
How (and Why) Postman Built a Knowledge Repository
You may have heard this line before: “Data is the new oil.” It’s simply meant to convey the immense value of data, and I agree with that, but there’s more to this metaphor. Like oil, data requires a lot of processing and cleaning to realize its full power. For it to be truly informative and for teams to fully derive knowledge from it, data must be processed in a structured and organized way. Unlike oil, data—and the insights derived from it—can be reused.
But how do you make sure that these insights reach the right people, can be validated quickly, and trigger the relevant actions so that data has that oil-like power? Organizations of all sizes must address these needs when they are trying to become a data-driven operation.
Let’s look at two hypothetical scenarios influenced by how data insights are managed:
Scenario 1: A new analyst joins your data team
- They start with a new analysis in the marketing department of your company.
- How do they learn more about the data terminologies related to the marketing domain, what analysis has already been done in the marketing domain (to derive better insights and not have to reinvent the wheel), and what data to use?
Scenario 2: A new product manager joins your organization
- They have some hypotheses about a current product and want to validate them using data.
- They also want to understand how some of the earlier decisions were taken based on data.
- How do they find and understand what analysis has been already done for their product, what insights were derived, and again what data to use to further test their own hypothesis?
In this article, we’ll discuss how Postman’s data team has tackled some of the challenges faced in common scenarios like the above. By implementing an internal “knowledge repository” that is easy to navigate, the Postman data team ensures that we can help everyone within the organization efficiently make data-driven decisions.
Postman’s data team
The use of the Postman API Platform has grown tremendously over the last few years—from approximately 2 million users in 2018 when I joined, to more than 12 million users as of August 2020. With this growth, we have also seen an increase in internal data consumption. In Postman’s beginnings, less than 10 people in our organization required insights from the data team; now we have more than 120 people a week across the company looking at various dashboards, reports, and analyses produced by the data team. (Read more about this in the blog post How Postman Does Data Democratization.)
What is a knowledge repository?
We call it a knowledge repository, instead of a data repository, because this repository is not actually housing physical data, but knowledge around how to use that data, what that data is, and most importantly why that data exists. It builds context around the data that we have.
A knowledge repository should be:
- Easy to navigate
- Continually improving
- Able to include the context around a particular topic or project
- Discoverable
How to build a knowledge repository
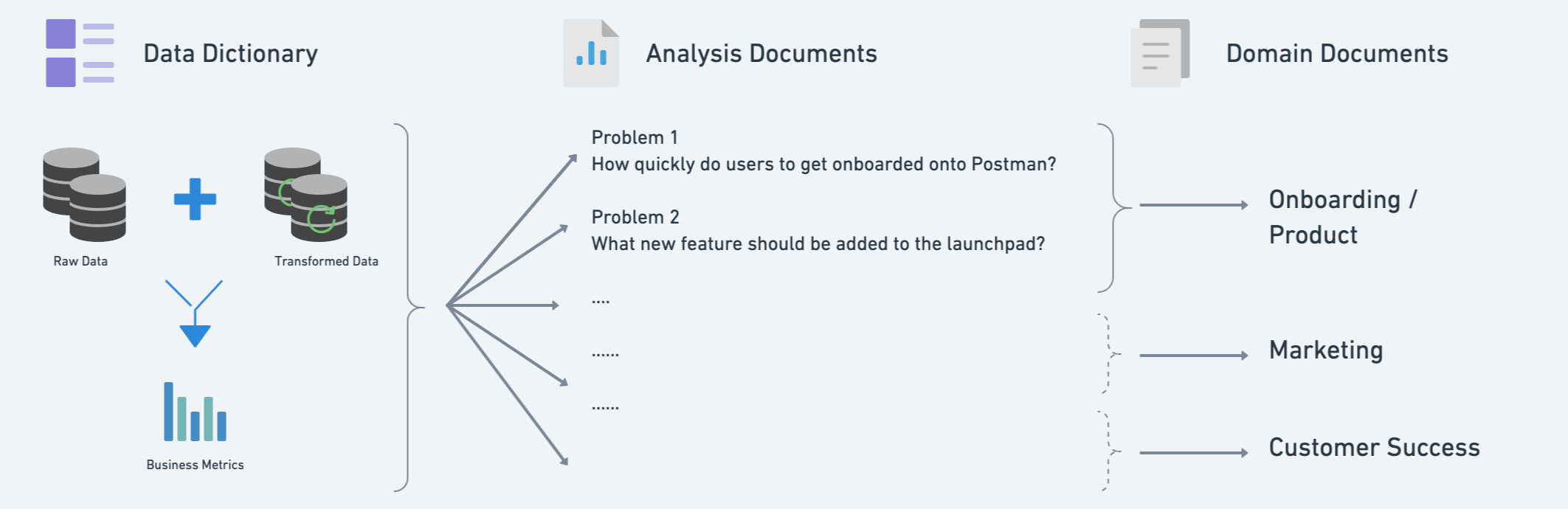
To build a knowledge repository for the Postman data team, we started with a data dictionary, which was especially helpful when we were a small team with relatively fewer data consumers. But the data dictionary only answers the “What” piece of the puzzle. We also needed more business context around it to make it consumable.
Let’s look at a hypothetical scenario in which, as a member of the data analytics and science sub-team within the data team, we are trying to prove a hypothesis or answer an important analytical question. We start with an analysis document template. This template makes it easy for us to write without having to think about the structure of the documentation. It also makes it easy to consume because it’s presented in a predictable format. This document evolves during the tenure of analysis and often includes references:
- Technical implementation
- Data used
- Actions implemented based on the conclusion reached by the analysis
The analysis document helps answer what data was used to solve a particular problem statement and why that data was used the way it was used. It picks up from where the data dictionary left off and builds a complete journey of data from its definition to its actual use case.
The above definitions of a data dictionary and analysis document give us a good way of knowing what data we have and how we have used it in the past to solve problems. This sets a precedence for the new members of the team as well as the organization on how our data can be put to work.
Next, let’s address the need for data navigation and discoverability. One of the things we do is organize each and every document into pre-decided categories. One document can have multiple categories depending on its use case. At Postman, we use “tags” to categorize each and every document that we write into some pre-decided categories (i.e. “onboarding,” “analysis,” “reference,” “how-tos”). We categorize every document with the following:
- The business/product domain of the problem it is solving (growth, collaboration, onboarding, churn, etc.)
- The entities being used (users, tickets, customers, Salesforce, etc.)
- Data source used
Business/product domains can be decided based on the team whose problem you are solving, so that all the analysis-related documents for a particular domain are searchable in the same category. This way the consumer knows which data sources to use if they want to answer an analytical question for a particular domain. They can also see which entities were being used in solving for this domain by the entity category that we have used.
Here’s how the knowledge repository components we’ve described thus far can come together:
To consolidate all of this, we created an awesome overview page of our knowledge repository, which serves as a helpful guide for both internal and external team members. The overview page is broken into three sections:
- “Why” section: lists all the documents related to the analysis for different domains.
- “What” section: lists all the documents related to the business definition being used across different domains, data dictionary, and references.
- “How” section: lists all the documents related to onboarding, quick tips, FAQs, tutorials, and technical implementations.
For anyone new, within or outside the data team, an overview page is a great starting point to explore what kind of data analysis and modeling we have done, what impact it had, and how we executed it.
Conclusion
In the preceding section, we took a bottom-top approach to explain our data team’s knowledge repository structure. You can start with the data dictionary and incrementally make improvements to complete your knowledge repository. Here’s the structure for a top-down approach:
- Have an overview page of your knowledge repository: It should be neatly organized into different sections based on the type of people you are expecting to navigate your knowledge repository.
- Document everything and categorize each document into pre-decided categories: These categories should span different attributes, such as business/product domain (for which you are solving the problem), entities used, and the type of document itself (onboarding, analysis, etc.).
- Have templates for each kind of document: These reduce the mental load and time spent to create and consume those documents.
- Build a data dictionary that is consumable and scalable: This eases collaboration and creates consistency.
Here’s a visual example of the overall structure of our knowledge repository:
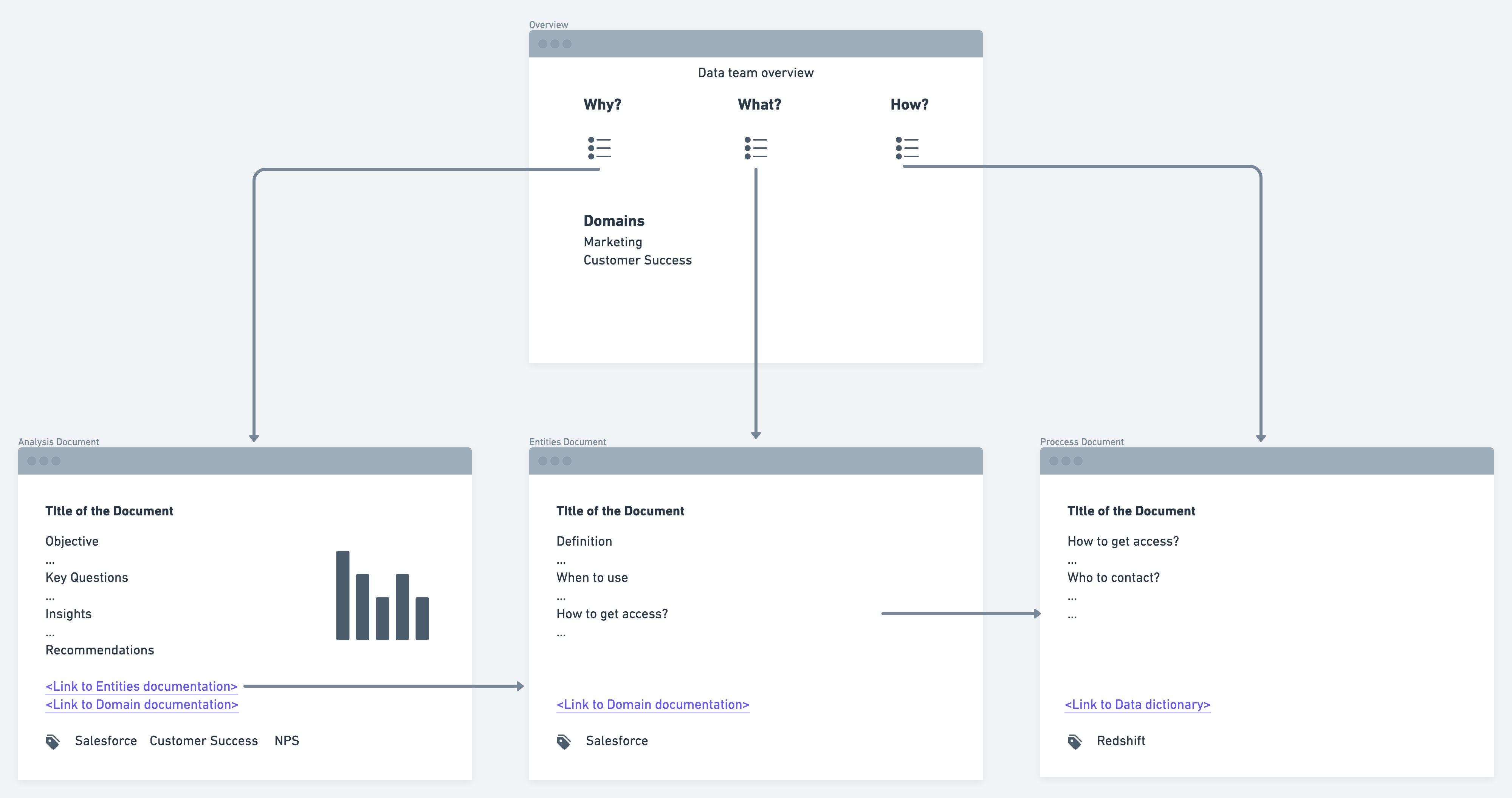
You can implement this framework using any number of tools. For example, we use Atlassian Confluence to maintain the knowledge repository for our data team.
In summary, a highly consumable knowledge repository helps the Postman data team:
- Onboard new members to the data team more quickly and make our work more reproducible.
- Make the data analyses and relevant data sources more discoverable.
- Scale sub-linearly with the organization’s growth.
- Establish a higher standard of data analysis and modeling within the organization.
Even though we’ve effectively adopted this format at Postman, we are continuously improving upon it and coming up with new ways of building our knowledge repository. A few things to consider before building your own knowledge repository: This approach is not full-proof and requires some manual effort to initially organize. It works well in a small to medium-sized organization, but as your organization grows and the appetite for data increases across teams, be open to making modifications in order to maintain your knowledge repository.
Does this topic interest you? If so, you might also be interested in working at Postman. Learn about joining the Postman team here.
