
How Postman Engineering Does Microservices Today
A couple of years ago, Postman Co-founder and CTO Ankit Sobti wrote about Postman’s struggle to escape from a microservices-dependency hell. (If you want to learn more about how and why Postman ventured into microservices, I highly recommend reading that blog post.)
This is an update on Ankit’s story— specifically, I want to walk you through how Postman does microservices today. It’s a story about domain-driven squads, consumer-driven contract testing, and a continuously refined process.
First, an overview of the Postman engineering team

The engineering team at Postman has more than 100 engineers working across eight locations around the world, and the team and its structure are constantly evolving as with any growing startup.
Let’s dive into how these teams are organized because, as we’ll soon see, the org structure really impacts our microservices implementation.
With a microservice architecture, how do you organize your teams?
“Any organization…will produce a design whose structure is a copy of the organization’s communication structure.” — Conway’s Law
According to Conway’s Law, software starts looking like the organization that creates it. How people in a team communicate and collaborate—and even which tooling they choose—can significantly influence the output.
This is one reason why organizations like Amazon and Netflix work in small, independent teams. It enables API-first design and development. (Read more about API-first software development here.) This structure is represented as the well-known microservices DeathStar.

You can observe Conway’s Law by comparing products from teams grouped by function (e.g., backend), by product (e.g., iOS), or by workflow (e.g., design).
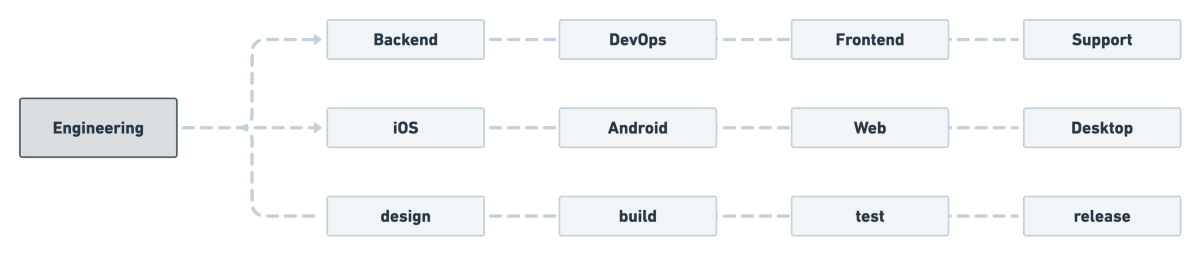
Sometimes Conway’s Law can have unintended consequences. One way to combat the challenges but still take advantage of the phenomenon is by using the Inverse Conway Maneuver, which proposes that you can change your organizational structure in order to change the technical structure that you desire. How your organization communicates and collaborates will shape the end product you create.
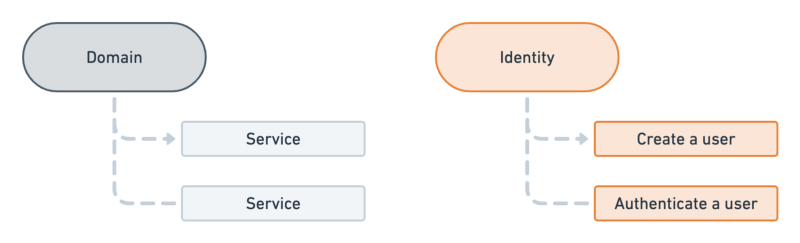
Keeping this in mind, development teams at Postman are organized into groups we call “squads.” Postman squads operate on domain-driven design (DDD) principles, which free up each squad to focus on its core domain.
For example, one squad owns the Identity domain. The Identity squad produces services like Create a User and Authenticate a User, among others.
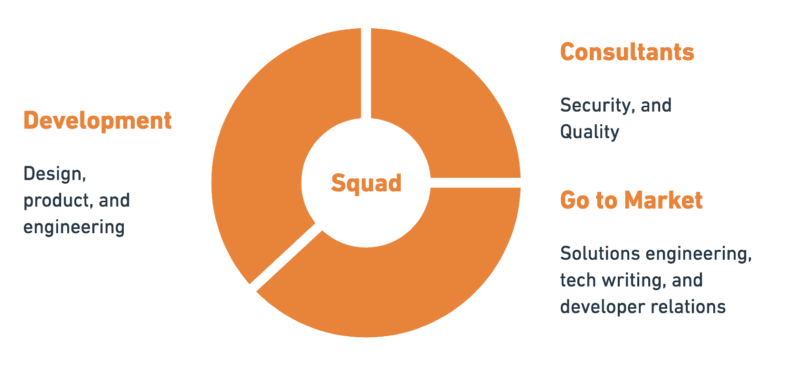
Across our company, there are 12 squads that produce 40 services for Postman engineering. For the most part, each squad independently manages its roadmap and sprints. They each have some freedom to choose their own tools and configure their individual work processes.
Although squads are focused on their specific service, they are cross-functional, with dedicated members from design, product, engineering, security, quality, technical writing, and developer relations (that’s me!).
In the next section, let’s see how a squad creates and maintains a new service.
With a microservice architecture, how do you create and organize new services?
Let’s imagine the Identity squad wants to produce a new service to authenticate an existing user. There are many ways to skin a cat, but within Postman’s microservice architecture here’s how Postman engineering would do it.
Step 1: Create a team workspace
In Postman, the Identity squad service owner is the producer of this new service. This producer creates a team workspace as the single source of truth for the new service so that every member of the squad always has the most up-to-date data about the project.
A workspace is the foundation for collaboration in Postman. As we’ll soon see, the workspace contains the expected behavior of the service. Unit and integration tests live here. And it’s the central thread for all the communication during and after development.
Now that the Identity squad has created a team workspace, it’s time to move on to step 2.
Step 2: Draft a blueprint collection to describe use cases
Within the new workspace, the Identity service owner drafts a Postman Collection to describe their service. This collection is like a blueprint, with proposed examples of a request and potential server responses to describe various use cases. In fact, the name of the collection includes #blueprint as a tag indicating its purpose.
Step 3: Negotiate how the proposed service will function
The blueprint collection is a proposal for how the service will function. Potential consumers of the service then weigh in on the design, either offline or via threaded comments in the app, to shape what the service will become.
Step 4: Enable parallel development with mocks
In this context, I’ll be using the word “mock” flexibly to indicate mock server, mock service, or mocked response. Once all stakeholders successfully negotiate the design of the service, the collection becomes an agreement, or contract, for the new service. Those examples of requests and responses inform mocks that enable parallel development.
The mock is a contract between the producer and consumers of this service. Both parties can start developing their code at the same time. Tests are written. Documentation begins. All this activity occurs in parallel and is driven by an agreed-upon vision of the new service as outlined in the blueprint collection.
With a microservice architecture, how do we know when something is broken?
When we’re ready to deploy the service, we test to ensure that no workflow is broken. One of the most powerful tools that the Postman engineering team has adopted to manage microservices is consumer-driven contract (CDC) tests.
CDC testing
In the previous section, we talked about how the producer relies on the blueprint collection (which has now become a contract) to propose, negotiate, and then establish how their service will be used.
Once that contract is agreed upon, consumers write tests using the mock servers as a reference point. The consumers only test the endpoints and properties that they need, saving the tests in a collection. Once again, the names of these collections include #contract as a tag indicating its purpose. These test collections are maintained within the producer’s team workspace.
When the producer is ready to deploy their service, the consumer’s contract tests are run against the code as part of their continuous integration (CI) pipeline.
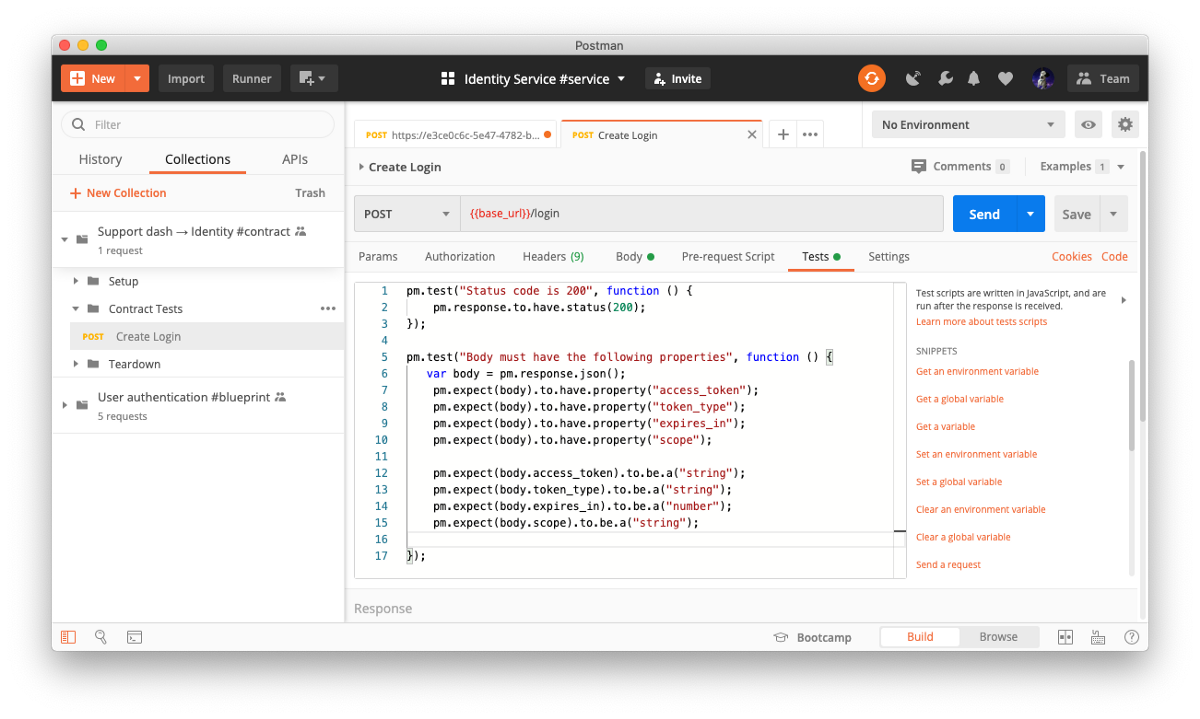
The service owner pulls all the collections within the team workspace using the Postman API, looking for any collections with the #contract tag to run. They use Docker to configure their own environments and deploy their code in the CI/CD pipeline, and rely on Newman to run the collections in the container.
The code changes deploy only after the contract tests pass.
Continuous testing
In addition to running contract tests on demand as part of the CI pipeline, Postman engineering runs a plethora of other tests on a regular basis.
Our engineers schedule Postman monitors that run test collections from Postman servers. These alerts and summaries are piped into Slack and email to ensure we’re keeping tabs on the service throughout the day.
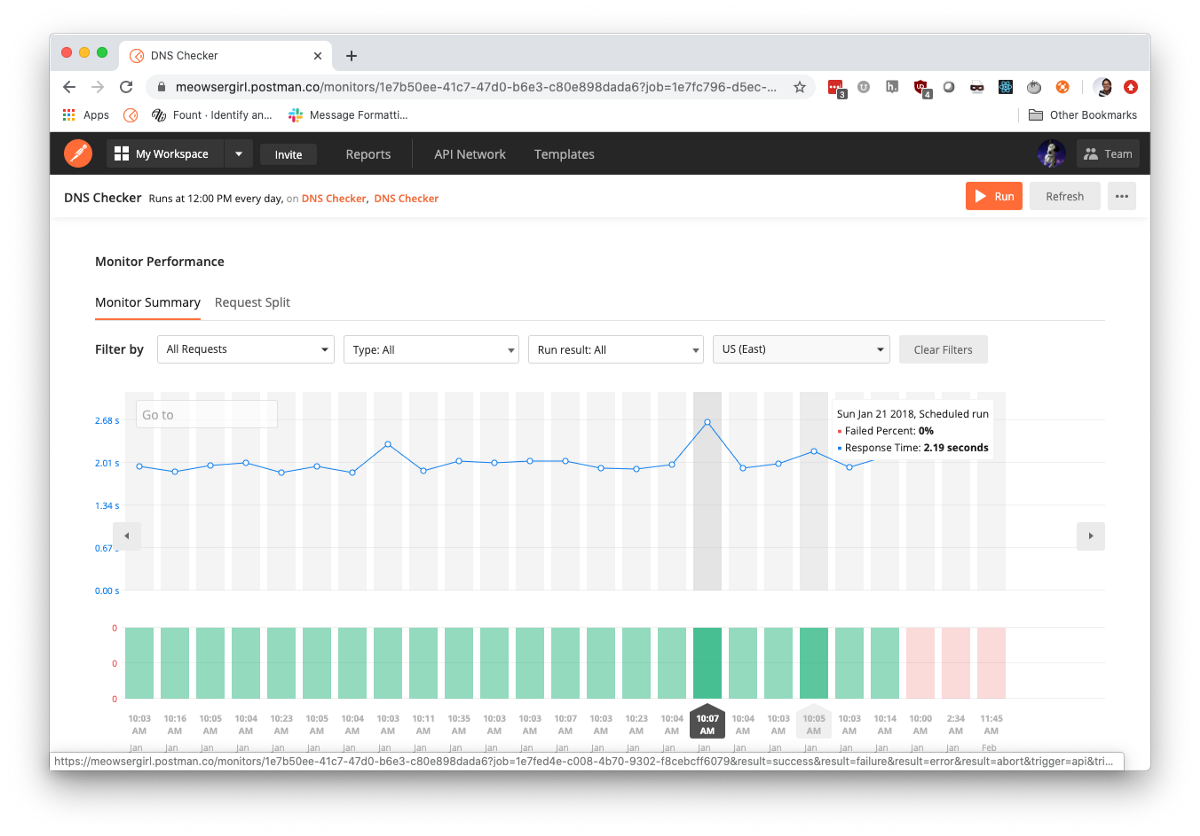
So Postman engineers rely on tests that run on demand and continuously. On-demand CDC testing in the CI pipeline allows service owners to deploy updates with confidence that they’re not breaking somebody else’s code. Continuously running other tests on monitors also ensures nothing is broken after deployment.
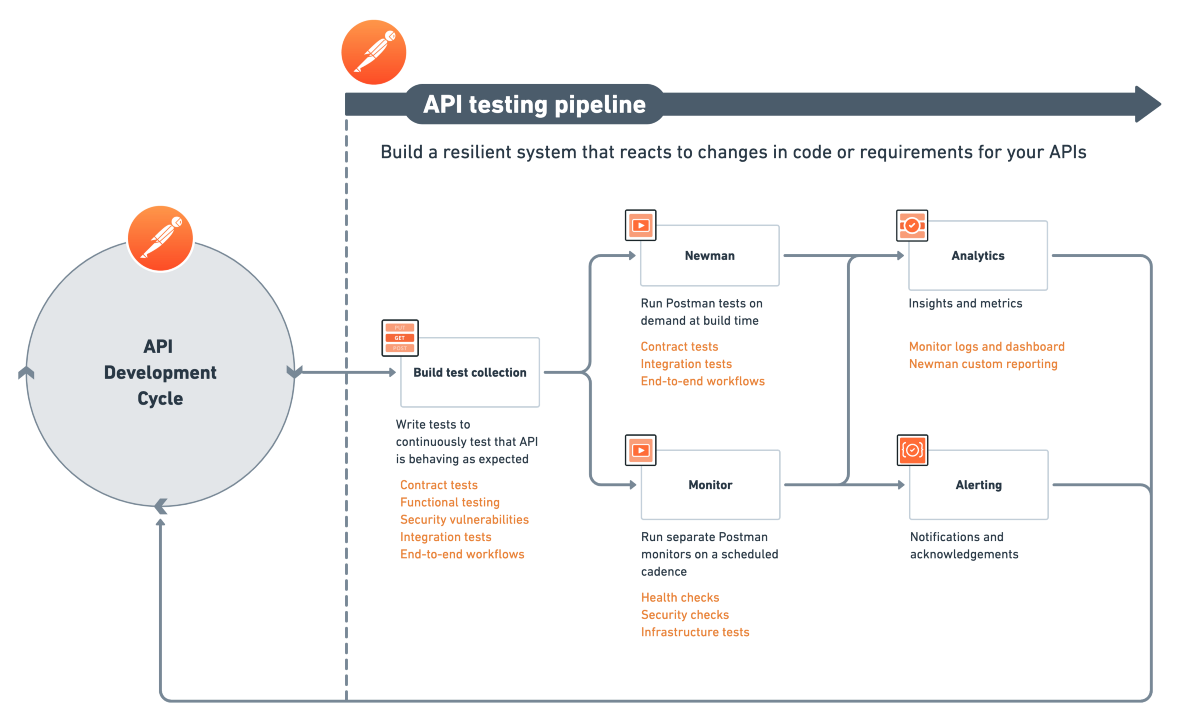
All of this informs an ongoing feedback loop that allows the engineering team to continue evolving and updating their services.
Is that happily ever after?
No blog post about microservices will ever conclude with a tidy bow at the end indicating that the work is done and the journey is completed. All microservices architectures are a constant work in progress.
As you can probably imagine, Postman engineering uses the Postman product quite a bit. Which means that we’re the first canaries in the coal mine. If something doesn’t work smoothly or it can be done better, we have the opportunity to feel the pain first. This allows us to iterate quickly on new features.
Conclusion
So now you’ve gotten a peek behind the curtain as to how Postman is working with microservices today, and how we’re continuing to address our daily challenges including:
-
-
- Dependencies on other squads require additional coordination. One squad’s roadmap might be blocked by another squad’s progress, or at least be subject to their service levels.
- Squads are relatively new, and each squad is independently figuring out what processes work best.
- In domain-driven design, domains require constant evaluation. For example, squads focused on large domains that require a large share of responsibilities debate the trade-offs between managing a microservice vs. a monorepo vs. a monolith.
-
- If you want to learn more about microservices, then check out Ankit’s original blog series about Postman’s initial foray into a microservices architecture. And keep your eyes peeled. We hope to share more updates and stories from the microservices trenches soon.

Above all a great example of a vendor eating their your own dog food. Well done and ensures the 100 or so Postman engineers are customers first.