making investment and prioritization decisions based on incomplete information. Resources weren’t consistently mapped to the teams that owned them, which meant that when something was misconfigured, attribution was often a best guess.
We’ve built a Cloud Security Maturity Model to fix that. Every cloud account is mapped to its organizational unit – OUs in AWS, Management Groups in Azure, and Folders in GCP.
Each OU gets a maturity score from one to five, broken down across the domains that matter most: IAM, Network Security, Data Security, and Logging and Monitoring, to name a few. Scores are derived from control-based validation, so they reflect what’s actually deployed, not what teams intend to have in place. Each of the OUs has a defined target maturity level, and the gaps between current and target are mapped into improvement roadmaps. The count of critical gaps and the delta between current and target maturity feed directly into our Product Security Scorecards, so gaps become tracked work items with owners rather than observations that quietly age on a document. This gives us a consistent, data-backed way to have conversations about posture, prioritize the right things for maximum impact, and make sure improvements are tracked rather than assumed.
How We Stopped Being a Release Bottleneck
The pipeline above makes Postman more secure. It also makes it faster to ship.
By the time a release reaches the security review gate, it has already been evaluated across multiple scans. But instrumentation alone doesn’t solve the queuing problem, so we built something to address that directly: the security release triage bot, which we’ll be going into depth about in our next blog.
What Developers Actually Experience
The above was designed with one constraint in mind: it has to work for developers, not just security teams.
A lot of that is down to secure defaults and guardrails doing the heavy lifting quietly. A large class of misconfigurations simply can’t be introduced because the platform doesn’t allow them. Developers don’t experience those as security interactions at all, which is exactly the point.
The net effect is that security has largely stopped being a reason releases slow down. Low-risk changes ship without waiting. Complex ones get thorough reviews faster because the context is pre-assembled. Engineers spend less time reacting to decontextualized alerts and more time building.
When engineers disagree with a finding, they can flag it directly from the PR and loop in their security engineer. That feedback improves rule quality over time and reinforces something we care about: security engineering is a collaborative function, not a checkpoint to clear.
We look forward to sharing more as the program evolves.



What do you think about this topic? Tell us in a comment below.